SphereFace论文学习
代码: https://github.com/wy1iu/sphereface
摘要
论文主要是针对开集的人脸识别任务,在超球面上做到特征分布高内聚、低耦合。作者提出了一种新的损失函数,叫做angular softmax(A-Softmax)。
简介

闭集的人脸识别是一个分类问题,只需要特征是可分的即可;开集的人脸识别更加符合实际业务需要,本质上是一个度量学习的问题,需要学习到有判别力的大间隔的特征。
理想的开集人脸识别学习到的特征需要满足的条件是在特定的度量空间内,需要同一类内的最大距离小于不同类之间的最小距离。然后再使用最近邻检索就可以实现良好的人脸识别和人脸验证性能。
center loss只是强调了类内的聚合度;对比损失和三元组损失需要精心地构建图像对和三元组,耗时并且构建的训练对的好坏直接影响识别性能。
一般都是想在欧式空间中学习到有判别力的特征,作者提出了一个问题:欧式空间的间隔总是适合于表示学习到了有判别力的特征吗?
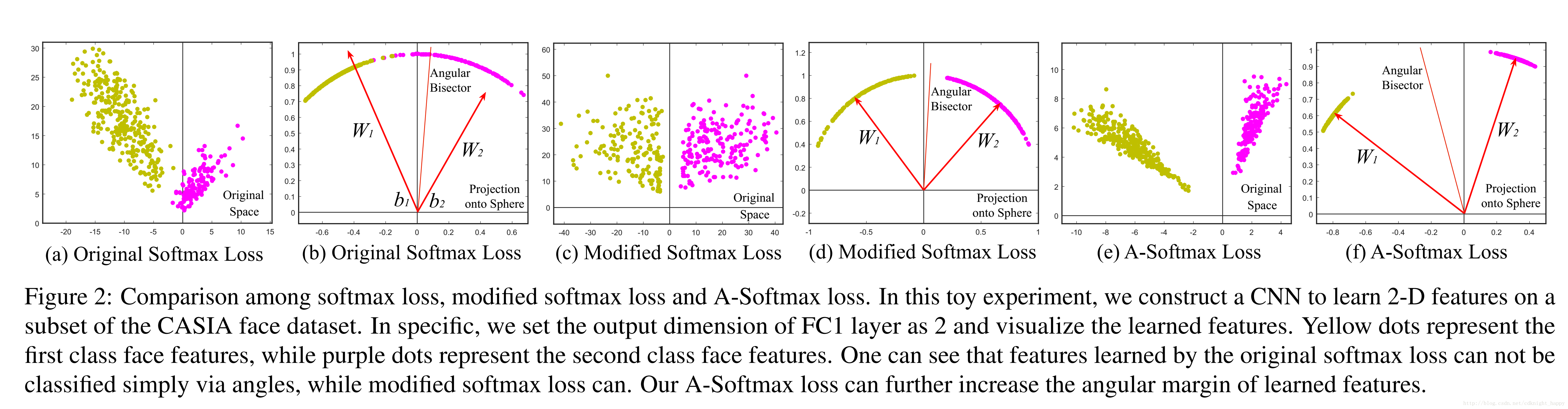
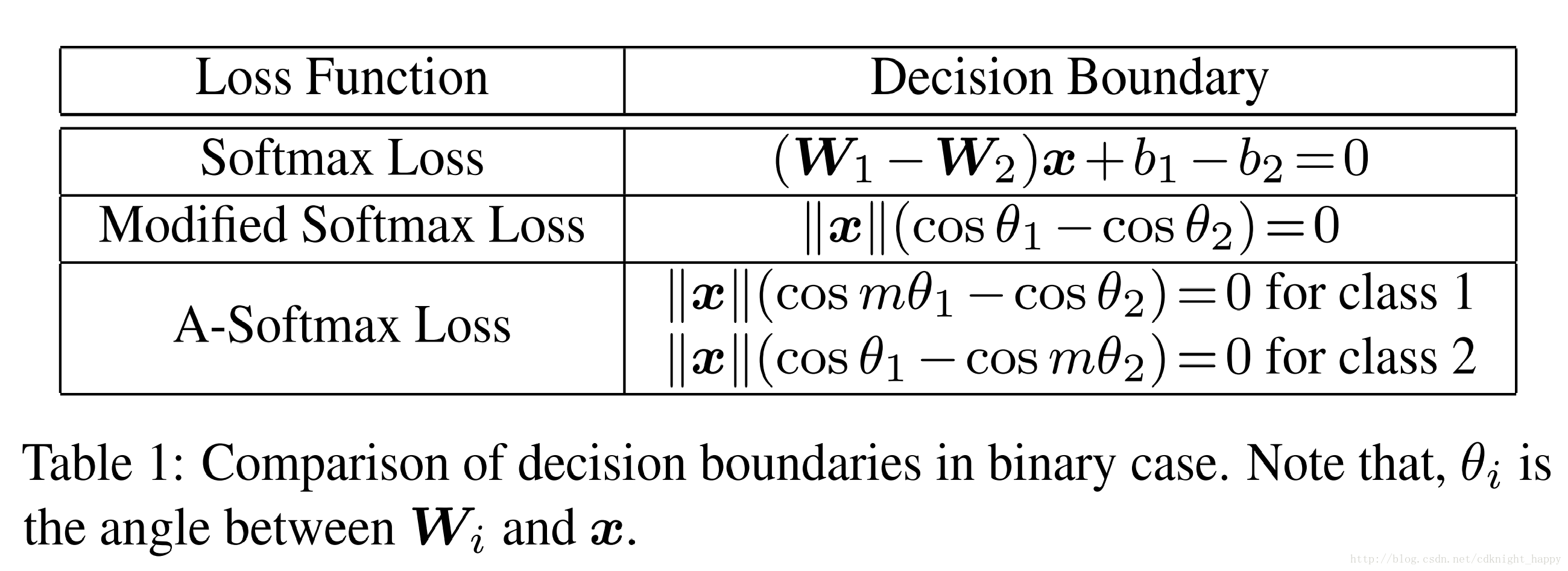
在上图中,对于一个二分类的softmax,决策边界是(W1−W2)x+b1−b2=0(W1−W2)x+b1−b2=0,这样设计的损失函数直接关注的是特征的角度可分性,使得训练出的CNN学习到具有角度判别力的特征。
作者在修改的softmax的基础上进一步加强了限制条件设计了A-Softmax,引入了一个整数m加大角度间隔。决策边界变形为||x||(cos(mθ1)−cos(θ2))=0和||x||(cos(θ1)−cos(mθ2))=0||x||(cos(mθ1)−cos(θ2))=0和||x||(cos(θ1)−cos(mθ2))=0。通过最优化A-Softmax,决策区域更加可分,在增大类间间隔的同时压缩了类内的角度分布。
核心思想
三种softmax函数的决策边界对比
softmax-loss
二分类的softmax输出:
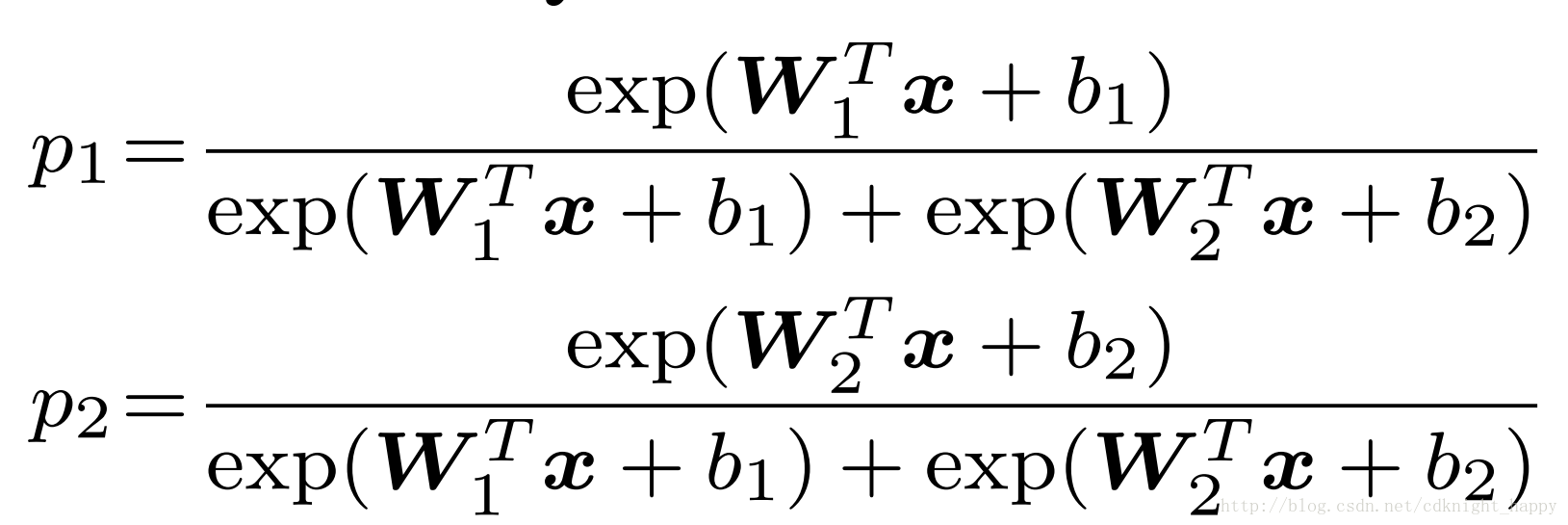
Wi和bi是最后一个全连接层中和第i类关联的参数Wi和bi是最后一个全连接层中和第i类关联的参数.
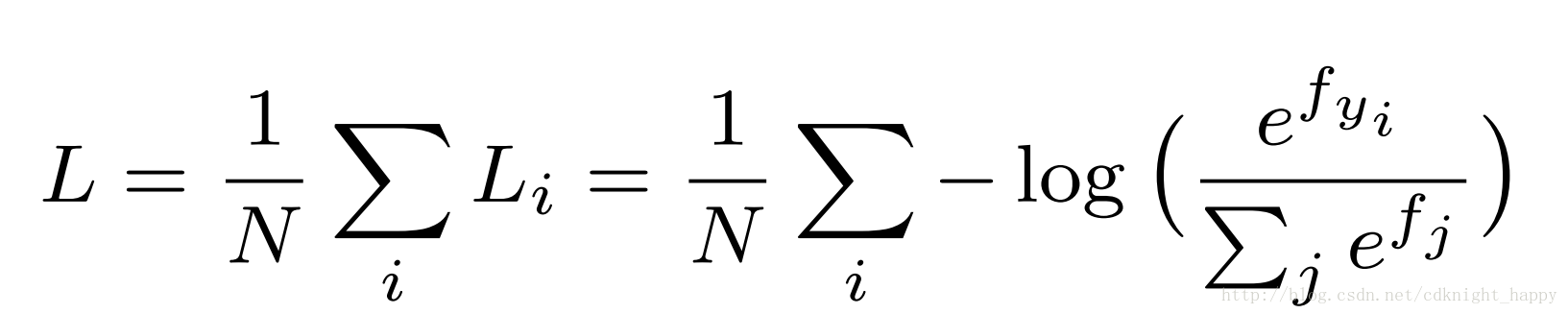
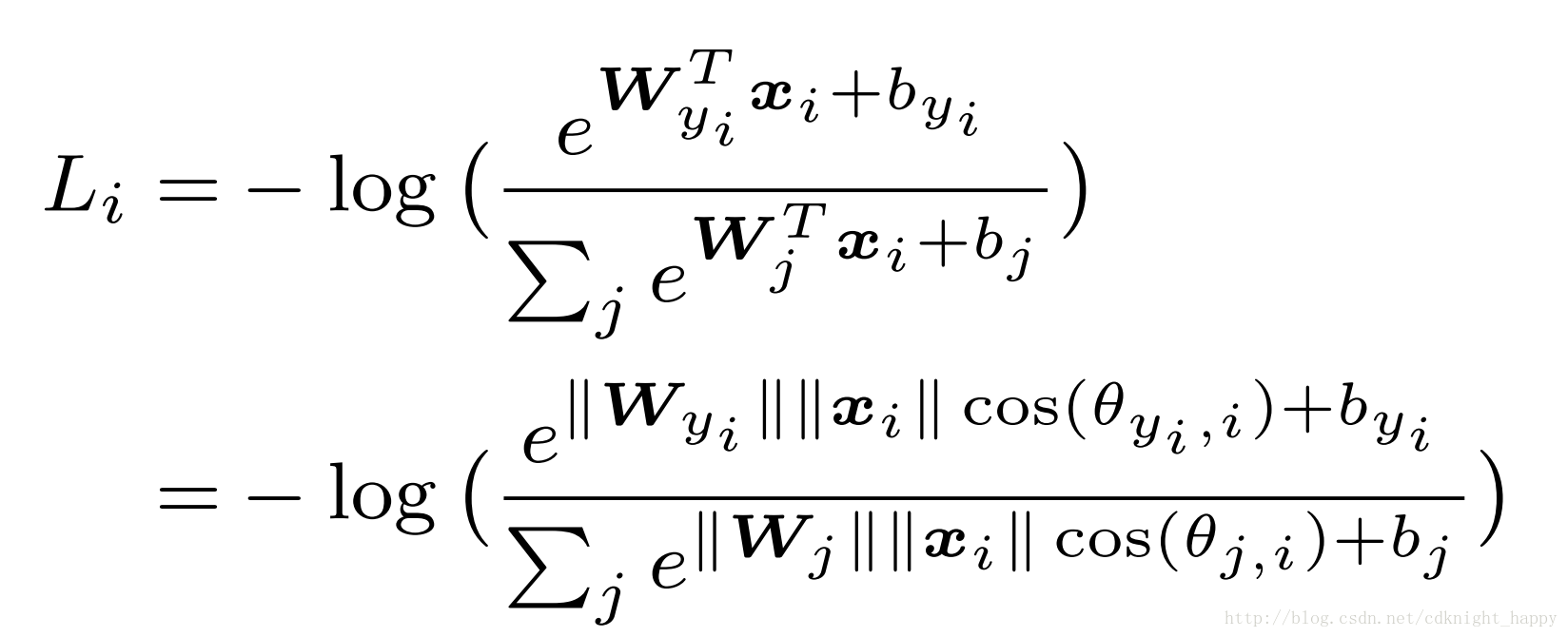
Modified softmax
由于WTix+bi=||WT||||x||cos(θi)+biWiTx+bi=||WT||||x||cos(θi)+bi。多分类的情况下,分类边界也是同样的。
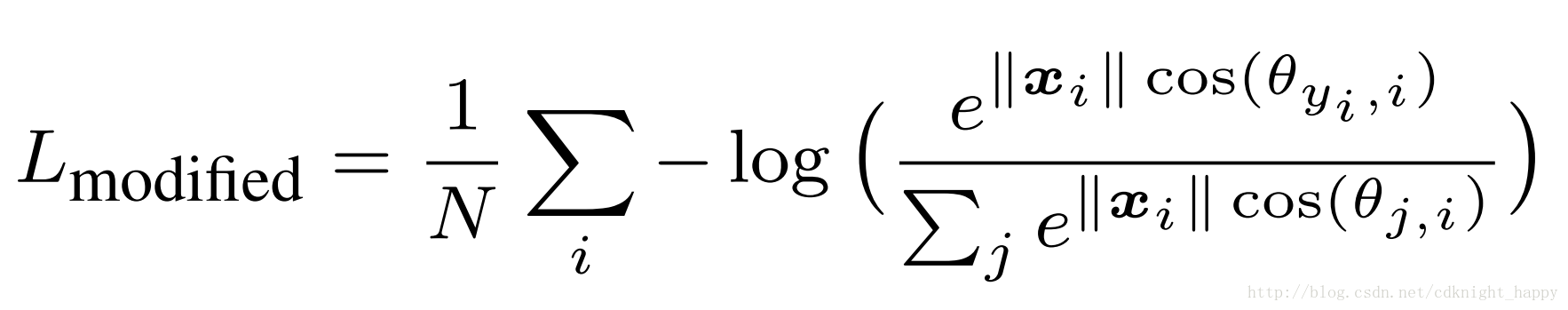
A-softmax
A-softmax是在modified softmax的基础上添加更严格的限制,即要求cos(mθ1)>cos(θ2)或cos(mθ2)>cos(θ1)cos(mθ1)>cos(θ2)或cos(mθ2)>cos(θ1);
泛化形式为:
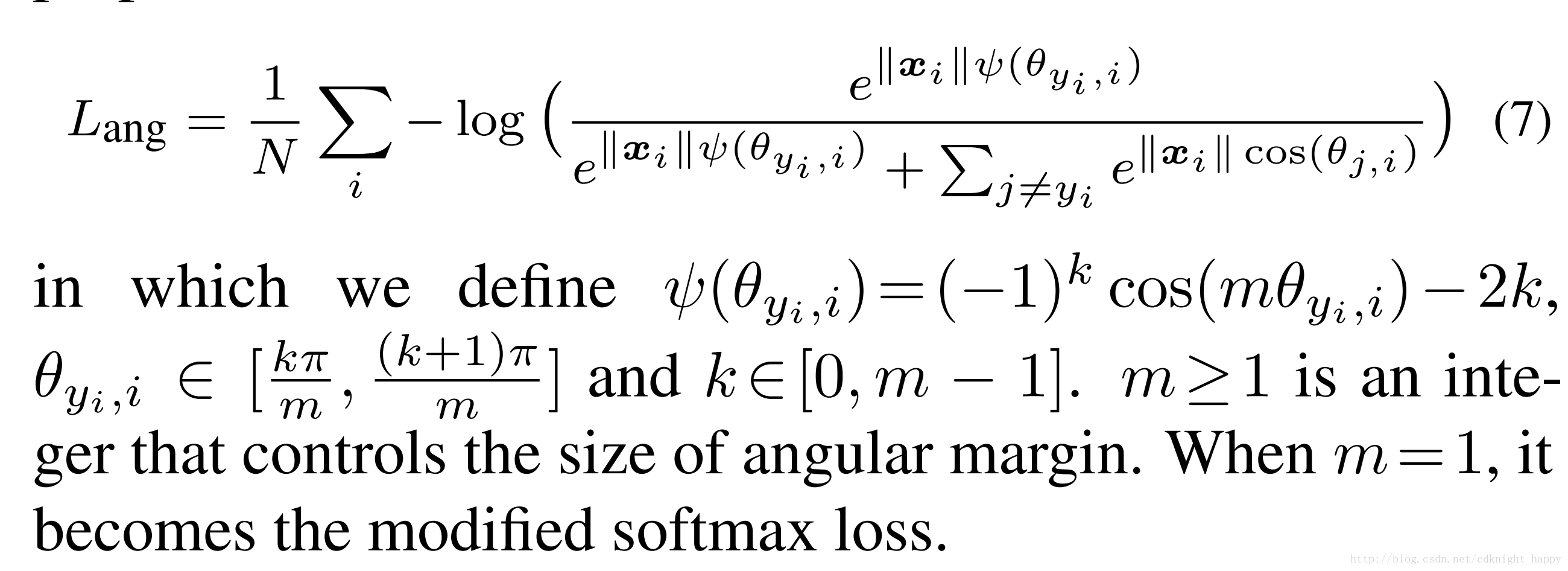
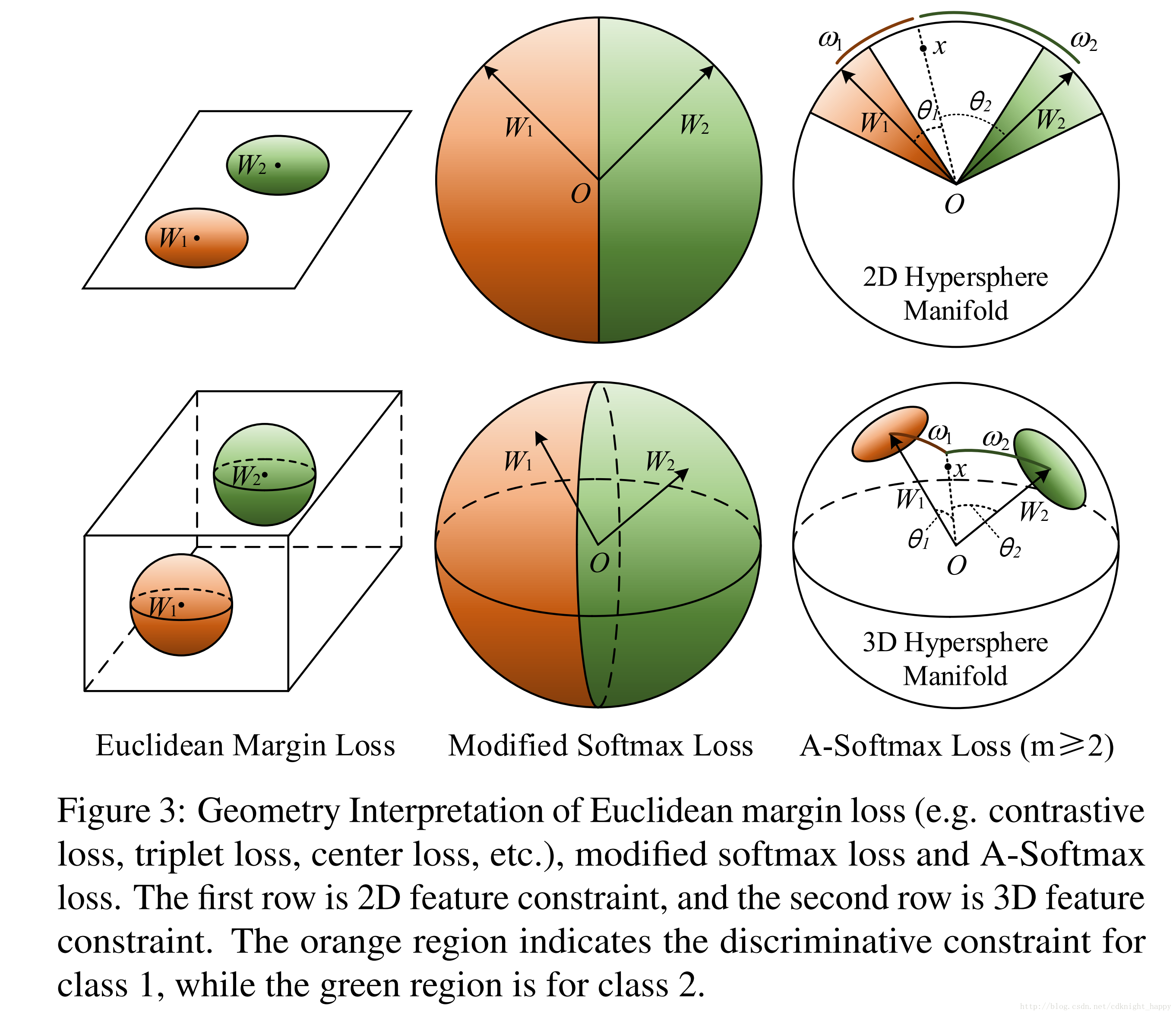
最优化A-Softmax损失本质上是使得学习到的特征在超球面上更加具有可区分性。
A-Softmax损失的性质
- m越大,损失函数最优化的难度越大,形成的角度间隔越大;
- 由于要使得同类的最大角度分布小于最小的不同类之间的间隔,所以m的取值有下限。对于二分类的情况,mmin≥2+3–√mmin≥2+3;求解过程可以参考https://www.cnblogs.com/heguanyou/p/7503025.html#_caption_5
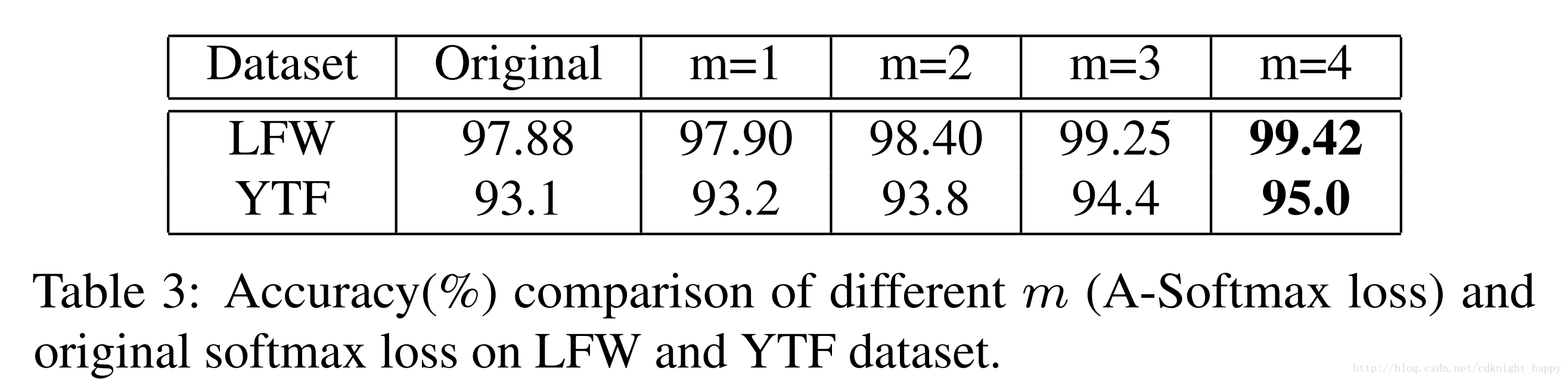
实验中,作者一般使用m=4.
实验
预处理:MTCNN人脸检测和特征点提取;减127.5除128处理图像。
使用余弦距离比较图像提取的特征的相似度;
所有的测试图像的特征都是原始人脸图像的特征和水平翻转之后的人脸图像的特征的连接向量作为最终特征。
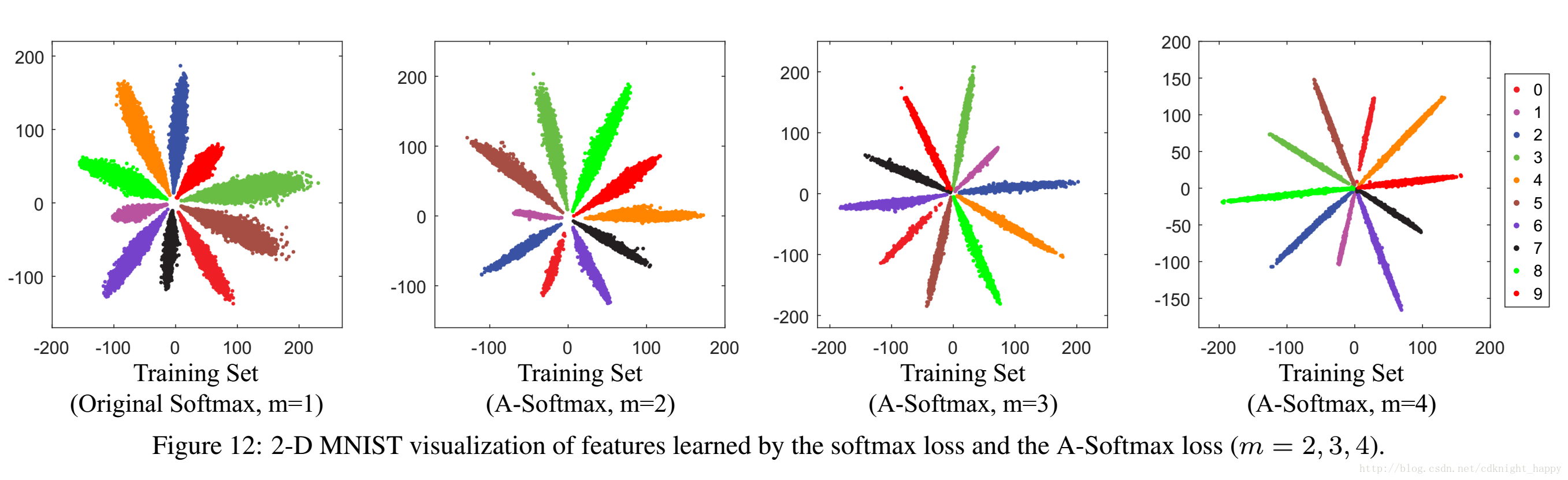
m越大,准确率越高
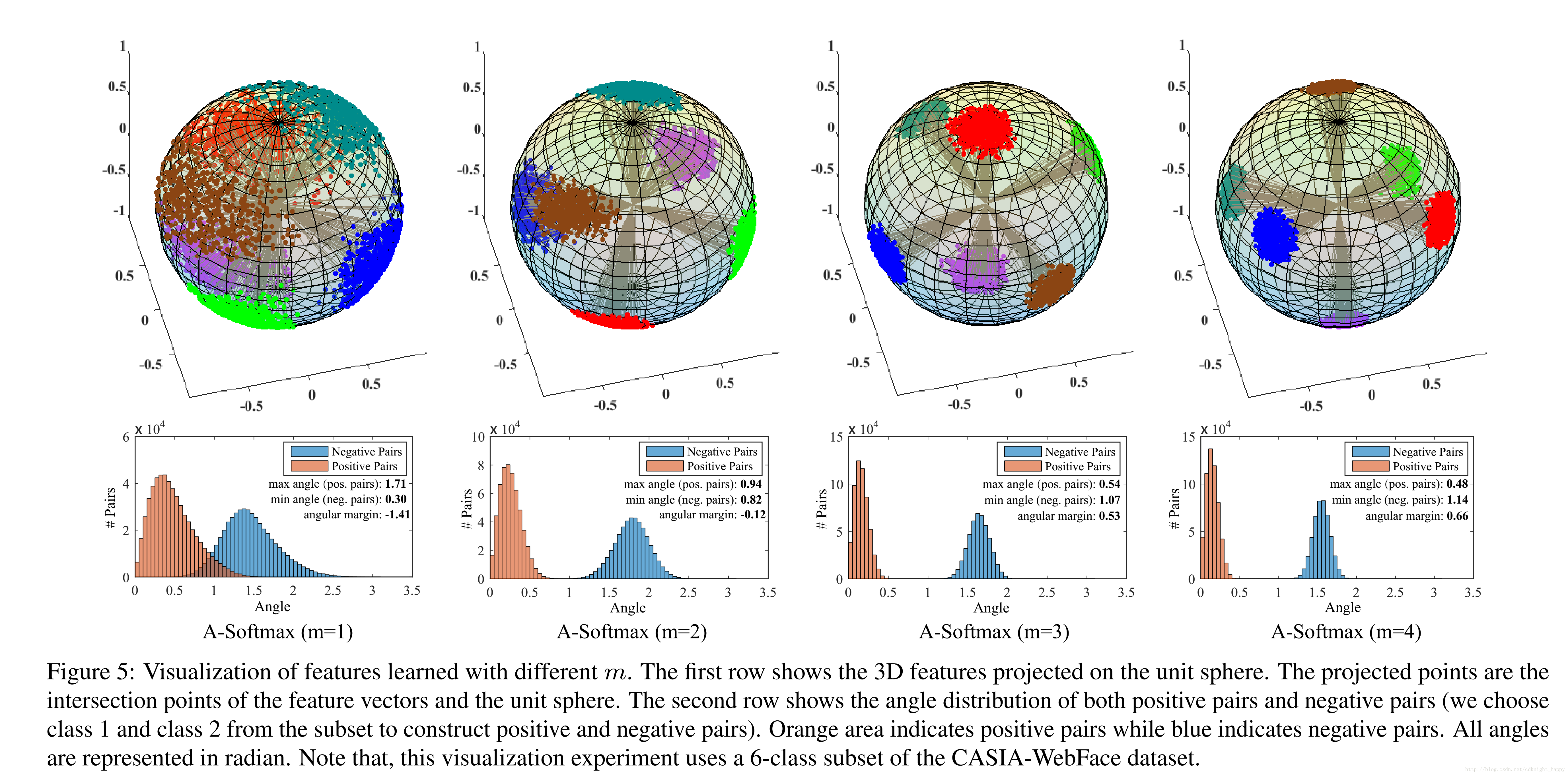
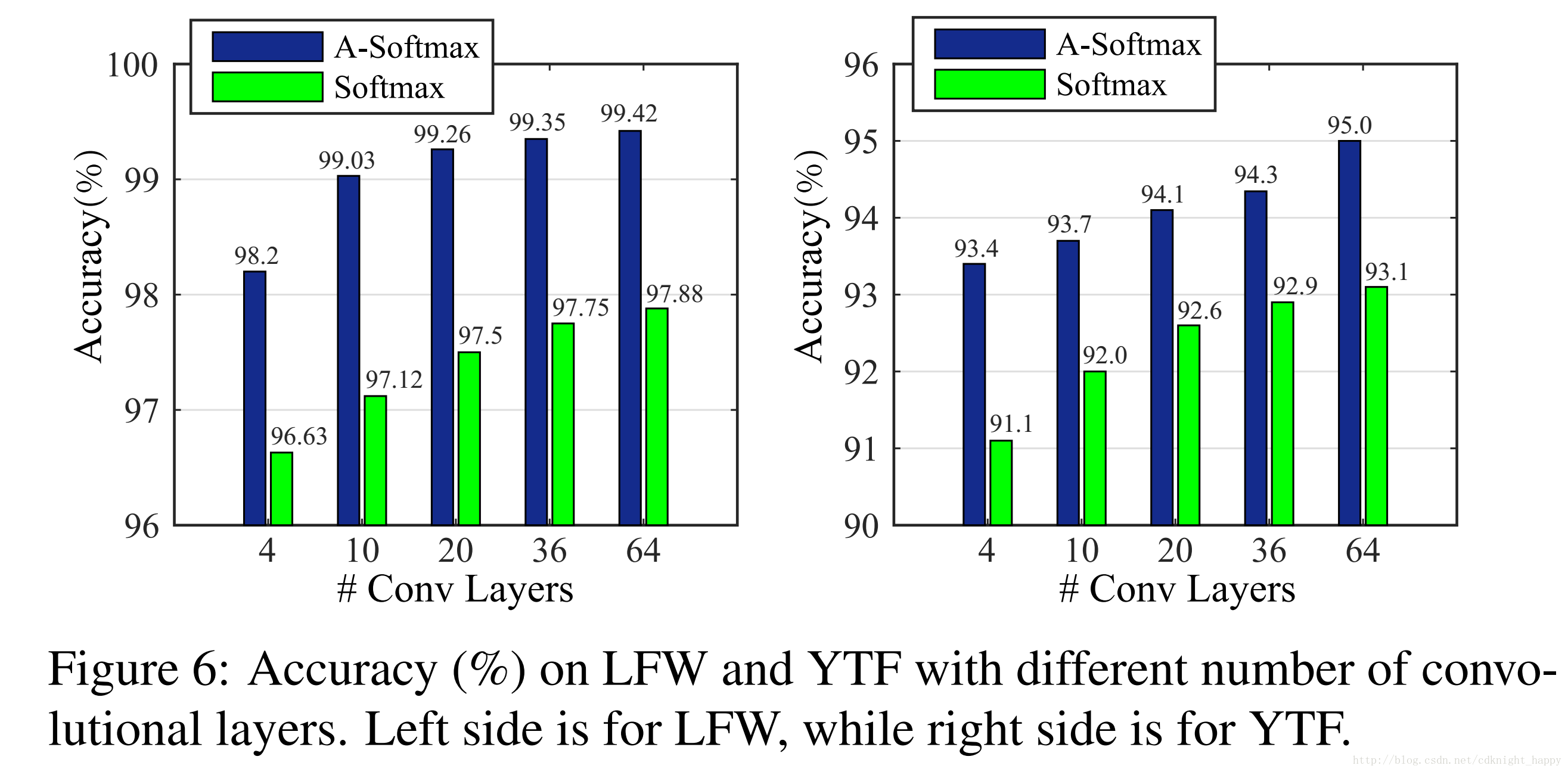
A-Softmax准确率全面超越Softmax
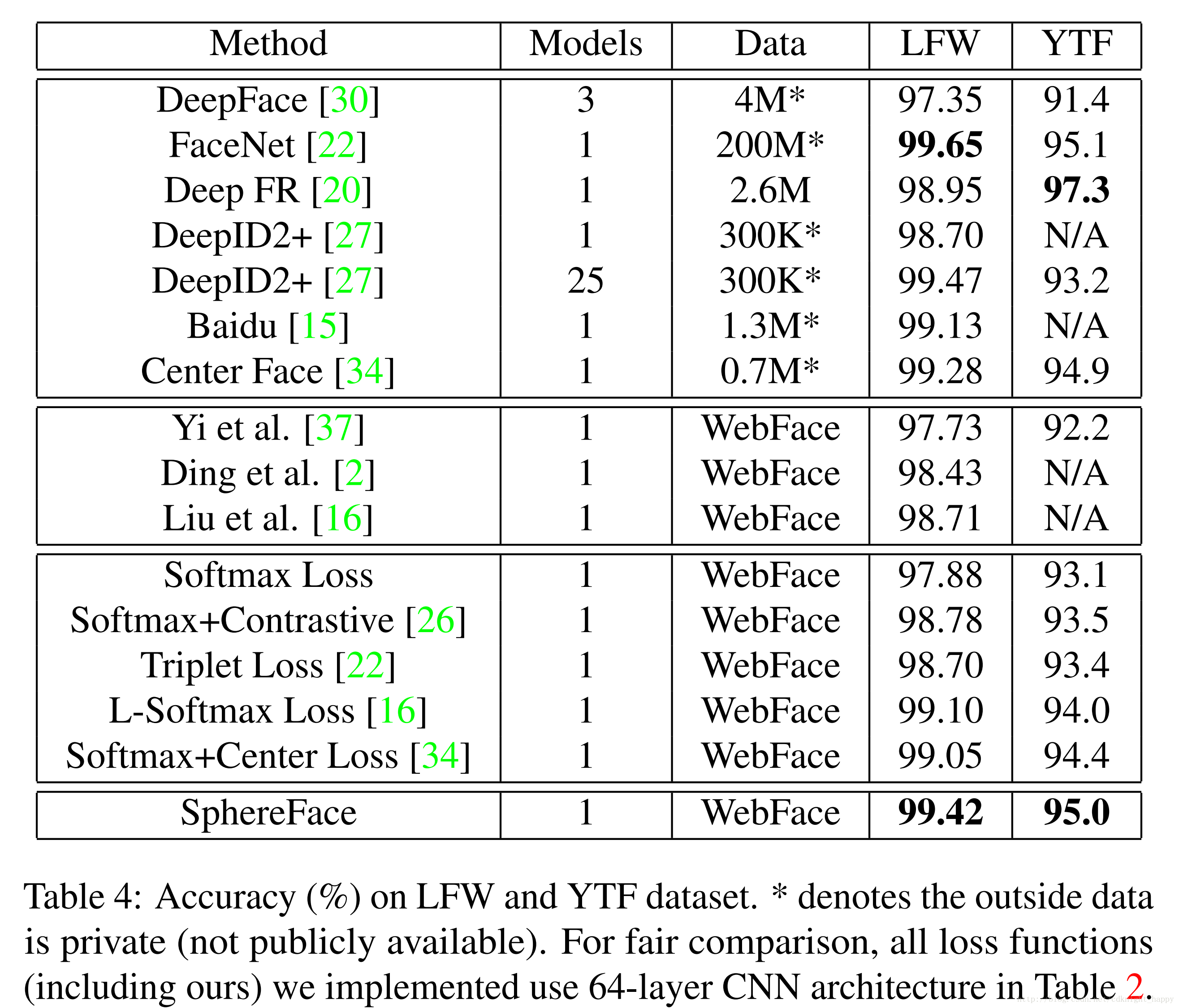
对比其他算法
附录
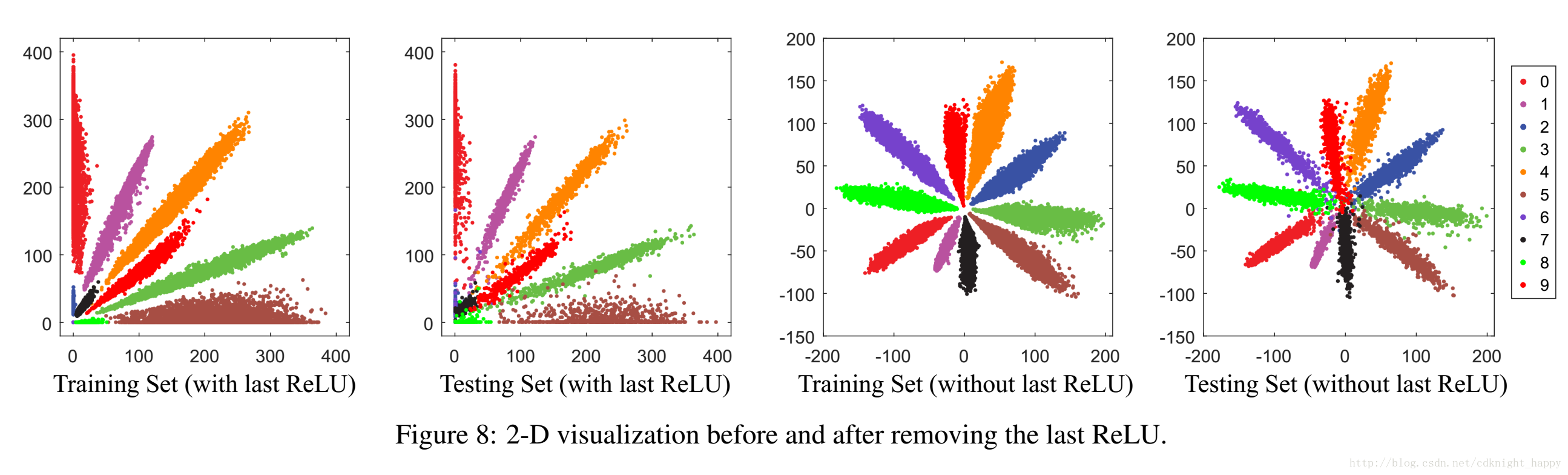
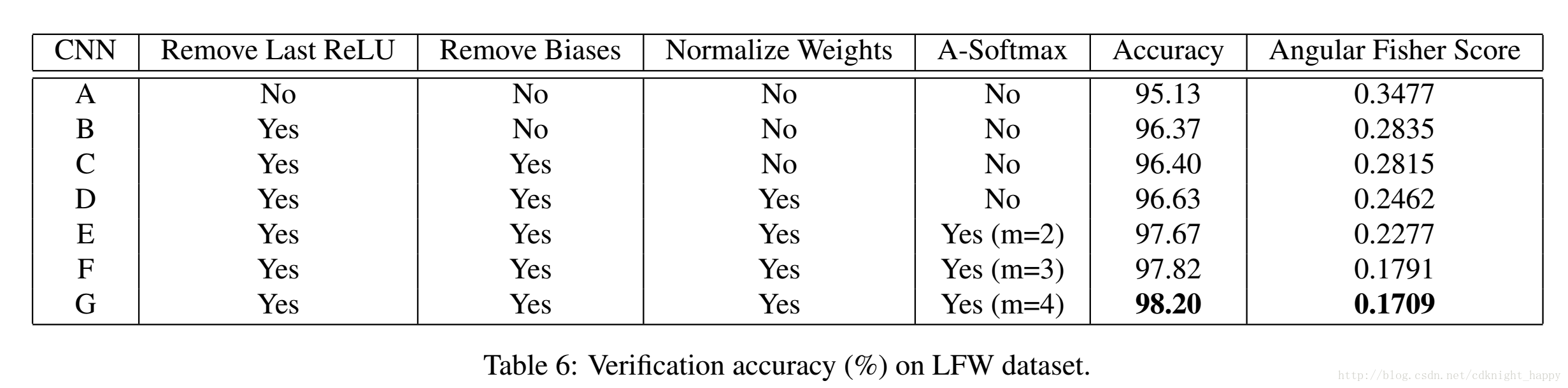
移除倒数第二层的ReLU
移除倒数第二层(一般为全连接层)的ReLU,学习到的特征分布不被限制在第一象限,学习到的特征分布更加合理。
权重归一化的作用
归一化权重可以减小训练数据不均衡造成的影响。
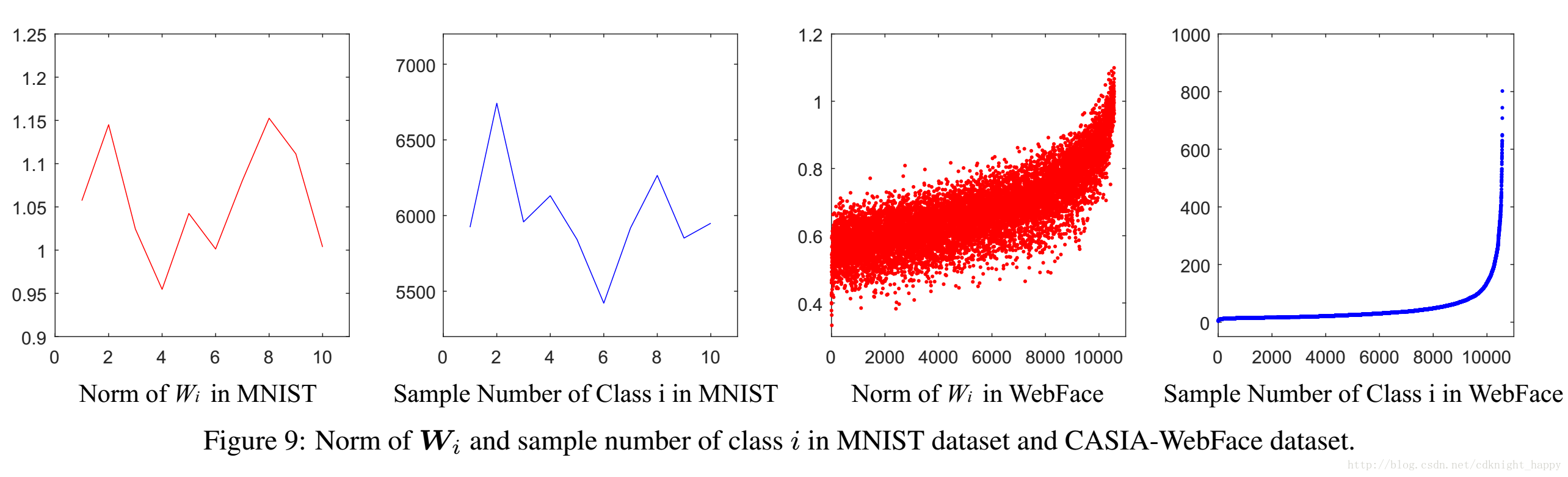
权重矩阵的第i行WiWi的范数主要取决于第i类训练样本的数量和分布情况。
对于人脸验证的任务和开集人脸识别的任务而言,测试图像的类是从未在训练样本中出现过的,所以应该消除上述先验信息。具体的做法就是归一化和softmax函数直接连接的全连接层的W。
偏置项置0
偏置项置0,主要是为了方便几何分析。作者分析了预训练的CASIC的模型,发现大部分的偏置项取值都是0;还对比了在MNIST上加不加偏置项,学习到的特征分布基本没什么变化。
可视化在MNIST数据集上通过A-Softmax loss学习到的特征分布
AFS Score
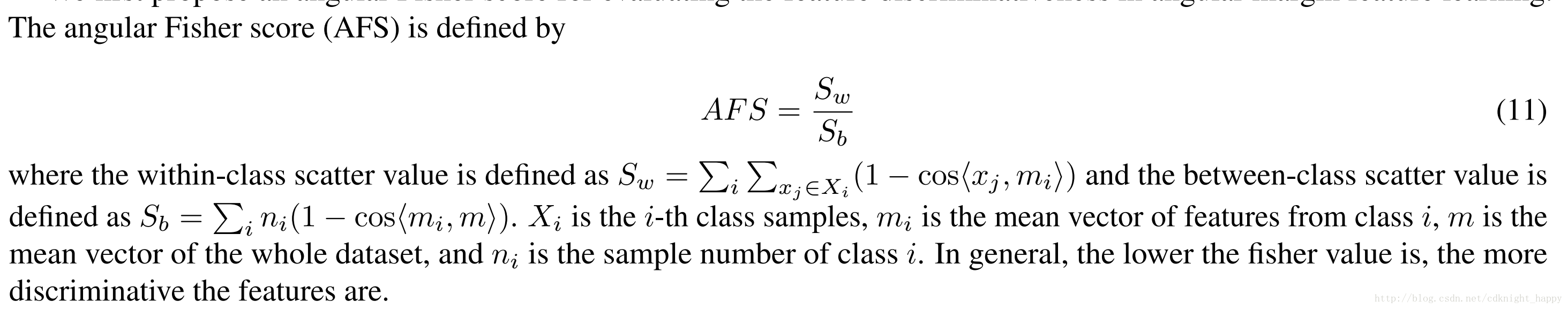
每一个idea有多大的作用
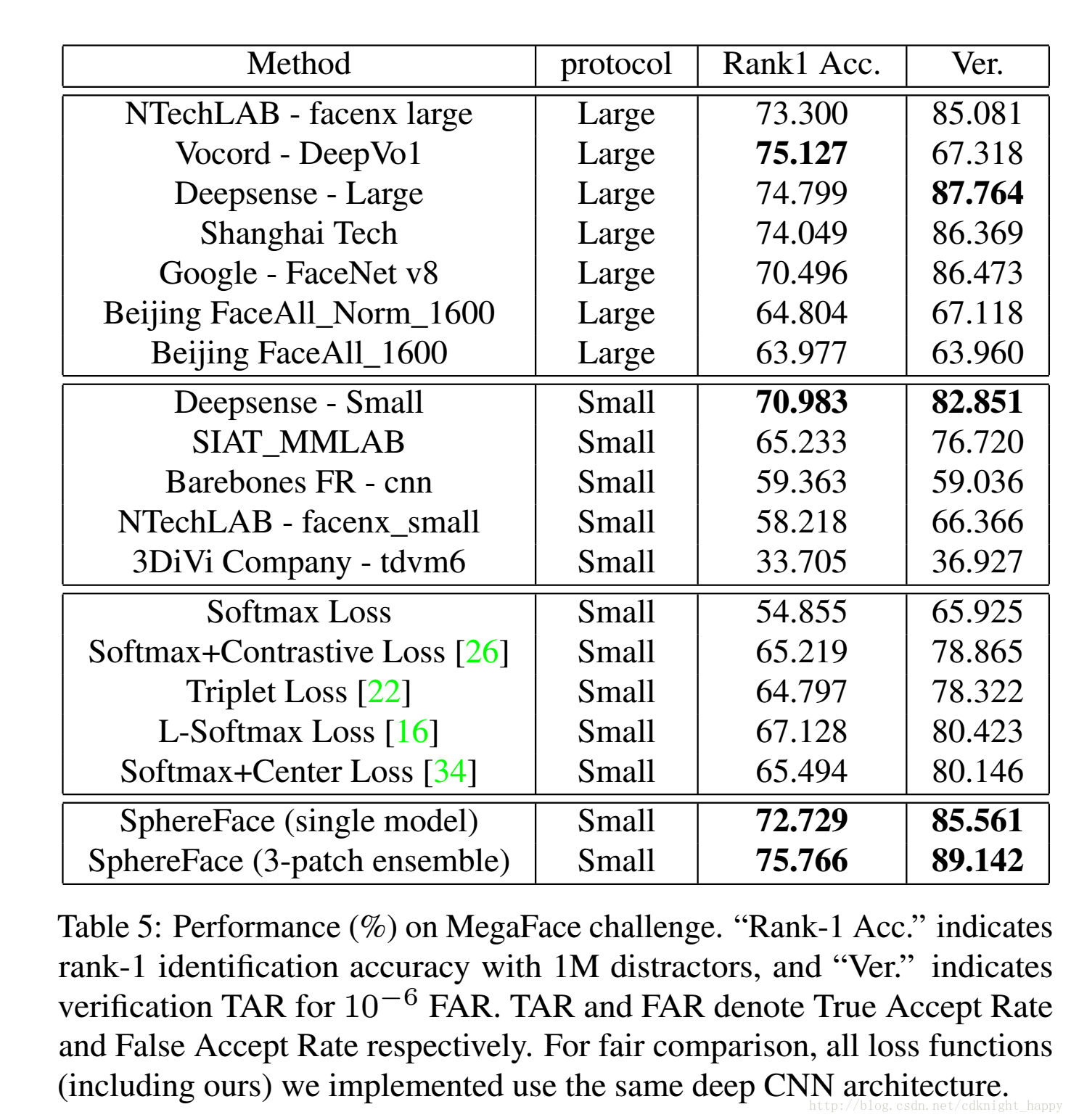
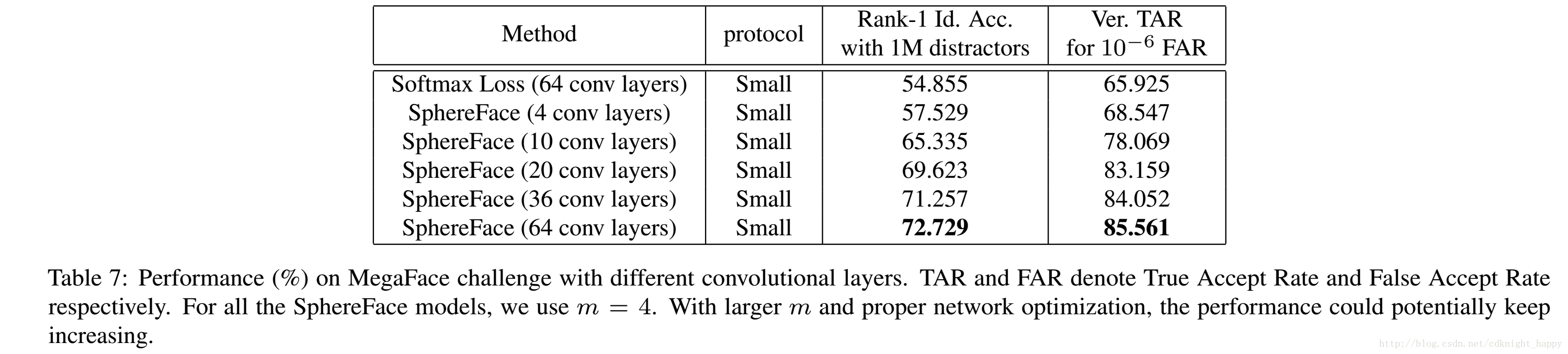
不同网络在MegaFace上的作用
A-Softmax的近似最优化策略
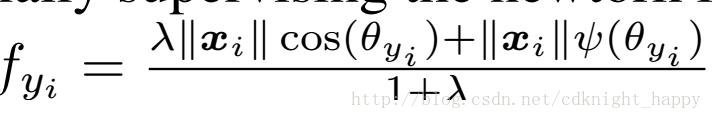
初始时,λλ逐渐减小到5。
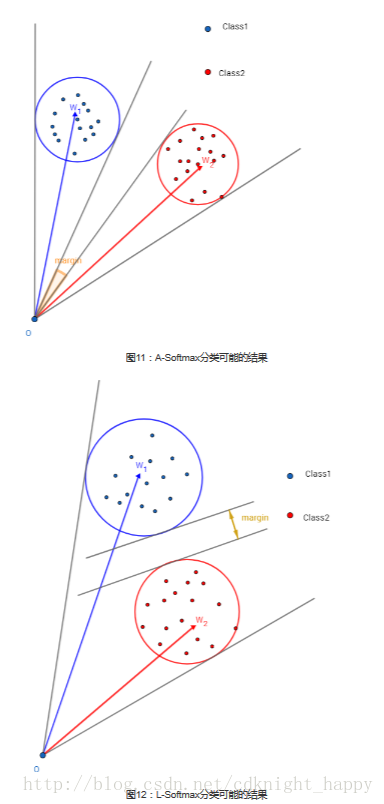
A-Softmax 于 L-Softmax对比
转载自:https://www.cnblogs.com/heguanyou/p/7503025.html#_caption_5