概述:
聚类是数据挖掘算法中比较重要的一个“帮派”,属于典型的无监督学习(机器学习算法可分为两类:有监督学习和无监督学习。通俗的讲有监督学习是指算法事先需要部分训练集进行算法训练,以达到模型的建立或权值的最优,后将测试集对由训练集构成的最优模型进行测试,其结果往往是明确的;而无监督学习最突出的特点就是无需训练集进行算法训练而可以直接将数据达到某种效果,其结果往往是不明确的)。聚类算法虽然多种多样,但其效果都是根据对象的特征行为方式的异同进行局簇归类,相似的对象为一类,相异的自然“天各一方”了。
K-Means算法算是众多聚类算法中最简单的一个了,其用我们所熟知的欧氏距离来描述对象间特征行为的相似度,距离越近相似度越高,反之越低。
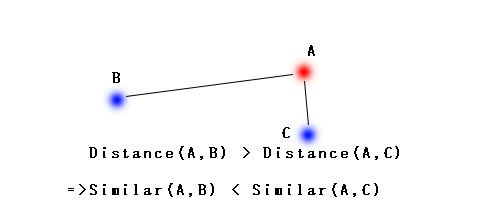
有人就会问了:“对象的特征怎么转换成距离嘞?”。其实不难,比方说面前有一筐水果,里面有若干个梨和若干个草莓,该如何将他们分开呢?我相信大家都能很容易根据它们的颜色、个头等性状将梨和草莓分堆,但是对于机器该怎么办?这个时候机器就应该将这框筐水果里每个对象的特征采集如下(实际特征较多,这里只列举颜色和质量两个较为明显的特征):
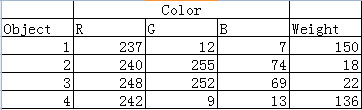
瞧,这不就转化了么。object1 = (237,12,7,150)、object2 = (240,255,74,18)……把这个当作四维空间的坐标就能计算对象间的欧式距离了。当然,这里的RGB三个数据同时表示颜色一个特征,相对于质量用一个数据表示来说,颜色对整个对象的影响将会是质量的三倍,所以我们在此可以调整RGB的权值,使其权值和为1(在图像灰度化中RGB三个的权值分别为0.3、0.51、0.19),这样颜色和质量对整个对象的影响就一致了。
前面简单介绍了聚类算法的概念和特征与坐标值的转化,下面开始真正讲解K-Means算法的过程(由于多维空间无法展示,所以我只在二维平面上进行算法描述)。
流程:
1. 步骤一:
首先在二维平面上随机产生你需要分类数的簇中心点(分类总数由人为设定),其随机范围是能够包围所有对象的最小矩形。

2. 步骤二:
然后针对每一个对象点计算其到各簇中心点的欧式距离,选择最短距离的簇中心点为自己的归属簇,那么第一轮将产生如下归属

3. 步骤三:
各簇中心点拥有了属于自己的对象点后重新计算其坐标值,计算方法自然是计算所有属于自己的对象点坐标的均值了(所以叫K-Means嘛)。Xcenter<-mean(X1,X2,…,Xn) , Ycenter<-mean(Y1,Y2,…,Yn)。

4. 步骤四:
重复步骤二、三进行迭代,直至簇中心点稳定、坐标未发生改变,即各簇中心点所拥有的对象点不发生改变,到此K-Means算法完成了全部的运算,属于同一个簇的对象点属于同一类。顺带提一句,还有一种叫K-Median的聚类算法,其实过程与K-Means算法一样,只不过在计算簇中心点时是采用中位数来计算罢了。
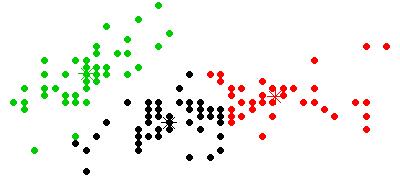
5. 流程可视化:

改进:
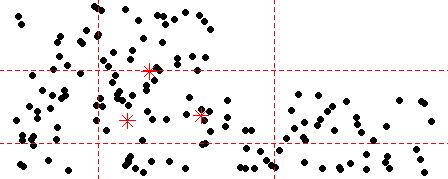
在步骤一中,若干个簇中心点是随机产生的,那么将有可能出现以下这种情况:

在这种情况下,由于存在簇中心点初始位置较为偏离,它与所有对象点的距离都没有其他簇中心点与对象点的距离近,那么在迭代的第一轮将发生以下分类:

那些初始位置较为偏离的簇中心点因为得不到归属自己的对象点而即将“消失”,这样分出来的类很明显违背了我们的本意。对此我的解决想法是尽量将簇中心点间的初始位置差距不大,且合理存在于对象点之中,不让任何一个簇中心点的初始位置偏离对象点群,这样在第一轮迭代中每一个簇中心点都能因为拥有自己的对象点而“长存”。解决的办法是缩小簇中心点位置初始化的随机范围,范围由原来每一维度的min~max减小到Q1(第一四分位数)~Q3(第三四分位数)。

||
||
||
\/
————————————————————————————————————————————————-
三维空间中的聚类效果:

————————————————————————————————————————————————-
代码:
以下是R代码(我曾经用java写了400行,而R只用了不到30行)
K_means<-function(data,classification){
if(class(data) == 'data.frame') ##数据类型转换
data<-as.matrix(data)
centers<-apply(data, 2,FUN = function(x){ ##随机参数簇中心
return(runif(n = classification,min = quantile(x,0.25),max = quantile(x,0.75)))
})
while(TRUE){ ##计算各点归属的簇中心
clone<-centers ##用于与新簇中心比对观察是否迭代完全
rownames(data)<-apply(data, 1, FUN = function(x1){
dis<-apply(centers, 1, FUN = function(x2){
return(dist(matrix(data = c(x1,x2),nrow = 2,byrow = T)))
})
return(which(dis == min(dis)))
})
for(i in 1:classification){ ##重新计算簇中心
centers[i,]<-apply(data[which(rownames(data) == i),], 2, mean)
}
if(length(which(c(centers == clone) == 'FALSE')) == 0) ##若簇中心点不变,则计算完成,停止迭代
break
}
return(list(centers = centers,data = data,classification = classification)) ##返回簇中心点、归类信息及分类数
}