正则 就是一条规则 用来检验字符串的格式 目标就是字符串
只要是通过表单提交的数据 都是字符串
1.正则定义
var reg = new RegExp( )
var reg = /格式/ <--简写
2.正则的方法
两大功能:一个是匹配 匹配成功就是true 第二个是捕获 如果有就拿出来
test( ) 用于匹配
exec( ) 用于捕获 直接返回捕获的对象 没捕获到就是null
3.正则修饰符 如何去匹配
①区不区分大小写 “i”代表忽略大小写
②全局 “g”代表全局匹配
③“m”代表多行匹配
4.修饰符使用方法:
var reg = new RegExp("hello",g)
var reg = /hello/g <-- 简写
5.字符串中有关正则的方法 跟正则有关
①match( ) 查找一个或多个与正则相匹配的文本 有返回值就是查找的结果 没有就是null
②search( ) 匹配和正则相同的字符 有就返回索引 没有就是-1
③replace( ) 匹配与正则相同的 并替换掉 返回结果是替换后的字符串 -->st.replace("hello","hahaha")
6.正则的方括号[ ]
[abc] 代表查找方括号中的任何字符
[^abc] 代表查找任何一个不在方括号之间的字符
[0-9] 查找任何从0到9的数字
[a-z] 查找任何从小写 a 到小写 z 的字符
[A-Z] 查找任何从大写 A 到大写 Z 的字符
[A-z] 查找任何从大写 A 到小写 z 的字符
[adgk] 查找给定集合内的任何字符
[^adgk] 查找给定集合外的任何字符
(red|blue|green) 查找任何指定的选项
7.元字符
. 代表单个字符
\w 代表单词字符 包含了数字 字母 下划线
\W 代表非单词字符 除了数字 字母 下划线
\d 代表数字
\D 代表非数字
\s 代表空白字符
\S 代表非空白字符
\b 匹配单词边界 -->字符串两端必须是单词
\B 匹配非单词边界
\0 代表null字符
8.量词
n+ 代表至少 1 个n的字符
n* 代表 0 个或多个n
n? 代表包含 0 个或 1 个n
n{x} 代表包含 x 个n
n{x,} 代表包含至少x个n
n{x,y} 代表大于等于x个小于等于y个n
n$ 代表包含以n结尾的字符串
^n 代表包含以n开头的字符串
?=n 指定字符串后面紧跟的n的字符串 返回结果不带n
↓↓
var str="Is this all there is";
var patt1=/is(?= all)/; //返回is
^ <-- 尖角号
正则的理解:
1.正则的懒惰性

每一次在exec( ) 中捕获的时候 只捕获第一次匹配的内容 而不往下捕获了 我们把这种功能叫正则的懒惰性
每一次捕获的开始位置都是从 0 开始
解决正则的懒惰性 -- > 在正则后面加个g 并且控制台输出多次
2.正则的贪婪性
每一次匹配都是按照最长的出结果 我们把这种功能叫正则的贪婪性

解决正则的贪婪性 -- > 在元字符量词后面加 ? 号 / \d+? /g
正则的捕获
1.普通捕获exec( ) < -- > 2.match( ) 就是对exec的一个包装
普通捕获有懒惰性 给正则添加一个修饰符g可以解决 match 是将所有捕获的内容放到一个数组中并返回
match就是对exec的一个简单的封装
3.分组捕获 捕获的方法还是exec( ) 和 match( ) 正则在结构上发生了变化 加( )了
例子:var reg = / (a) (b) / -- > 返回ab a b
非全局下:
exec( )和match( )在非全局下分组捕获是相同的 在捕获的过程中即捕获大正则里的内容
也捕获分组中的内容 并都返回

全局下:
例子:var reg = / (a) (b) /g -- > exec返回ab a b match返回ab
exec( )和match( )在全局下的分组捕获是不一样的 exec( )不变 但是match( )只捕获大正则里的内容

4.分组捕获的优势
①可以提升优先级
②可以捕获引用
\1 代表分组1里面的内容 \2 代表分组2里面的内容
前提是分组必须在引用之前 如果 \2 在分组的前面代表普通的表达式
5.分组的结果存在正则类 RegExp 和 $number 属性下
\1 和 RegExp.$1 二者都是分组引用
\1 只能使用在正则表达式里面 RegExp.$1可以外面使用 都是在捕获完成的条件下
6.在捕获的过程中怎么取消捕获分组中的内容
在分组的前面加上 ?: 就可以了
?:和?=的区别
?:就是取消分组中的内容的
而?= 例子:var reg = /a(?=b)/ var st = "ab" 捕获字符a后面紧跟b的 并且只返回a
replace
replace是字符串的一个方法 他有两个参数 用后者将前者替换掉 并返回一个新的字符串 但是没有改变原字符串
1.如果第一个参数是字符串 只改变一次
2.如果第一个参数是正则 捕获一次改变一次
3.如果第二个参数是匿名函数 每捕获一次 执行一次 return的是什么 那就替换什么
这个匿名函数的arguments有三个元素
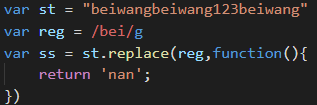
replace案例1: "beiwangbeiwang123beiwang" -- > "nanwangnanwang123nanwang"
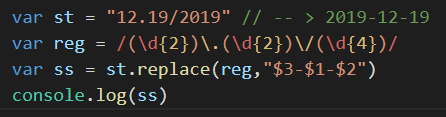
replace案例2:日期格式 "12.19/2019" -- > "2019-12-19"
replace案例3:屏蔽关键字 "双十一是京东的活动" -- > " ***是京东的** "

正则小案例:



