Hystrix
为什么要学习Hystrix呢?
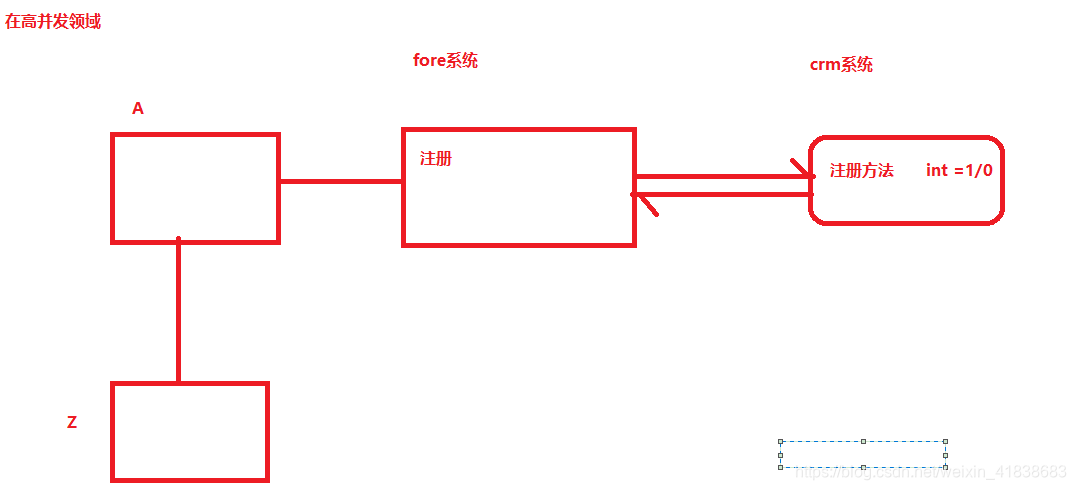
在高并发领域,在分布式系统中,可能因为一个小小的功能扛不住压力,宕机了,导致其他服务也跟随宕机,最终导致整个系统宕机,所以在SpringCloud中采用Hystrix进行处理。
简介
Hystrix,即熔断器。
主页:https://github.com/Netflix/Hystrix/

Hystrix是Netflix开源的一个延迟和容错库,用于隔离访问远程服务、第三方库,防止出现级联失败。

熔断器的工作机制:

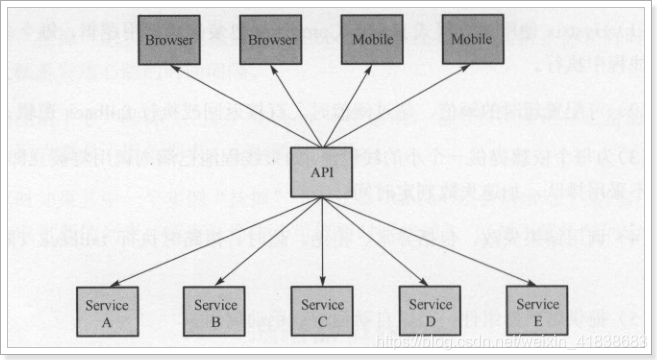
正常工作的情况下,客户端请求调用服务API接口:
当有服务出现异常时,直接进行失败回滚,服务降级处理:
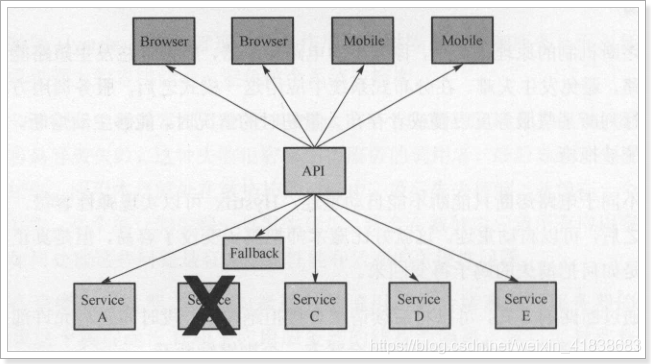
当服务繁忙时,如果服务出现异常,不是粗暴的直接报错,而是返回一个友好的提示,虽然拒绝了用户的访问,但是会返回一个结果。
这就好比去买鱼,平常超市买鱼会额外赠送杀鱼的服务。等到逢年过节,超市繁忙时,可能就不提供杀鱼服务了,这就是服务的降级。
系统特别繁忙时,一些次要服务暂时中断,优先保证主要服务的畅通,一切资源优先让给主要服务来使用,在双十一、618时,京东天猫都会采用这样的策略。
动手实践
引入依赖
首先在user-consumer(服务消费者)中引入Hystix依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
开启熔断

改造消费者
我们改造user-consumer,添加一个用来访问的user服务的DAO,并且声明一个失败时的回滚处理函数:
@Component
public class UserDao {
@Autowired
private RestTemplate restTemplate;
@HystrixCommand(fallbackMethod = "queryUserByIdFallback")
public User queryUserById(Long id){
long begin = System.currentTimeMillis();
String url = "http://user-service/user/" + id;
User user = this.restTemplate.getForObject(url, User.class);
long end = System.currentTimeMillis();
// 记录访问用时:
System.out.println("访问用时:{}", end - begin);
return user;
}
public User queryUserByIdFallback(Long id){
User user = new User();
user.setId(id);
user.setName("用户信息查询出现异常!");
return user;
}
}
@HystrixCommand(fallbackMethod="queryUserByIdFallback"):声明一个失败回滚处理函数queryUserByIdFallback,当queryUserById执行超时(默认是1000毫秒),就会执行fallback函数,返回错误提示。- 为了方便查看熔断的触发时机,我们记录请求访问时间。
在原来的业务逻辑中调用这个DAO:
@Service
public class UserService {
@Autowired
private UserDao userDao;
public List<User> queryUserByIds(List<Long> ids) {
List<User> users = new ArrayList<>();
ids.forEach(id -> {
// 我们测试多次查询,
users.add(this.userDao.queryUserById(id));
});
return users;
}
}
改造服务提供者
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public User queryById(Long id) throws InterruptedException {
// 为了演示超时现象,我们在这里然线程休眠,时间随机 0~2000毫秒
Thread.sleep(new Random().nextInt(2000));
return this.userMapper.selectByPrimaryKey(id);
}
}
启动测试
然后运行并查看日志:
id为9、10、11的访问时间分别是:
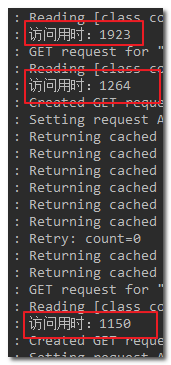
id为12的访问时间:
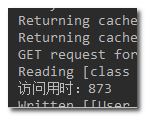
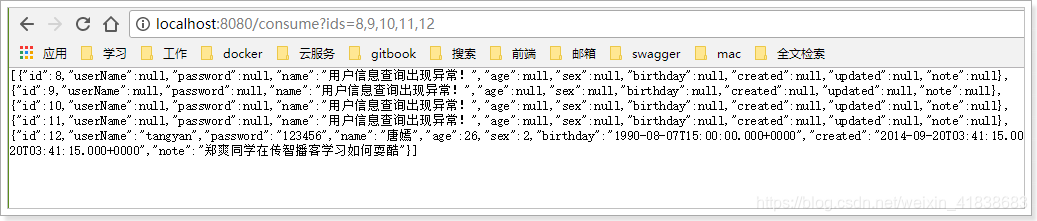
因此,只有12是正常访问,其它都会触发熔断,我们来查看结果:
优化
虽然熔断实现了,但是我们的重试机制似乎没有生效,是这样吗?

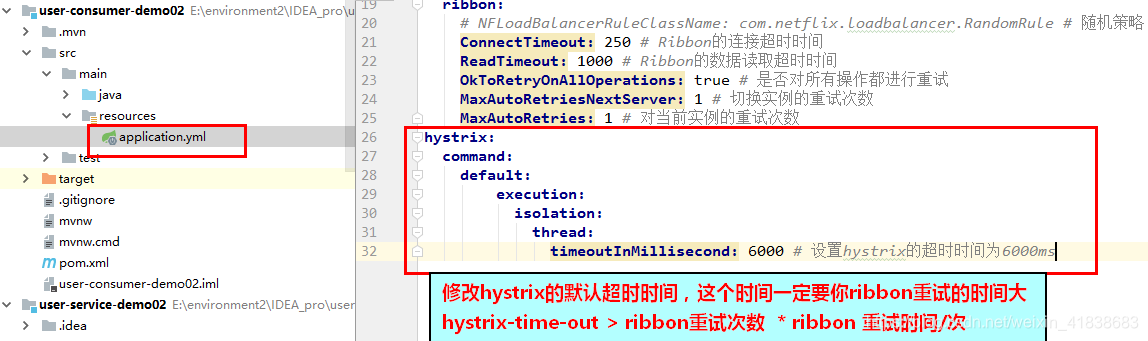
其实这里是因为我们的Ribbon超时时间设置的是1000ms:
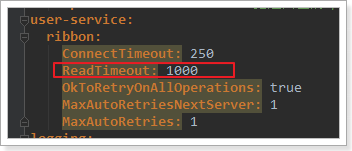
而Hystix的超时时间默认也是1000ms,因此重试机制没有被触发,而是先触发了熔断。

所以,Ribbon的超时时间一定要小于Hystix的超时时间。
我们可以通过hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds来设置Hystrix超时时间。
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 6000 # 设置hystrix的超时时间为6000ms