https://blog.csdn.net/liuchonge/article/details/73610734
https://blog.csdn.net/triplemeng/article/details/78269127
--
https://github.com/triplemeng/hierarchical-attention-model学习如何根据论文、参考别人的代码来实现
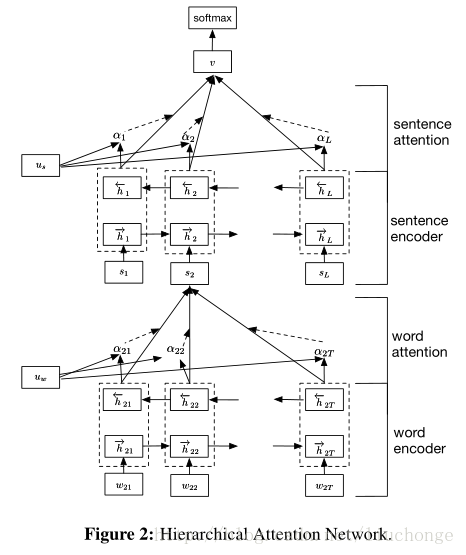
如果没有图中的uwuw(词语级别的context vector)和usus(句子级别的context vector),这个模型也没有什么特殊的地方。它无非是由word sequence layer和sentence sequence layer组成的一个简单的层级的sequence模型而已。而有了这两个context vector, 我们就可以利用它们产生attention layer, 求出每个词语和每个句子的任务相关程度。
具体做法如下,针对每一个句子,用sequence model, 就是双向的rnn给表达出来,在这里用的是GRU cell。每个词语对应的hidden vector的输出经过变换(affine+tanh)之后和uwuw相互作用(点积),结果就是每个词语的权重。加权以后就可以产生整个sentence的表示。从高一级的层面来看(hierarchical的由来),每个document有L个句子组成,那么这L个句子就可以连接成另一个sequence model, 同样是双向GRU cell的双向rnn,同样的对输出层进行变换后和usus相互作用,产生每个句子的权重,加权以后我们就产生了对整个document的表示。最后用softmax就可以产生对分类的预测。
每次的“提问”,都是由uwuw和usus来实现的,它们用来找到高权重的词语和句子。
代码部分 --------