TCP协议对应于传输层,而HTTP协议对应于应用层,从本质上来说,二者没有可比性。Http协议是建立在TCP协议基础之上的,当浏览器需要从服务器获取网页数据的时候,会发出一次Http请求。Http会通过TCP建立起一个到服务器的连接通道,当本次请求需要的数据完毕后,Http会立即将TCP连接断开,这个过程是很短的。所以Http连接是一种短连接,是一种无状态的连接。所谓的无状态,是指浏览器每次向服务器发起请求的时候,不是通过一个连接,而是每次都建立一个新的连接。如果是一个连接的话,服务器进程中就能保持住这个连接并且在内存中记住一些信息状态。而每次请求结束后,连接就关闭,相关的内容就释放了,所以记不住任何状态,成为无状态连接。
随着时间的推移,html页面变得复杂了,里面可能嵌入了很多图片,这时候每次访问图片都需要建立一次tcp连接就显得低效了。因此Keep-Alive被提出用来解决效率低的问题。从HTTP/1.1起,默认都开启了Keep-Alive,保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。虽然这里使用TCP连接保持了一段时间,但是这个时间是有限范围的,到了时间点依然是会关闭的,所以我们还把其看做是每次连接完成后就会关闭。后来,通过Session, Cookie等相关技术,也能保持一些用户的状态。但是还是每次都使用一个连接,依然是无状态连接。
以前有个概念很容忍搞不清楚。就是为什么Http是无状态的短连接,而TCP是有状态的长连接?Http不是建立在TCP的基础上吗,为什么还能是短连接?现在明白了,Http就是在每次请求完成后就把TCP连接关了,所以是短连接。而我们直接通过Socket编程使用TCP协议的时候,因为我们自己可以通过代码区控制什么时候打开连接什么时候关闭连接,只要我们不通过代码把连接关闭,这个连接就会在客户端和服务端的进程中一直存在,相关状态数据会一直保存着。
HTTP/1.0和HTTP/1.1都把TCP作为底层的传输协议。HTTP客户首先发起建立与服务器TCP连接。一旦建立连接,浏览器进程和服务器进程就可以通过各自的套接字来访问TCP。如前所述,客户端套接字是客户进程和TCP连接之间的“门”,服务器端套接字是服务器进程和同一TCP连接之间的“门”。客户往自己的套接字发送HTTP请求消息,也从自己的套接字接收HTTP响应消息。类似地,服务器从自己的套接字接收HTTP请求消息,也往自己的套接字发送HTTP响应消息。客户或服务器一旦把某个消息送入各自的套接字,这个消息就完全落入TCP的控制之中。TCP给HTTP提供一个可靠的数据传输服务;这意味着由客户发出的每个HTTP请求消息最终将无损地到达服务器,由服务器发出的每个HTTP响应消息最终也将无损地到达客户
套接字(socket)是通信的基石,是支持TCP/IP协议的网络通信的基本操作单元。它是网络通信过程中端点的抽象表示,包含进行网络通信必须的五种信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程的协议端口。
应用层通过传输层进行数据通信时,TCP会遇到同时为多个应用程序进程提供并发服务的问题。多个TCP连接或多个应用程序进程可能需要通过同一个 TCP协 议端口传输数据。为了区别不同的应用程序进程和连接,许多计算机操作系统为应用程序与TCP/IP协议交互提供了套接字(Socket)接口。应用层可以 和传输层通过Socket接口,区分来自不同应用程序进程或网络连接的通信,实现数据传输的并发服务。
http协议的缺点:
- 通信使用明文(不加密),内容可能会被窃听
- 不验证通信方的身份,因此有可能遭遇伪装
- 无法证明报文的完整性,所以有可能已遭篡改
HTTPS 并非是应用层的一种新协议。只是 HTTP 通信接口部分用 SSL (安全套接字层)和TLS (安全传输层协议)代替而已。即添加了加密及认证机制的 HTTP 称为 HTTPS ( HTTP Secure )。
那么HTTP + 加密 + 认证 + 完整性保护 = HTTPS
那么https具体是怎么进行加密的?
1. 客户端发起HTTPS请求
这个没什么好说的,就是用户在浏览器里输入一个https网址,然后连接到server的443端口。http的默认端口是80
2. 服务端的配置
采用HTTPS协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面(startssl就是个不错的选择,有1年的免费服务)。这套证书其实就是一对公钥和私钥。如果对公钥和私钥不太理解,可以想象成一把钥匙和一个锁头,只是全世界只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。
3. 传送证书
这个证书包含了很多信息,如证书的颁发机构,过期时间,还有需要进行加密的公钥等等。
4. 客户端解析证书
这部分工作是有客户端的TLS来完成的,首先会验证证书是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随机值。然后用证书中的公钥对该随机值进行加密。就好像上面说的,把随机值用锁头锁起来,这样除非有钥匙,不然看不到被锁住的内容。
5. 传送加密信息
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。
6. 服务段解密信息
服务端用私钥解密后,得到了客户端传过来的随机值(私钥),然后把内容通过该值进行对称加密。所谓对称加密就是,将信息和私钥通过某种算法混合在一起,这样除非知道私钥,不然无法获取内容,而正好客户端和服务端都知道这个私钥,所以只要加密算法够彪悍,私钥够复杂,数据就够安全。
7. 传输加密后的信息
这部分信息是服务段用私钥(这个私钥是客户端刚才传输过来的)加密后的信息,可以在客户端被还原。
8. 客户端解密信息
客户端用之前生成的私钥(就是那一串随机数)解密服务段传过来的信息,于是获取了解密后的内容。整个过程第三方即使监听到了数据,也束手无策。
1. 对称加密
对称加密指的就是加密和解密使用同一个秘钥,所以叫做对称加密。对称加密只有一个秘钥,作为私钥。
常见的对称加密算法:DES,AES,3DES等等。
2. 非对称加密
非对称加密指的是:加密和解密使用不同的秘钥,一把作为公开的公钥,另一把作为私钥。公钥加密的信息,只有私钥才能解密。私钥加密的信息,只有公钥才能解密。
常见的非对称加密算法:RSA,ECC
http 请求报文格式
HTTP请求报文主要由请求行、请求头部、请求正文3部分组成
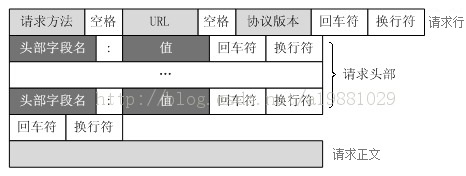
1,请求行
由3部分组成,分别为:请求方法、URL(见备注1)以及协议版本,之间由空格分隔
请求方法包括GET、HEAD、PUT、POST、TRACE、OPTIONS、DELETE以及扩展方法,当然并不是所有的服务器都实现了所有的方法,部分方法即便支持,处于安全性的考虑也是不可用的
协议版本的格式为:HTTP/主版本号.次版本号,常用的有HTTP/1.0和HTTP/1.1
2,请求头部
请求头部为请求报文添加了一些附加信息,由“名/值”对组成,每行一对,名和值之间使用冒号分隔
常见请求头如下:
请求头 |
说明 |
Host |
接受请求的服务器地址,可以是IP:端口号,也可以是域名 |
User-Agent |
发送请求的应用程序名称 |
Connection |
指定与连接相关的属性,如Connection:Keep-Alive |
Accept-Charset |
通知服务端可以发送的编码格式 |
Accept-Encoding |
通知服务端可以发送的数据压缩格式 |
Accept-Language |
通知服务端可以发送的语言 |
请求头部的最后会有一个空行,表示请求头部结束,接下来为请求正文,这一行非常重要,必不可少
3,请求正文
可选部分,比如GET请求就没有请求正文
HTTP响应报文主要由状态行、响应头部、响应正文3部分组成

1,状态行
由3部分组成,分别为:协议版本,状态码,状态码描述,之间由空格分隔
状态代码为3位数字,200~299的状态码表示成功,300~399的状态码指资源重定向,400~499的状态码指客户端请求出错,500~599的状态码指服务端出错(HTTP/1.1向协议中引入了信息性状态码,范围为100~199)
这里列举几个常见的:
状态码 |
说明 |
200 |
响应成功 |
302 |
跳转,跳转地址通过响应头中的Location属性指定(JSP中Forward和Redirect之间的区别) |
400 |
客户端请求有语法错误,不能被服务器识别 |
403 |
服务器接收到请求,但是拒绝提供服务(认证失败) |
404 |
请求资源不存在 |
500 |
服务器内部错误 |
2,响应头部
与请求头部类似,为响应报文添加了一些附加信息
常见响应头部如下:
响应头 |
说明 |
Server |
服务器应用程序软件的名称和版本 |
Content-Type |
响应正文的类型(是图片还是二进制字符串) |
Content-Length |
响应正文长度 |
Content-Charset |
响应正文使用的编码 |
Content-Encoding |
响应正文使用的数据压缩格式 |
Content-Language |
响应正文使用的语言 |
1,URI、URL和URN之间的区别
URI全名为Uniform Resource Indentifier(统一资源标识),用来唯一的标识一个资源,是一个通用的概念,URI由两个主要的子集URL和URN组成
URL全名为Uniform Resource Locator(统一资源定位),通过描述资源的位置来标识资源
URN全名为Uniform Resource Name(统一资源命名),通过资源的名字来标识资源,与其所处的位置无关,这样即使资源的位置发生变动,其URN也不会变化
HTTP规范将更通用的概念URI作为其资源标识符,但是实际上,HTTP应用程序处理的只是URI的URL子集