词频是什么?
词频是一篇文章中每个单词的出现频数统计量
为什么要统计词频?
大体而言,一篇文章的主要内容可以从其中出现次数较多中的词语获知,大致内容也就类似一篇论文中的“关键字”吧,可以让人预先了解到文章的主要内容方向
词频该如何表现?
用表格表现?不,文字和数字在视觉上并不能有很好的表现。所以这就引出了我这篇博客的主要内容“词云”
怎么制作一个词云?
问题一: 要安装哪些包?
对于英文我们可以很好的通过空格将每个单词拆分开来,比如说“Hi , i’m steven. nice to meet you ”,学过一点点编程的朋友都会将其拆成HI 、i‘m 、steven、nice 、to 、meet 、you,然而中文就行不通了。“你好,我是史蒂芬,很高兴见到你”,你是一个字一个字的拆开(那样就失去了我们原本的目的意义)?还是拆成 “我是史 蒂芬 很高 兴见到 你”?如何正确的将语句拆分成我们日常习惯的词语是一大难点。因此这里我们用了一个名叫Rwordseg的包,当然安装此包时还得提前安装rJava包,此外我们还需安装wordcloud2包进行词云图绘制。
rJava链接: https://cran.r-project.org/web/packages/rJava/index.html 这个直接在R中install可能会出错,所以最好下下来本地安装
Rwordseg链接: http://jianl.org/cn/R/Rwordseg.html 也可直接在R中install
wordcloud2链接: 直接在R中install就好啦
问题二: 安装rJava包时有问题?
必要1:因为rJava是R与java之间的通道,所以你的电脑上必须要有jdk,且jdk位数、R的位数与电脑操作系统位数一致
必要2:保证java的环境变量配置正确,这里我就不详解,相信编程人员都会java的环境配置
必要3:在R中配置java_home环境变量:Sys.setenv(JAVA_HOME=’路径’)
问题三: 如何分词?
对于英文:
英文的话就不需要去特殊分词了,直接以空格为基准拆分文本就好了
对于中文:
这里使用Rwordseg包中的segmentCN函数
segmentCN(strwords =数据)
如果strwords是一个文件路径的话,则在相应路径下生成一个名字添加.segments的文件,该文件为分词后的数据文件。例如:strwords=“f:/text.txt”,则运行函数后会生成“f:/text.segments.txt”。输出文件的路径也可以通过参数outfile来重定向。
如果strwords是一串带分词的字符的话,那么函数直接返回分词后的内容。
问题四: 分词后数据该转化为什么格式呢?
当然是data.frame啊,其主要形式为:
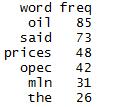
其一列为词,一列为该词的出现频数
问题五: 怎么画词云?
这里使用wordcloud2包中的wordcloud2函数
wordcloud2(data,size,color,backgroundColor,shape,figPath)
1)data即为我们问题四中的data.frame
2)size可以控制绘画出来的词云的大小
3)color为词云中词语的颜色,可为某特定颜色,也可为包中自带的“random-dark”(随机暗色)或者“random-light”(随机亮色)。这里应注意,在暗色背景中前景应为亮色,反之亦反。
4)backgroudColor为词云中的背景颜色
5)shape为词云的大致形状:默认为‘circle’,也可以为‘cardioid’、‘diamond’、‘triangle-forward’、‘’triangle’、 ‘pentagon’、’star’。
6)figPath为词云的自定义形状:可以自己绘制一张以黑色为主要区域其他地方透明的图片为词云形状,在使用自定义形状时需将图片反置在wordcloud2包中的examples文件夹中,然后:
figPath<-system.file(“examples/×××.png”,package = “wordcloud2”)即可在博客的最后我提供了几张自己制作的图片,朋友们任意使用也可以自行创造:
问题六: 博主,看起好麻烦呀,能不能爽快的给个函数?
of course~本着博主一向伟大的精神,只要能够帮助到大家,代码什么的好说好说(中英文本通用)
wordCloud<-function(file , encoding = 'ANSI' , language = 'chinese', filter = filterWords, ...){
composition<-readLines(con = file,encoding = encoding)#读取文本
composition<-paste0(composition,collapse = ' ')#粘合每一行
if (tolower(language) == 'chinese'){
composition<-segmentCN(strwords = composition)#进行分词
wordsFreq<-data.frame(table(composition))#建立data.frame
wordsFreq[,1]<-as.character(wordsFreq[,1])#转化为character类型
wordsFreq<-wordsFreq[-which(nchar(wordsFreq[,1])<2),]#过滤单个字的词频
}
else if(tolower(language) == 'english'){
composition<-gsub("[^a-zA-Z]"," ",composition)#除去非字母字符
composition<-tolower(composition)#转化为小写
composition<-strsplit(x = composition,split = ' ')#以空格为参考拆分
wordsFreq<-data.frame(table(composition))#建立data.frame
wordsFreq[,1]<-as.character(wordsFreq[,1])#转化为character类型
wordsFreq<-wordsFreq[-which(nchar(wordsFreq[,1])<3),]#过滤词频
temp<-apply(wordsFreq, 1, function(x){
if (length(grep(pattern = x[1],x = filter)) == 1)
return(FALSE)
else
return(TRUE)
})
wordsFreq<-wordsFreq[temp,]
}else{
return(0)
}
wordsFreq<-wordsFreq[order(wordsFreq[,2],decreasing = T),]#给词频排序
wordcloud2(data = wordsFreq , ...)
}
问题七: 博主你丫的说了半天,能不能来点样品效果展示啊?
瞧你们一个个急的~好嘞,这就来:
针对本篇博客的词云图

针对2000年到2016年国内研究生英语考试的所有真题试卷的词云图
针对天宫二号百度百科的词云图

问题八: 画出来的词云老是显示一些没有意义的词咋办?
对于英文:
由于英文中存在大量的虚词(连词、介词、冠词、语气词),所以在对英文文本进行词频统计时本人会针对这些虚词进行过滤,以下是我选出来的过滤参考文本
a about above across after ahead all along also although am among an and any are arong as at because been before begin behind below beneath besid beside besides best between beyond but by can close could down due during each even except far finally first firstly for fore form from front further furthermore get had has have he hence her hers him his how however in into is it its just last like likewise made make many may me means mine more moreover most my near neither nevertheless next nor not now of off on one only or other otherwise our ours out over owing own past rather result second secondly she should since so some still such take than that the their theirs them then there therefore therfore these they third thirdly this those though through thus to too under until upon us use very was we well were what when which while who will with within without would yet you your yours few much
在问题六中function有一个参数为filterWords,其中我默认为以上这个过滤参考文本
对于中文:
中文就比较好过滤啦,仅仅只需要将一个字的词给过滤掉就OK了,因为大部分一个字的词对词云都没有太大意义嘛
一些本人制作的词云背景图,请随意使用