github
https://github.com/HaHaHaHaHaGe/mynetstack
简介
数据包的提取其实原理并不复杂,就像拼积木一样,见下图:

这些字是我随便打出来的,现在这串字符串中,我说包含了三个数据包,需要提取出来
规则如下:
碰到数字:1234 代表后面的将是需要提取的数据
具体提取几个呢,提取1234后面那个数字的个数
如:12345关怀和分化.
1234是开头
5是提取的个数
后面的5个字就是待提取的数据
1234叫做 包头
5叫做 数据长度
这是最简单的情况,但是实际应用中会有些复杂,
首先我们要知道,在传输数据的时候,任何数据都可能被传输
也就是说我现在定义:若遇到1234则代表后面的将是需要提取的数据
但若传输的数据中恰好包含1234会怎么样呢?

就像这个样子,处理肯定会出现错误,所以我们需要对原始数据进行一下转化比如在每个数据面前增加一个符号’/’
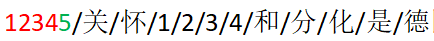
其次我们知道在实际应用中,难免会有干扰
有干扰就意味着很可能数据传输出现错误
原本发送的是1110接受端接收到的可能就变成1100了
所以在此基础上还需要增加校验,也就是说有专门的一个数来表示这段数据是不是正确的
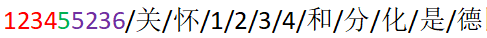
到现在为止,一个比较可靠的基本数据包结构就完成了
当然在实际应用中我们不会直接使用字符去传输数据,更不会使用字符’/'去分割数据,这样做太浪费资源了
那么我们会怎么做呢?
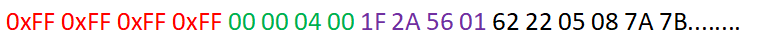
这是截取开头的一段真实数据包,首先0xff 0xff 0xff 0xff是数据包头,00 00 04 00是数据长度 ,1F 2A 56 01 是CRC32 校验,对包头、数据长度、数据进行校验,后面的就是数据了。
但是不知有没有发现’/'是怎么实现的呢?
实际上后面的所有的数据都是已经进行过处理的,它们的第8位恒为零,这就保证永远不可能出现0xFF,哪怕由于干扰出现了0xFF 那么连续出现四个0xFF的概率微乎其微,但是这种做法也会增加额外的传输负担,比如若我想要传输56个字节,那么由于第八位已经被设置位固定0 所以我只能往后移一位,去占用下一个字节的空间。以此类推,到最后,真正传输的字节就会变成:
(56*8)/7 = 64
最终我们原始数据从56字节,变成了64字节
函数说明
有关数据包提取的文件在\mynetstack\Source\BasicDataStream\inc 与\mynetstack\Source\BasicDataStream\src 中
名称为 packeg_taken.c 与 packeg_taken.h
注:程序还在更新,以GITHUB为准
/*
从拼接的两段数组中寻找正确的数据包
数据包格式:
-------------------------------------------------------
0-3 4-7 8-11 12-N
包头 数据长 CRC32 数据
-------------------------------------------------------
入口参数:
src1:第一个数组
src2:第二个数组
len1:第一个数组大小
len2:第二个数组大小
rdata_1:返回数据的第一指针
rdata_2:返回数据的第二指针
rlen_1:返回数据第一指针指向的数据段长度
rlen_2:返回数据第二指针指向的数据段长度
stop_ptr:返回停止查找的位置(被阻断查找的原因包括:成功找到数据包,找到损坏数据包,找到截断数据包)
返回值:
是否找到数据包
*/
u8 search_packeg(u8*src1, u8*src2, u32 len1, u32 len2, u8**rdata_1, u8**rdata_2, u32*rlen_1, u32*rlen_2, u8** stop_ptr);
/*
从拼接的两段数组中寻找正确的数据包并进行7bit->8bit转化
重新分配内存并保存数据
src1:第一个数组
src2:第二个数组
len1:第一个数组大小
len2:第二个数组大小
返回值:
如果没有正确数据包返回NULL_PTR
否则返回新分配的内存地址(指向转化完毕的数据包)
*/
u8* unpacking(u8* src1, u8* src2, u32 len1, u32 len2);