源代码编译之后,分为两个状态:存储时、运行时。
存储时
在linux环境下,可以对编译好的二进制文件执行size指令可以获取该二进制可执行文件的结构情况:
# size test.out
| 代码区 | 全局初始化数据区/静态数据区 | 未初始化数据区 | 十进制总合 | 十六进制总合 | 文件名 |
|---|---|---|---|---|---|
| text | data | bss | dec | hex | filename |
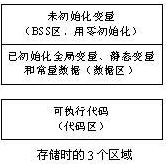
未运行前,没有调入到内存时,分为三个部分:代码区(text)、数据区(data)、未初始化数据区(bss)。
(1) 代码区(text)
存放CPU可执行的机器指令,由于程序被经常使用,防止其被意外修改,代码区通常是只读的。
(2) 全局初始化数据区/静态数据区(data)
存放被初始化的全局变量、静态变量(全局静态变量和局部静态变量)、常量数据(如字符串常量)。
(3) 未初始化数据区(BSS)
存放未初始化的全局变量,BSS这个叫法是根据早期的汇编运算符而来的,这个汇编运算符标志着一个块的开始。BSS区的数据在程序开始执行之前被内核初始化为0或空指针(NULL)。
运行时
一个正在运行的C程序,占用的内存分为5个区域:代码区、初始化数据区/静态数据区、未初始化数据区、堆区、栈区。

(1) 代码区(text)
代码区指令根据程序设计流程依次执行,对于顺序指令,则只会执行一次,如果反复,则需使用跳转指令,如果进行递归,则需借助栈来实现。
代码区包括操作码和要操作的对象(或对象的地址引用),如果是立即数(即具体的数值,如2),将直接包含在代码中;如果是局部数据,将在栈中分配空间,然后引用该数据的地址;如果是BSS区和数据区,在代码中同样引用该数据的地址。
(2) 全局初始化数据区/静态数据区(data)
只初始化一次。上面已经说过,在程序编译时,该区域已经被分配好了,这块内存在程序的整个运行期间都存在,当程序结束时,才会被释放。
(3)未初始化数据 区(BSS)
在运行时改变其值。
(4)栈区(stack)
存放函数的参数值和局部变量,由编译器自动分配释放,其操作方式类似于数据结构的栈。其特点是不需要程序员去考虑内存管理的问题,很方便;同时栈的容量很有限,在Linux系统中,栈的容量只有8M,并且当相应的范围结束时(如函数),局部变量就不能再使用。
(5)堆区(heap)
有些操作对象只有在程序运行时才能确定,这样编译器在编译时就无法为他们预先分配空间,只有程序运行时才分配,这就是动态内存分配。堆区就是用于动态内存分配(如malloc的动态内存分配),堆在内存中位于bss区和栈区之间,一般由程序员申请和释放。
之所以分配如此多的区域,主要是因为:
一个进程在运行时,代码是根据流程依次执行的,代码只需访问一次,当然跳转或递归时代码会被执行多次,而数据一般都需要访问多次,因此单独开辟空间以便访问和节约空间。
int a = 0; //全局初始化区
char *p1; //全局未初始化区
int main()
{
int b; // 栈
char s[] = "abc"; //栈
char *p2; //栈
char *p3 = "123456"; //123456\0在常量区,而p3在栈上
static int c =0; //全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20); //分配得来得10和20字节的区域就在堆区
strcpy(p1, "123456"); //123456\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
return 0;
}