1、概率密度估计方法
概率密度估计方法用于估计一组数据集的概率密度分布,分为参数估计方法和非参数估计方法。
参数估计方法
假定样本集符合某一概率分布,然后根据样本集拟合该分布中的参数,例如:似然估计,混合高斯等,由于参数估计方法中需要加入主观的先验知识,往往很难拟合出与真实分布的模型;
非参数估计法
非参数估计并不加入任何先验知识,而是根据数据本身的特点、性质来拟合分布,这样能比参数估计方法得出更好的模型。核密度估计就是非参数估计中的一种。
2、核密度估计KDE(Kernel Density Estimation)
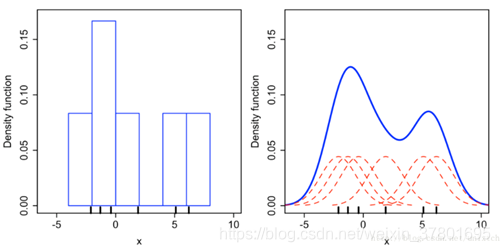
由Rosenblatt (1955)和Emanuel Parzen(1962)提出,又名Parzen窗(Parzen window),设数据集包含N个样本,对这N个样本进行核函数拟合,将这N个概率密度函数进行叠加便得到了整个样本集的概率密度函数。拟合叠加过程如下图所示。
核密度估计概率密度函数为
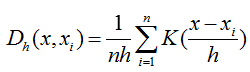
高斯函数为核函数的概率密度函数如下式:
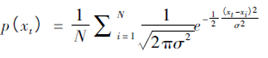
带宽h的选择:当选择极小的带宽值,每个点就是一个峰值,那么每个点就是一类,如果选择大的带宽值,那么所有的数据只有一个峰值,只有一类。带宽选择没有对错之分,可以基于分析的需求进行选择。也可以通过可视化观察估计结果和数据分布的匹配度。
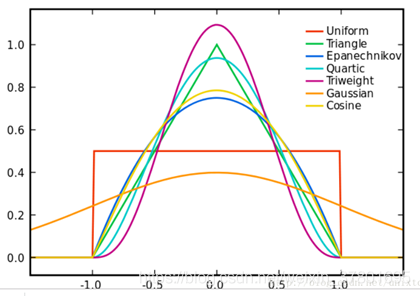
核函数的种类如下图所示。
2、高斯混合模型GMM(Gaussian Mixture Model)
高斯混合模型的表达式如下式,
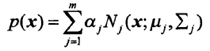
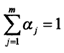
D维多元高斯分布如下式。
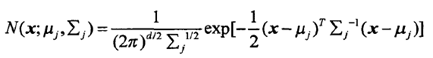
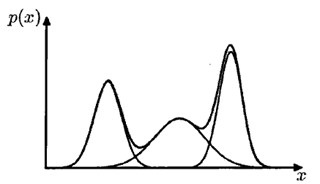
高斯混合模型的示意图如下
3、核密度估计与高斯混合模型对比
核密度估计采用单一模型,导致采样样本中存在的噪声使最终结果的噪点较多,并且对于细节如轮廓边缘处理过于粗糙。而混合高斯模型对每个像素点建立多个高斯分布,能更精确描述数据特征,但计算量较大,算法复杂。
参考链接
https://blog.csdn.net/liangzuojiayi/article/details/78152180
https://blog.csdn.net/unixtch/article/details/78556499