XGBoost原理
关于xgboost原因有很多文章做过详尽的解释,这里列出基本思路和推荐一些文章。
XGBoost重要的点
xgboost(eXtreme Gradient Bosting)极端梯度提升是基于GDBT改进而来的,其优化的点有
1.对于GBDT的目标函数利用泰勒展开得到一阶和二阶梯度信息来近似目标函数
去除常数项和将一阶、二阶替换得
其中
为第t棵树中总叶子节点个数,
为叶子节点分数,γ控制叶子节点的个数,λ可以控制叶子节点分数不会太大,防止过拟合。
最终得到目标函数为
这个目标函数值越小越好,代表这个数的结构更好。
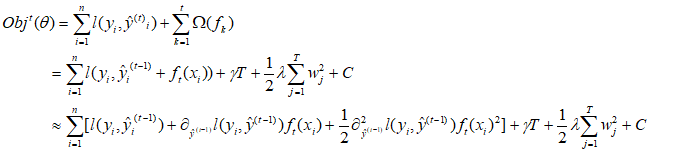
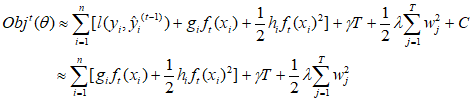
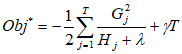
2.寻找最佳分割点
GDBT分裂点方法,由于GDBT使用的是CART中回归树,通过最小均方误差来找到最佳分割点。具体情况见一步一步理解GB、GBDT、xgboost。
xgboost分裂点方法-近似算法
大概思路是根据百分位法划分多个分割候选者,然后从候选者找出最佳分割点。其单个分裂流程:通过遍历所有特征的所有特征划分点,使用目标函数值作为评价函数。具体做法分裂后目标函数值 / 叶子节点的目标函数的增益,当增益大于某个阈值才开始分裂。
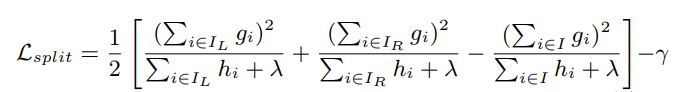
中括号第一项是左子树分数,第二项是右子树分数,第三项是不分割时候的分数,γ是加入新叶子节点引入复杂度代价。
3.防止过拟合方法
GDBT和XGBOOST都可以通过设置树的深度、设置样本权重和阈值来达到防止过拟合。
除此之外,还有Shrinkage , Column Subsampling。
Shrinkage思路是每次迭代中对树的每个叶子节点的分数乘以一个缩减权重η,这有个好处是这颗树的分数不会太高,产生的残差优化空间更大,方便后续模型迭代不容易过拟合。
Column Subsampling思路是按层随机采样,在树的同一层每个节点分裂之前先随机选择一部分特征,随后只需遍历这部分特征来确定最优分割点。
4.连续型特征划分
面对连续型样本,如果样本数据量大、取值太多,遍历所有取值会花费很多时间,且容易过拟合。xgboost处理思路是对连续型数据进行分桶,方法是找到一个划分点,将相邻分位点之间的样本分在一个桶中,在遍历该特征的时候,只需要遍历各个分位点,从而计算最优划分。
5.缺失值处理
当样本存在缺失值数据无法进行特征划分,xgboost思路是将存在缺失值样本分别放在左系节点和右节点,然后计算两边的增益,那边大最后将缺失值的数据放哪边。
6.处理数据并行化
主要体现在计算增益的时候,在选择最佳分裂点,候选分裂点增益计算是多线程进行的
XGBoost决策树生长策略
XGBoost采取带深度限制level-wise生长策略,level-wise过一次数据可以同时分裂同一层的叶子,可以做多线程,不容易过拟合。但是对同一层的叶子不考虑增益大小统一处理,容易造成多余的开销。
特征重要性计算
xgboost提供三种计算方法
- weight
- gain
- cover