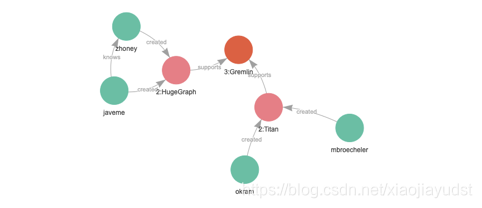
- 看下图箭头指向,可以得出的信息:zhoney knows javeme 两个人都created Hugegraph->supports Gremlin 这是一条到达最底层的路径。Okram 与 mbroecheler 不认识,但都created Titan->supports Gremlin这个又是另外一条路经。另外:3:Gremlin、2:Titan、2:Hugegraph 分别代表什么意思呢?这其实是从外向内开始数的:最外层为(1:xxx)这一般不写;往里边数第二层为(2:xxx)这里分别对应着图中的 HugeGraph、Titan;然后是第三层(3:xxx)图中对应着 Gremlin。当然,这些数字是自动赋值的。你需要看清楚知道,才能查到自己想要的。学习的时候见到了很多(4:Gremlin)这样的示例,查询的结果肯定是不对的注意区分。
- 示例:
g.V().hasLabel('person').range(0, -1)不加限制地查询所有类型为’person’的顶点 - 示例:
g.V().hasLabel('person').range(2, 5)查询类型为’person’的顶点中的第2个到第5个 python 学多了会混淆! - 示例:
g.V().hasLabel(‘software').has('name','HugeGraph').both().path()“HugeGraph”顶点到与其有直接关联的顶点的路径(仅包含顶点)如果想要同时获得经过的边的信息呢?可以用bothE().otherV()替换both()g.V().hasLabel('software').has('name','HugeGraph').bothE().otherV().path()// “HugeGraph”顶点到与其有直接关联的顶点的路径(包含顶点和边) - until()放在repeat()之前或之后的顺序是会影响逻辑的,放前面表示先判断再执行,放后面表示先执行后判断。对比如下两个语句的执行结果:
g.V('okram').repeat(out()).until(hasLabel('person')).path()
g.V(‘okram').until(hasLabel('person')).repeat(out()).path() - 关于排序:
order().by(incr): 将结果以升序输出,这也是默认的排序方式;
order().by(decr): 将结果以降序输出;
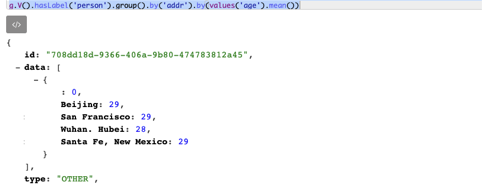
order().by(shuffle): 将结果以随机序输出,每次执行结果顺序都可能不一样 - 获得各个地方人们的平均年龄
// 根据地域分组,并得到各个组的平均年龄
g.V().hasLabel('person').group().by('addr').by(values('age').mean())
- 统计顶点的边数量的分布情况
// 拥有相同数量边的顶点作为一组
// 并获取每一组的顶点数量
// 结果相当于:拥有m条边的顶点有n个
g.V().groupCount().by(bothE().count())
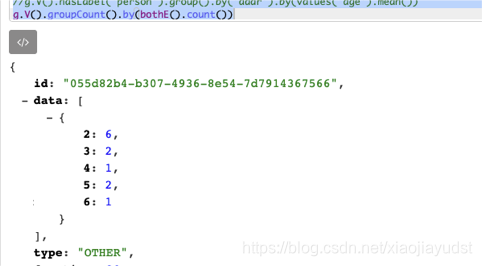 6条边的顶点一个:Gremlin 2条边的顶点六个
6条边的顶点一个:Gremlin 2条边的顶点六个 - // 先获取顶点“2:HugeGraph”的入“created”顶点,再将每个顶点转化为出边(一条):
g.V(‘2:HugeGraph').in('created').map(outE())
注意:顶点“javeme”其实是有三条边的,但是这里只打印出了一条。因为mapStep是一对一的转换,要想获取所有的边可以使用flatMap。 - // 先获取顶点“2:HugeGraph”的入“created”顶点,再将每个顶点转化为出边(多条):
g.V(‘2:HugeGraph').in('created').flatMap(outE()) - 另外值得一提的是:
https://blog.csdn.net/javeme/article/details/82627396 这里的out、in、 both、other一定要特别特别特别的熟练。熟练运用这些做数据挖掘很方便如虎添翼。特别是综合运用里的那部分要熟练掌握:多度查询,查合作关系,关联关系等等。
HugeGraph图数据库你可能不知道的小秘密
猜你喜欢
转载自blog.csdn.net/xiaojiayudst/article/details/84666902
今日推荐
周排行