一.分析
异常值分析是检验数据是否有录入错误以及含有不合常理的数据。忽视异常值的存在是十分危险的,不加剔除地把异常值包括进数据的计算分析过程中,会给结果带来不良影响;重视异常值的出现,分析其产生的原因,常常成为发现问题改进决策的契机。
异常值是指样本中的个别值,其数值明显偏移其余的观测值。异常值也成为离群点,异常值的分析也称为离群点分析。
1.简单统计量分析
可以对变量做一个描述性统计,进而查看那些数据是不合理的。最常用的统量是最大值和最小值,用来判断这个变量的取值是否超出了取值范围。
2 . 3δ原则
经验法则告诉我们,几乎所有的数据与平均数之差都在3个标准差之内,所有异常值被定义为一组测定值中与平均值的偏差超过3倍标准差的值(|z-score|>3)。
3.箱线图分析
1).箱线图分析原理
箱型图可以通过程序设置一个识别异常值的标准,即大于或小于箱型图设定的上下界的数值则识别为异常值,箱型图如下图所示:
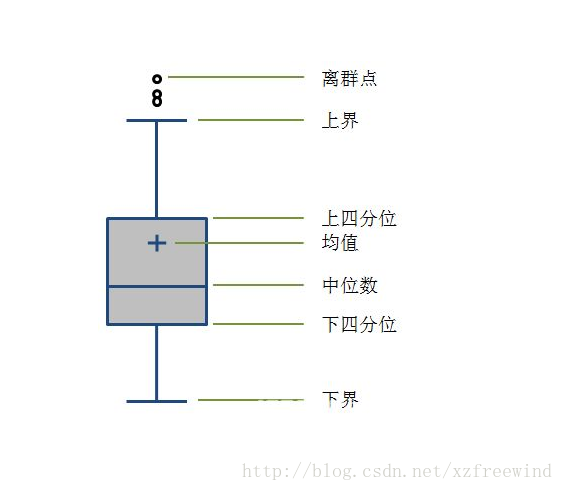
图1
首先我们定义下上四分位和下四分位:上四分位我们设为 U,表示的是所有样本中只有1/4的数值大于U ,即从大到小排序时U处于25%处;同理,下四分位我们设为 L,表示的是所有样本中只有1/4的数值小于L,即从大到小排序时L处于75%处。然后我们定义上界和下界:我们设上四分位与下四分位的插值为IQR,即:IQR=U-L上界设为 U+1.5IQR ,下界设为: L - 1.5IQR箱型图选取异常值比较客观,在识别异常值方面有一定的优越性。
2).R语言箱线图分析
# 设置工作空间
# 把“数据及程序”文件夹拷贝到F盘下,再用setwd设置工作空间
setwd("F:/数据及程序/chapter3/示例程序")
# 读入数据
saledata <- read.csv(file = "./data/catering_sale.csv", header = TRUE)
# 缺失值检测 并打印结果,由于R把TRUE和FALSE分别当作1、0,可以用sum()和mean()函数来分别获取缺失样本数、缺失比例
sum(complete.cases(saledata))
sum(!complete.cases(saledata))
mean(!complete.cases(saledata))
saledata[!complete.cases(saledata), ]
# 异常值检测箱线图
sp <- boxplot(saledata$"sale", boxwex = 0.7)
title("销量异常值检测箱线图")
xi <- 1.1
sd.s <- sd(saledata[complete.cases(saledata), ]$"sale")
mn.s <- mean(saledata[complete.cases(saledata), ]$"sale")
points(xi, mn.s, col = "red", pch = 18)
arrows(xi, mn.s - sd.s, xi, mn.s + sd.s, code = 3, col = "pink", angle = 75, length = .1)
text(rep(c(1.05, 1.05, 0.95, 0.95), length = length(sp$out)),
labels = sp$out[order(sp$out)], sp$out[order(sp$out)] +
rep(c(150, -150, 150, -150), length = length(sp$out)), col = "red")

图2
3).python箱线图分析
import pandas as pd
catering_sale = 'F:/数据及程序/chapter3/示例程序/chapter3/demo/data/catering_sale.xls' #餐饮数据
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure() #建立图像
p = data.boxplot(return_type='dict') #画箱线图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() #从小到大排序,该方法直接改变原对象
#用annotate添加注释
#其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制。
#以下参数都是经过调试的,需要具体问题具体调试。
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() #展示箱线图

二.处理
在数据预处理时,异常值是否剔除,需要按照实际情况来定,常用处理方法如下:
| 异常值处理方法 | 方法描述 |
|---|---|
| 删除含有异常值的记录 | 直接将含有异常值的数据删除(在数据集较小的情况下不适用) |
| 将异常值视为缺失值 | 然后使用处理缺失值的方法来处理异常值 |
| 平均值修正 | 异常值前后两条数据取均值 |
| 不处理 | 原数据集不做任何处理来进行数据挖掘 |
图1来源:https://blog.csdn.net/xzfreewind/article/details/77014587