4.1 存储器的层次结构
1.计算机的存储层次:最高层为CPU寄存器,中间为主存,最底层是辅存。
2.根据功能划分:寄存器、高速缓存、主存储器、磁盘缓存、固定磁盘、可移动存储介质等6层。
寄存器、高速缓存、主存储器和磁盘缓存均属于操作系统存储管理的管辖范畴,掉电后存储的信息不存在;低层的固定磁盘和可移动存储介质则属于设备管理的管辖范畴,存储的信息将被长期保存。
4.2 程序的装入和链接
1.程序装入内存的步骤:
- 编译,由编译程序对用户源程序进行编译,形成若干个目标模块;
- 链接,由链接程序将编译后形成的一组目标模块以及它们所需要的库函数链接在一起,形成一个完整的装入模块;
- 装入,由装入程序将装入模块装入内存:构造PCB,形成进程,开始运行。
2.物理地址(绝对地址、实地址):内存中存储单元的地址。物理地址可直接寻址被执行。
3.逻辑地址(相对地址、虚地址):用户的程序经过汇编或编译后形成目标代码,目标代码中的指令地址是相对地址。不能用逻辑地址在内存中读取信息0。
4.绝对装入方式:一般首地址为0,其余指令中的地址都相对于首地址来编址。
5.可重定位装入方式:逻辑地址->重定位->物理地址
6.动态运行时的装入方式:更适合部分装入。
- 装入完成后,程序作为整体连续装在一块内存中,记录下基地址即可。
- 程序离散装入在不同内存位置的,需记录下多个偏移用的基地址。
- 动态重定向的这些被记录的基地址不一定固定不变,可能会根据内存使用情况变化更新。
4.3 连续分配存储管理方式
1.要解决的问题:
- 寻找足够的存储空间
- 地址映射问题
2.程序员了解的是相对地址,PCB中储存的是映射关系,得到逻辑地址。
3.连续分配方式:
- 单一连续分配
- 固定分区分配
- 动态分区分配
- 动态可重定位分区分配
4.单一连续分配:
内存分为系统区和用户区两部分:系统区仅提供给OS使用,通常放在内存的低址部分;用户内存区中,仅装有一道用户程序,即整个内存的用户空间都由该程序独占。
5.固定分区分配:
- 用户空间划分为若干个固定大小的分区,每个分区分配给一个程序,操作系统占一个分区。
- 划分为几个分区,便只允许几道作业并发。
5_1 固定分区分配的具体实现:
- 如何划分分区大小
- 需要的数据结构
- 分配回收操作
5_2 划分分区的方法:
- 分区大小相等(所有的内存分区大小相等),只适用于多个相同的程序的并发执行,缺乏灵活性。
- 分区大小不相等。
5_3 内存分配:
- 将分区按其大小进行排队,并为之建立一张分区使用表。
- 可以将分区表划分为两个表格:分区使用表、空闲分区表
- 空闲分区表的排序规则:按空间大小排序、按地址高低排序
- 过程:检索空闲分区表,找出一个满足要求且尚未分配的分区,分配给请求程序;若未找到大小足够的分区,则拒绝为该用户程序分配内存。
- 缺点:
①内碎片(已分配未使用),产生存储空间的浪费;
②分区总数固定,限制并发执行的程序数目。
6.动态分区分配:需要多少划多少
6_1 具体实现:
- 分区分配中的数据结构:空闲分区表(从1项->n项)、空闲分区链
- 分区分配操作
- 分区分配算法
6_2 优缺点
优点:并发进程数没有固定数的限制,不产生内碎片。
缺点:外碎片(使用后不可再使用),空闲大小不够程序运行。
6_3 分配内存
系统应利用某种分配算法,从空闲分区链(表)中找到所需大小的分区。若m.size-u.size≤size,说明多余部分太小,可不再切割,将整个分区分配给请求者,否则,便从该分区中按请求的大小划分出一块内存空间分配出去,余下的部分仍留在空闲分区链(表)中。然后,将分配区的首地址返给调用者。
6_4 回收内存
- 回收区与插入点的前一个空闲分区F1相邻接。此时应将回收区和插入点的前一分区合并,只需修改其前一分区F1的大小;
- 回收分区与插入点的后一空闲分区F2相邻接。此时也可将两分区合并,形成新的空闲分区。用回收区的首址作为新空闲区的首址,大小为两者之和。
- 回收区同时与插入点的前、后两个分区邻接。此时将三个分区合并。
- 回收区既不与F1邻接,又不与F2邻接。为回收区单独建立一个新表项。
6_4 动态分区分配算法:
6_4_1 首次适应(FF)算法:空闲分区链以地址递增的次序链接。
- 从链首开始顺序查找,直至找到一个大小能满足要求的空闲分区为止。然后按照作业大小,从该分区中划出一块内存空间,分配给请求者,余下的空闲分区仍留在空闲链中。若从链首直至链尾都不能找到应该能满足要求的分区,内存分配失败。
- 优点:优先利用内存中低址部分的空闲分区,从而保留了高址部分的大空闲区。
- 缺点:
①低址部分不断被划分,会留下许多难以利用的、很小的空闲分区,称为碎片。
②每次查找又都是从低址部分开始的,增加查找可用空间分区时的开销。
6_4_2 循环首次适应(NF)算法:空闲分区按地址排序
- 循环首次适应算法在为进程分配内存空间时,从上次找到的空闲分区的下一个空闲分区开始查找,直至找到一个能满足要求的分区的空闲分区,从中划出一块与请求大小相等的内存空间分配给作业。
- 优点:空间分区分布得更均匀,减少了查找的开销。
- 缺点:缺乏大的空闲分区。
6_4_3 最佳适应(BF)算法:所有的空闲分区按其容量以从小到大的顺序形成一空闲分区链。
- 把能满足要求、又是最小的空闲分区分配给作业,避免“大材小用”。从表或链首开始,找到的第一个满足的分区就分配。
- 缺点:每次分配后所切割下来的剩余部分总是最小的,留下许多难以利用的碎片(外碎片)。
6_4_4 最坏适应(WF)算法:从大到小排序
- 挑选一个最大的空闲区,从中分割一部分存储空间给作业使用,以至于存储器中缺乏大的空闲分区。
- 剩下的空闲区不至于太小,但会出现缺乏较大的空闲分区的情况。
6_4_5 快速适应算法:将空闲分区根据其容量大小进行分类
- 相同容量的分区,设立一个空闲分区链表,系统中存在多个空闲分区链表。
- 空闲分区的分类是根据进程常用的空间大小进行划分的。
- 分配过程:根据进程的长度,寻找能容纳它的最小空闲区链表,取下第一块进行分配。
- 缺点:链表指针过多,以空间换时间。
7.动态可重定位分区分配——有紧凑功能的动态分区分配
- 通过移动内存中作业的位置,把原来多个分散的小分区拼接成一个大分区的方法,称为“拼接”或“紧凑”。
- 地址变换过程(相对地址与重定位寄存器中的地址相加)是在程序执行期间,随着对每条指令或数据的访问自动进行的,故称为动态重定位。
- 动态重定位分区分配算法与动态分区分配算法基本相同,差别在于增加了紧凑的功能。
8.伙伴系统
- 无论已分配还是空闲分区,大小都为2的k次幂(k为整数,1≤k≤m)。
- 通常整个可分配空间大小为2的m次方,也就是最大分区的大小。
- 系统开始运行的时候,整个内存区是一个大小为2的m次方的空闲分区。随着系统运行,内存被不断划分,形成若干不连续的空闲分区。对每一类具有相同大小的空闲分区设置一双向链表。不同大小的空闲分区形成了k个空闲分区链表。
- 进程申请长度为n的存储空间时,计算2的(i-1)次方≤n≤2的i次方,则找空闲分区大小为2的i次方的链表。若2的i次方大小的链表没有,则找2的(i+1)次方的链表。找到的分区对半划分后,一半用于分配,一半链接到较小一级的链表里去。若再没有,则再找2的(i+2)次方的链表,以此类推,直至找到或找遍。
- 一次分配和回收都可能对应多次的划分和合并。
- 怎么找到合适的链?——哈希算法
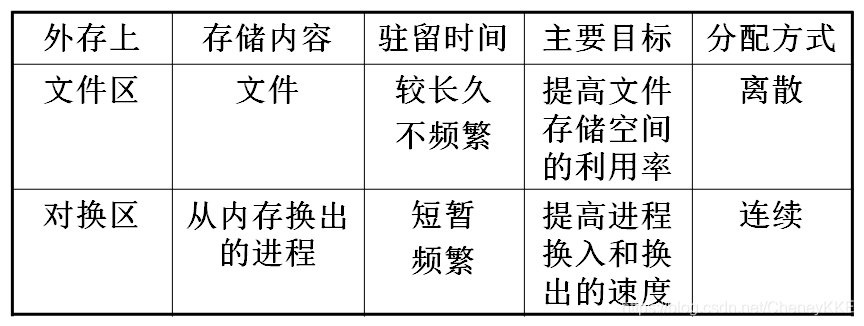
4.4 对换
1.对换:把内存中暂时不能运行、或暂时不用的程序和数据调到外存上,以腾出足够的内存,再把已具备运行条件的进程和进程所需要的程序和数据,调入内存。
2.对换的分类(按对换单位分类):
- 整体对换(或进程对换):以整个进程为单位(连续分配)
- 页面对换或分段对换:以页或段为单位(离散分配)
3.实现进程对换,系统必须具备的功能:
- 对换空间的管理
- 进程的换出、换入操作