文章目录
环境配置
cdh 5.15.0
cm 5.15.0
os centos 7.2
背景
yarn container 默认不支持对cpu进行资源隔离,一些计算密集型任务甚至可能占满NM节点的cpu资源,从而影响到其他任务的执行效率。
- spark streaming 出现消费延时
- 一些调度任务运行时间波动较大
例如申请的1个vcore,实际上又启动了多线程,还有GC线程等都会造成资源使用不可控。

目标
- 限制一些计算密集型任务的CPU使用,避免多 Container 运行在同一台机器上,cpu 争用导致的任务运行时间不稳定,流任务消费抖动等情况
- 避免个别 Container CPU 使用过高,造成系统负载过高或者不稳定 / 影响到其他服务的稳定性(例如 DATANODE)
资源隔离
Cgroup & LinuxContainerExecutor
默认情况下,NodeManager 使用 DefaultContainerExecutor 以 NodeManager 启动者的身份来执行启动Container等操作,安全性低且没有任何CPU资源隔离机制。
要达到这种目的,必须要使用 LinuxContainerExecutor,从而以应用提交者的身份创建文件,运行/销毁 Container。允许用户在启动Container后直接将CPU份额和进程ID写入cgroup路径的方式实现CPU资源隔离。
Cgroup 是linux kernel的一个功能,可以资源进行隔离,Yarn中现在支持对cpu/mem/io三种资源进行隔离。
CPU 资源隔离
NodeManager 通过修改 cgroup 的 cpu.cfs_period_us,cpu.cfs_quota_us,cpu.shares 三个文件实现对 cpu 的资源限制,还可以进一步细分为 soft limit 和 hard limit 两种方式。
cpu.cfs_period_us- 时间周期,默认为1000*1000微秒(1s),在yarn中按该时间来划分一次cpu的时间片调度周期cpu.cfs_quota_us- 单位时间内可用的 cpu 时间,默认无限制(-1)cpu.shares- 用于分配cpu执行的权重,默认为 1024
NodeManager 资源相关配置
yarn.nodemanager.resource.cpu-vcoresnodemanager 可以分配的 vcore 数量。yarn.nodemanager.resource.percentage-physical-cpu-limitnm 所有Container cpu 使用占物理机cpu资源的比例,通过降低nm的cpu.cfs_period_us实现。
nm 所在的物理机 core 数量为 40,cpu limit 设置为 90%,则 nm 上所有 container 的综合 cpu 使用不会超过 3600%
hard limit
在 yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage 设置为 true 时生效。通过改变cpu.cfs_quota_us和cpu.cfs_period_us文件控制cpu资源使用的上限。
严格按照任务初始分配的cpu进行限制,即使还有空闲的CPU资源也不会占用。
core = cpu.cfs_quota_us/cpu.cfs_period_us
yarn 是通过降低 cpu.cfs_period_us的值来实现控制,cpu.cfs_quota_us 固定为1000000。
计算公式
-
containerVCores 单个 container 申请的core
-
yarnProcessors nodemanager 所在节点的物理
core * yarn.nodemanager.resource.percentage-physical-cpu-limit -
nodeVcores nodemanager 设置的 VCore 数量
containerCPU = (containerVCores * yarnProcessors) / (float) nodeVCores
例如一台4核的虚拟机,VCore 设置为8,启动一个vcore 为 1 的 Container,在 yarn.nodemanager.resource.percentage-physical-cpu-limit 为 100的情况下,使用率不会超过50%
如果将yarn.nodemanager.resource.percentage-physical-cpu-limit设置为90,则每个Container的cpu使用率不会超过45%
soft limit
在 yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage 设置为 false 时生效,通过 cpu.shares 文件控制资源使用,该参数只能控制资源使用的下限。
按比例对资源进行限制,在这种模式下,允许 Container 使用额外的空闲CPU资源。
计算公式
有 VCore 分别为 1,1,2 的三个 Container,则 cpu.shares 会被设置为 1024 1024 2048,那么他们可以使用的cpu时间比率为1 : 1 : 2
启动两个应用,每个应用的 Container 的 VCore 都为1,则每个executor都使用100%

启动两个应用,一个应用Container VCore为1,一个应用 Container VCore为2,前者分到的cpu 资源为66%,后者为132%

启动两个应用,一个应用Container vcore为1,一个应用 Container vcore为3,前者分到的cpu 资源为50%,后者为150%

TIPS: 由此可见,任务的可用资源会随着不同的机器负载发生变化
两种方式的一些对比
PCore 为8的机器,NM VCore 设置为6,p-limit 设置为50。
| scenario | soft limit | hard limit |
|---|---|---|
| 启动 4个 Container,每个 Container 的 VCore 为1 | 100%, 100% | 66.7%, 66,7% |
| 启动 2个 Container,其中一个VCore为2,一个VCore为1 | 200%, 100% | 133%, 66.7% |
| 启动 4个 Container,其中两个VCore为2,两个VCore为1 | 133%, 66.7% | 133%, 66.7% |
总结
根据不同场景选择限制模式
| 一些对比 | soft limit | hard limit |
|---|---|---|
| 优点 | nm资源使用率高 | 资源限制更严格,运行时间更可控 |
| 缺点 | 根据机器上运行的Container资源申请情况,资源分配动态变化,可能造成运行时间不稳定 | 低负载场景下不能充分利用空闲的nm资源 |
| 控制方式 | 控制Container使用的cpu下限 | 控制Container使用的cpu上限 |
| 使用场景 | 对任务运行时间不敏感 | 集群上运行多种类型的任务,对SLA有一定要求 |
开启Cgroup后带来的变化
- 计算密集型任务运行时间相比之前可能会变长,需要修改相关配置
- driver 默认使用1c,如果是 cluster 模式,driver 会运行在container中,所以也会受到限制。driver 负载比较高的任务(例如读取了大量的分区或者task数量比较多),速度会有所下降,因此需要适当提高
spark.driver.cores值。 - 大多数任务运行时间较之前稳定。
example
同一个任务多次运行,在开启 cgroup 后稳定性有很大的提升,不过速度略有下降,可以通过增加资源的方式解决。
配置 CGroup 前:
配置 CGroup 后:
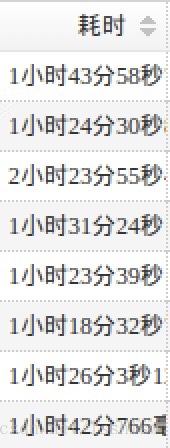
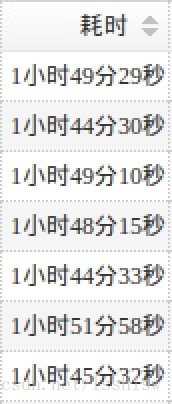
对一段时间范围内的任务进行统计(每日10K+不同类型的spark任务):

相关配置
| 参数 | 属性 | 描述 |
|---|---|---|
| yarn.nodemanager.container-executor.class | org.apache.hadoop.yarn.server .nodemanager.LinuxContainerExecutor |
Yarn 是否使用 Linux Container Executor。 |
| yarn.nodemanager.linux-container-executor.resources-handler.class | org.apache.hadoop.yarn.server .nodemanager.util.CgroupsLCEResourcesHandler |
YARN 是否根据容器创建 cgroup,从而隔离容器的 CPU 使用情况 |
| yarn.nodemanager.linux-container-executor.cgroups.hierarchy | /hadoop-yarn | yarn 使用的 cgroup 组,默认为/hadoop-yarn,一般不作修改 |
| yarn.nodemanager.linux-container-executor.cgroups.mount | true | 是否自动挂载cgroup |
| yarn.nodemanager.linux-container-executor.cgroups.mount-path | /sys/fs/cgroup | cgroup 挂载目录,centos7 为/sys/fs/cgroup,centos6 为 /cgroup |
| yarn.nodemanager.linux-container-executor.group | yarn | 容器执行组,一般无需设置 |
| yarn.nodemanager.resource.percentage-physical-cpu-limit | 90 | 配置nodemanager使用多少物理cpu资源,比如24核服务器配置90的话,只能使用21.6核 |
| yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage | true | 是否启用严格资源限制,按任务申请的CPU数量控制 / 按core的比率限制 |
| yarn.nodemanager.linux-container-executor.nonsecure-mode.local-user | nobody | 使用 Linux-container-executor 时,运行容器的 UNIX 用户,一般不用更改 |
相关代码
CgroupsLCEResourcesHandler.setupLimits
public void setupLimits(ContainerId containerId,
Resource containerResource) throws IOException {
String containerName = containerId.toString();
if (isCpuWeightEnabled()) {
int containerVCores = containerResource.getVirtualCores();
createCgroup(CONTROLLER_CPU, containerName);
int cpuShares = CPU_DEFAULT_WEIGHT * containerVCores;
// absolute minimum of 10 shares for zero CPU containers
cpuShares = Math.max(cpuShares, 10);
updateCgroup(CONTROLLER_CPU, containerName, "shares",
String.valueOf(cpuShares));
if (strictResourceUsageMode) {
int nodeVCores =
conf.getInt(YarnConfiguration.NM_VCORES,
YarnConfiguration.DEFAULT_NM_VCORES);
if (nodeVCores != containerVCores) {
// yarnProcessors 为物理机总线程数 * cpu_limit
float containerCPU =
(containerVCores * yarnProcessors) / (float) nodeVCores;
int[] limits = getOverallLimits(containerCPU);
updateCgroup(CONTROLLER_CPU, containerName, CPU_PERIOD_US,
String.valueOf(limits[0]));
updateCgroup(CONTROLLER_CPU, containerName, CPU_QUOTA_US,
String.valueOf(limits[1]));
}
}
}
}