版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/amazingcode/article/details/85056197
- 使用多个特征而非单个特征来进一步提高模型的有效性
- 调试模型输入数据中的问题
- 使用测试数据集检查模型是否过拟合验证数据
#初始化,读取数据
from __future__ import print_function
import math
from IPython import display
from matplotlib import cm
from matplotlib import gridspec
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
from sklearn import metrics
import tensorflow as tf
from tensorflow.python.data import Dataset
tf.logging.set_verbosity(tf.logging.ERROR)
pd.options.display.max_rows = 10
pd.options.display.float_format = '{:.1f}'.format
california_housing_dataframe = pd.read_csv("https://download.mlcc.google.cn/mledu-datasets/california_housing_train.csv", sep=",")
#预处理特征
def preprocess_features(california_housing_dataframe):
selected_features = california_housing_dataframe[
["latitude",
"longitude",
"housing_median_age",
"total_rooms",
"total_bedrooms",
"population",
"households",
"median_income"]]
processed_features = selected_features.copy()
# Create a synthetic feature.
processed_features["rooms_per_person"] = (
california_housing_dataframe["total_rooms"] /
california_housing_dataframe["population"])
return processed_features
def preprocess_targets(california_housing_dataframe):
output_targets = pd.DataFrame()
# Scale the target to be in units of thousands of dollars.
output_targets["median_house_value"] = (
california_housing_dataframe["median_house_value"] / 1000.0)
return output_targets#特征处理前12000
training_examples = preprocess_features(california_housing_dataframe.head(12000))
training_examples.describe()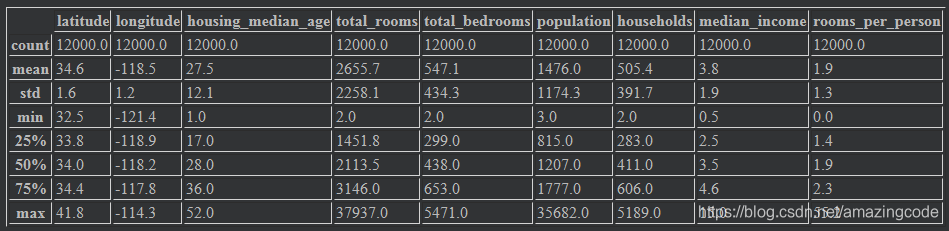
training_targets = preprocess_targets(california_housing_dataframe.head(12000))
training_targets.describe()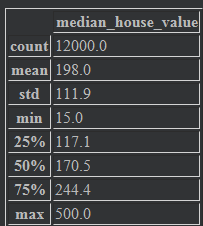
#抽取后5000个样本
validation_examples = preprocess_features(california_housing_dataframe.tail(5000))
validation_examples.describe()
validation_targets = preprocess_targets(california_housing_dataframe.tail(5000))
validation_targets.describe()
plt.figure(figsize=(13,8))#创建图像
ax=plt.subplot(1,2,1)#创建子图
ax.set_autoscaley_on(False)
ax.set_ylim([32,43])#y轴上下限
ax.set_autoscaley_on(False)
ax.set_xlim([-126,-112])
plt.scatter(validation_examples["longitude"],
validation_examples["latitude"],cmap=cm.coolwarm,
c=validation_targets["median_house_value"]/validation_targets["median_house_value"].max())
ax=plt.subplot(1,2,2)
ax.set_autoscaley_on(False)
ax.set_ylim([32,43])
ax.set_autoscaley_on(False)
ax.set_xlim([-126,-112])
plt.scatter(training_examples["longitude"],
training_examples["latitude"],cmap=cm.coolwarm,
c=training_targets["median_house_value"]/training_targets["median_house_value"].max())
_=plt.plot()
我们会发现训练集和验证集的分布分隔成了两部分,就像是把加州的地图给剪开了一样,这是因为我们在创建训练集和验证集之前没有对数据进行正确的随机化处理。
def my_input_fn(features,targets,batch_size=1,shuffle=True,num_epochs=None):
features={key:np.array(value) for key,value in dict(features).items()}
ds=Dataset.from_tensor_slices((features,targets))
ds=ds.batch(batch_size).repeat(num_epochs)
if shuffle:
ds.shuffle(10000)
features,labels=ds.make_one_shot_iterator().get_next()
return features,labels
def construct_feature_columns(input_features):
return set([tf.feature_column.numeric_column(my_feature) #生成的特征列
for my_feature in input_features])#训练模型
def train_model(
learning_rate,
steps,
batch_size,
training_examples,
training_targets,
validation_examples,
validation_targets):
periods = 10#周期数
steps_per_period = steps / periods#每个周期的步数
# Create a linear regressor object.
#创建一个线性回归
my_optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
my_optimizer = tf.contrib.estimator.clip_gradients_by_norm(my_optimizer, 5.0)
#配置线性回归模型
linear_regressor = tf.estimator.LinearRegressor(
feature_columns=construct_feature_columns(training_examples),
optimizer=my_optimizer
)
# Create input functions.
training_input_fn = lambda: my_input_fn(
training_examples,
training_targets["median_house_value"],
batch_size=batch_size)
predict_training_input_fn = lambda: my_input_fn(
training_examples,
training_targets["median_house_value"],
num_epochs=1,
shuffle=False)
predict_validation_input_fn = lambda: my_input_fn(
validation_examples, validation_targets["median_house_value"],
num_epochs=1,
shuffle=False)
# Train the model, but do so inside a loop so that we can periodically assess
# loss metrics.
print("Training model...")
print("RMSE (on training data):")
training_rmse = []
validation_rmse = []
for period in range (0, periods):
#继续训练模型,从上一次停止位置继续(停下来输出训练过程中的数据)
# Train the model, starting from the prior state.
linear_regressor.train(
input_fn=training_input_fn,
steps=steps_per_period,
)
# Take a break and compute predictions.
training_predictions = linear_regressor.predict(input_fn=predict_training_input_fn)
training_predictions = np.array([item['predictions'][0] for item in training_predictions])
validation_predictions = linear_regressor.predict(input_fn=predict_validation_input_fn)
validation_predictions = np.array([item['predictions'][0] for item in validation_predictions])
# Compute training and validation loss.
training_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(training_predictions, training_targets))
validation_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(validation_predictions, validation_targets))
# Occasionally print the current loss.
##打印当前计算的损失
print(" period %02d : %0.2f" % (period, training_root_mean_squared_error))
# Add the loss metrics from this period to our list.
training_rmse.append(training_root_mean_squared_error)
validation_rmse.append(validation_root_mean_squared_error)
print("Model training finished.")
# Output a graph of loss metrics over periods.
plt.ylabel("RMSE")
plt.xlabel("Periods")
plt.title("Root Mean Squared Error vs. Periods")
plt.tight_layout()
plt.plot(training_rmse, label="training")
plt.plot(validation_rmse, label="validation")
plt.legend()
return linear_regressor
#训练模型
linear_regressor = train_model(
learning_rate=0.00003,
steps=500,
batch_size=5,
training_examples=training_examples,
training_targets=training_targets,
validation_examples=validation_examples,
validation_targets=validation_targets)

#基于测试数据进行评估
#已对验证数据进行大量迭代,接下来确保没有过拟合该特定样本集特性
california_housing_test_data = pd.read_csv("https://download.mlcc.google.cn/mledu-datasets/california_housing_test.csv", sep=",")
test_examples=preprocess_features(california_housing_test_data)
test_targets=preprocess_targets(california_housing_test_data)
predict_test_input_fn=lambda:my_input_fn(
test_examples,test_targets["median_house_value"],
num_epochs=1,shuffle=False
)
test_predictions=linear_regressor.predict(input_fn=predict_test_input_fn)
test_predictions=np.array([item['predictions'][0] for item in test_predictions])
root_mean_squared_error=math.sqrt(metrics.mean_squared_error(test_predictions,test_targets))
print("Final RMSE (on test data):%0.2f"% root_mean_squared_error)