最近有个测试项目,是针对云平台的数据库连接稳定性测试,一般做稳定性测试想到的工具是Loadrunner,因为“成熟稳定”,但是这么重量级的工具不适合搬到云平台上开展测试。而Jmeter作为一款优秀的开源测试工具,属于经量级的,但是基于java的稳定性还是不如Loadrunner。【关于jmeter的特性和性能优化,可以参见我的另一篇文章《针对性能测试工具Gatling与Jmeter的比较及看法》】
首先将Jmeter轻量包(免安装)上传到云平台,这次肯定是要分布式测试了(因为要测试20台虚拟机与阿里Mysql连接的稳定性),每一台虚拟机都部署上JDK和Jmeter,并启动jmeter-server。主控机的jmeter肯定不能用GUI模式调用了(要是那样的话不得内存溢出或卡到死),直接通过以下命令调用(好处就不说了):
jmeterHome3.1\bin\jmeter -n -t jmeterHome3.1\bin\MysqlTest.jmx -R 10.2.116.116,10.2.116.118,[省略后面的IP] -l DashReport\log-20180413.csv -e -o DashReport\htmlReport-20180413
如果是要生成不被覆盖的测试报告,可以通过自动生成日期时间来新生成报告:
Windows下的运行脚本样例为:
@echo off
set a=%time:~0,2%%time:~3,2%%time:~6,2%
set b=0%time:~1,1%%time:~3,2%%time:~6,2%
if %time:~0,2% leq 9 (set c=%b%)else set c=%a%
jmeterHome3.2\bin\jmeter -n -t rfAppTest.jmx -l DashReport\log-%Date:~0,4%%Date:~5,2%%Date:~8,2%%c%.csv -e -o DashReport\htmlReport-%Date:~5,2%%Date:~8,2%%c%
pause
Linux下的运行脚本样例为:
#!/bin/bash
Cur_Dir=$(cd "$(dirname "$0")"; pwd)
$Cur_Dir/jmeterHome3.2/bin/jmeter -n -t $Cur_Dir/jmeterHome3.2/bin/websocket-test.jmx -l $Cur_Dir/DashReport/log-$(date -d "today" +"%Y%m%d%H%M%S").csv -e -o $Cur_Dir/DashReport/htmlReport-$(date -d "today" +"%m%d%H%M%S")
对于远程负载机较多的情况,就可以在jmeter-server文件上配置,然后用 -r (上面是用-R)来表示启动远程压力机。上面的命令除了生成报告日志csv,还有通过DashReport自动生成视图报告。关于如何产生DashReport可视化测试报告,可以参考我的另一篇文章 Jmeter和Ant的html报告优化及Dashboard Report介绍【https://blog.csdn.net/smooth00/article/details/78728060】。
按理到这一步,就达到我的要求了,但是经过实际操作后发现问题的严峻性了,那就是随着测试时间的延长(不到4小时),发现log-20180413.csv报告文件越来越大,当超过1G后,问题就暴露了,这么大的监控日志如何转换成html报告(实际上只有最近1个小时的监控数据能够转换,再长时间的就处理不过来了,更别提我要进行跨天的测试监控),另外一个严峻的问题是,随着测试文件的越来越大,对Jmeter造成了挑战,这就是最大的不稳定因素,磁盘的读写瓶颈,随时都可能让它崩溃。(注:这个问题在Windows下表现尤为明显,在Linux下就算产生再大的报告文件也不至于让Jmeter出现运行异常,但是最终要将超过几个G的报告转为html报告也会是件要命的事,需要找个内存高的机器专门用来转换html报告)
这时候我的想法就是如何将测试监控日志保存到数据库,第一个方案就是通过Beanshell来计算JDBC请求的响应时间,分别通过BeanShell PreProcessor和BeanShell PostProcessor来获取请求前和请求后的时间戳,然后相减算出时间差:
import java.util.Date;
long planDate2 = System.currentTimeMillis();//planDate是在PreProcessor生成的时间戳
long conTime=planDate2-Long.valueOf(vars.get("planDate")).longValue();
vars.put("connTime",conTime.toString());
同时获取每台压力机的IP
String addr = InetAddress.getLocalHost().getHostAddress();//获得各个压力机IP
vars.put("addrIP",addr);
然后把请求的响应时间、压力机IP、请求开始的时间戳,把这些数据通过JDBC的insert请求插入到数据库表中,作为监控数据,然后通过可视化平台展现出来(我用的是我们APM工具当中的自定义轮询查询的方式),展现效果如下:
按理这样也算达到我的目的了,但是接着又出现一个新问题,就是这种轮询展现的方式过于机械化,因为轮询的时间是1分种一次,精度上不够,又不能灵活的选择监控时间段,这样随着测试时间的拉长,测试曲线图密度越来越大,最后就不直观了。而且还有个更严重的问题,如果Jmeter出问题了,也没法第一时间发现和排查。
看来我的想法跟实际还是有不小差距,上网专门查了一下,发现Jmeter其实是有相关的功能的,即 Jmeter + Grafana + InfluxDB的方式,于是我又开始用最短的时间,配置了InfluxDB、Grafana(开始以为这个部署过程会很长,没想到这两工具也是轻量化的,不用安装也能运行)。
1、下载,grafana-5.0.4.windows-x64.zip和influxdb-1.5.1_windows_amd64.zip,为什么下载Windows版本,主要是因为懒得在Linux下配置,先用顺Windows下的再说。
(1)到官网下载influxdb,https://portal.influxdata.com/downloads,说是要翻墙下,其实也不用,只要右键查看网站源码,就能看到下载链接:

(2)到官网下载grafana,https://grafana.com/grafana/download?platform=windows
除了windows版本,还有linux版本,我们可以将两版本合到一起,做成一个通用包。
2、直接解压,就可以开始配置和使用
(1)针对influxdb,修改influxdb.conf文件(jmeter通过2003端口连)
[[graphite]]
enabled = true
database = "jmeter"
bind-address = ":2003"
protocol = "tcp"
consistency-level = "one"
把http的8086端口的注释也去掉(grafana通过8086端口连)
[http]
# Determines whether HTTP endpoint is enabled.
enabled = true
# The bind address used by the HTTP service.
bind-address = ":8086"
启动influxdb,通过CMD到influxdb的目录下,直接命令 influxd -config influxdb.conf 启动
(2)针对Jmeter,添加“监听器 -> Backend Listener”,并配置“Backend Listener”,主要配置Host,如下图:

注意IP和端口的配置要正确。
以上的配置,跟默认情况不一样的是,将summaryOnly设为false,useRegexpForSamplersList设为true,并配置了samplersList的正则表达试为JDBC.*,目的是可以监听所有以JDBC名称开头的Request请求。
(3)针对grafana,很简单,到Grafana安装目录中的bin目录下,双击grafana-server.exe启动程序
访问http://localhost:3000,用admin(密码admin)登录,开始配置:
第一步、配置数据库,在设置-->Data Sources,添加,配置以下画圈的部分就可以了,然后直接保存通过

第二步,在面板中添加Graph,选择Data Source为jmeter,在查询条件中,选择你要监控的指标,可以添选多个指标
 配置好了,就能看到图了。如果看不到图,请用Jmeter多发几次请求。可以选择最右上角的监控时间段来精确化的监控指定时间段的测试数据:
配置好了,就能看到图了。如果看不到图,请用Jmeter多发几次请求。可以选择最右上角的监控时间段来精确化的监控指定时间段的测试数据:

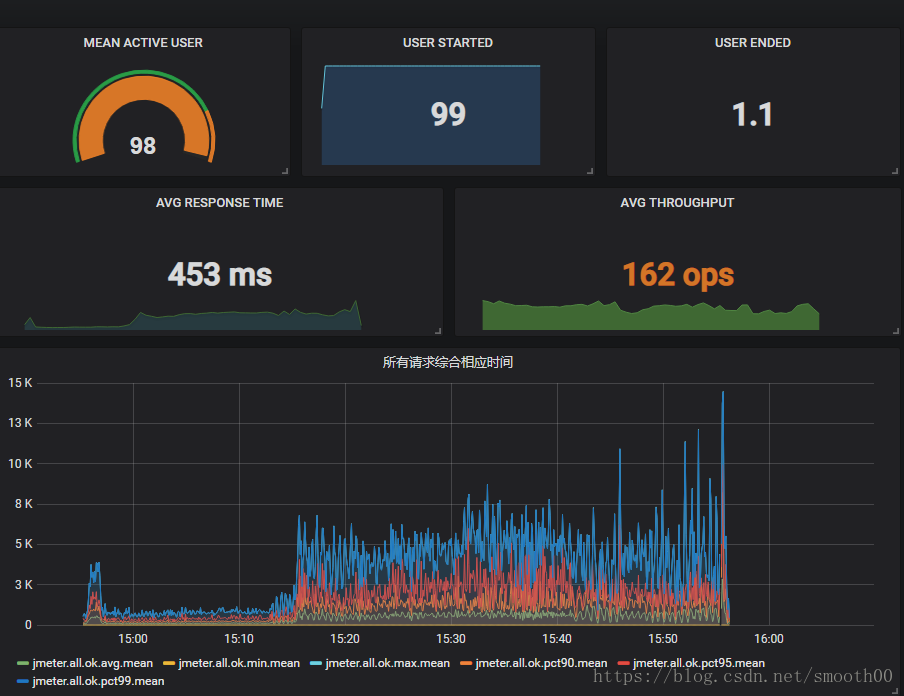
以上是我配置后产生的监控效果图,由于可以实时监控,查看历史监控,按15分种、半小时、1小时、1天的不同时段展现,很好的解决了我要求长时间监控测试的目的。测试数据不再通过文件保存,避免了磁盘IO限制的问题,也解决了测试时间过长,报告无法读取和展现的问题。
另外用这种测试模式,我们还可以达到Jmeter分布式集群的去中心化,让Master不再负责各节点测试数据的收集和处理(交给influxdb来完成),只专注于slave的调度,甚至可以进行多master-slave部署,由Jenkins进行同步调度测试。
附:几种我们常用的监控指标:
| 名称 |
描述 |
| jmeter.all.h.count |
所有请求的TPS |
| jmeter.<请求名称>.h.count |
对应<请求名称>的TPS |
| jmeter.all.ok.pct99 |
99%的请求响应时间 |
| jmeter.<请求名称>.ok.pct99 |
对应<请求名称>99%的请求响应时间 |
| jmeter.all.test.startedT |
线程数 |
为了能方便的同时启动influxDB和Grafana,我专门写了启动脚本,有两份,一份是windows版的,一份是Linux版的
Windows版的
@echo off
start cmd /k ""%~dp0influxdb-1.5.1/influxd.exe" -config "%~dp0influxdb-1.5.1/influxdb.conf""
cd "%~dp0grafana-5.0.4\bin"
start cmd /k "grafana-server.exe"
Linux版的(为了后台运行并且避免进程冲突,linux版的写的比较复杂一些):
#!/bin/bash
# Author:zheng
# Date:2018-04-18
InstanceCount=1
Cur_Dir=$(cd "$(dirname "$0")"; pwd)
influxdb_v=influxdb-1.5.1
grafana_v=grafana-5.0.4
chmod -R 777 $Cur_Dir/$influxdb_v/bin
chmod -R 777 $Cur_Dir/$grafana_v/bin
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "----Current directory is " $PWD
# 检查$ProcessName实例是否已经存在
#while [ 1 ] ; do
#$PROCESS_NUM获取指定进程名的数目
PROCESS_NUM=`ps -ef | grep "influxd" | grep -v "grep" | wc -l`
if [ $PROCESS_NUM -lt $InstanceCount ];
then
StopCount=`expr $InstanceCount - $PROCESS_NUM `
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "----influxd service [total $StopCount] was not started."
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "----Starting influxd service[total $StopCount] ."
(nohup $Cur_Dir/$influxdb_v/bin/influxd -config $Cur_Dir/$influxdb_v/influxdb.conf) >>/dev/null 2>&1 &
else
PROCESS_PID=`pidof -s influxd | awk '{print $1}'`
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "---kill influxd [pid $PROCESS_PID]"
pidof -s influxd | awk '{print $1}' | xargs kill -9
sleep 2
echo "----Restart influxd service[total $InstanceCount]."
(nohup $Cur_Dir/$influxdb_v/bin/influxd -config $Cur_Dir/$influxdb_v/influxdb.conf) >>/dev/null 2>&1 &
fi
PROCESS_NUM=`ps -ef | grep "grafana-server" | grep -v "grep" | wc -l`
if [ $PROCESS_NUM -lt $InstanceCount ];
then
StopCount=`expr $InstanceCount - $PROCESS_NUM `
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "----grafana service [total $StopCount] was not started."
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "----Starting grafana service[total $StopCount] ."
cd $Cur_Dir/$grafana_v/bin
(nohup ./grafana-server) >>/dev/null 2>&1 &
else
PROCESS_PID=`pidof -s grafana-server | awk '{print $1}'`
echo -n `date +'%Y-%m-%d %H:%M:%S'`
echo "---kill grafana-server [pid $PROCESS_PID]"
pidof -s grafana-server | awk '{print $1}' | xargs kill -9
sleep 2
echo "----Restart grafana service[total $InstanceCount]."
cd $Cur_Dir/$grafana_v/bin
(nohup ./grafana-server) >>/dev/null 2>&1 &
fi
sleep 2
Grafana作为一款轻量级的报表工具,功能还是很强大的,以下是我配置的指标效果图(有点花哨):

补充说明:
针对Jmeter的Backend Listener如果在implementation选项中选择第二项,我们将会得到不一样的监控效果:

重新配置一下参数:

再次发起测试,我们会发现influxDB的表结构出现了变化,变成单独创建一个总的jmeter表(原来的方式是一个统计指标创建一张表,会有很多张表):

这样的表信息量大,可以方便构建更直观的监控视图:

测试监控完全依赖端口的连通性,请确保2003和8086端口的通达,否则监控不到数据时,也不会有相关的报错提示。
需要软件测试资料的小伙伴,可以来加群:747981058。群内会有不定期的发放免费的资料链接,这些资料都是从各个技术网站搜集、整理出来的,如果你有好的学习资料可以私聊发我,我会注明出处之后分享给大家。