


虽然这种事情也不是什么稀罕事吧,但是 Instagram 上这么干的人挺多的,甚至有人专门写机器人干这个事儿。大受刺激之下,我决定自己也写个这样的机器人。

这个项目会用到 Python 和一些工具,比如 Selenium。简单说,Selenium 就像一个浏览器,你可以很容易地用 Python 与之互动。进群:960410445 大牛答疑,资源互相!



我的 Instagram 相册里有多种风格的内容,从街景照片到太空图像均有涉及,还有些旅行照片。另外我平时也会发一些我的家乡里斯本的照片。总之,这个 Instagram 机器人会使用这些话题作为目标标签。
当然我们这里不是说的那种一天就涨几千粉的机器人,没那么大野心。
刚开始,我让这个机器人根据几个不同的标签运行了几次,比如“travelblogger”“travelgram”“Lisbon”这些标签。运行了大概三天,账号粉丝从 380 涨到了 800 个,还收获了大量点赞和评论,甚至有不少粉丝并不是被我“套路”过来的(主动关注我,不是被机器人账号关注后的回粉)。

在 Instagram 上增加关注者的最有效方法(除了发布高质量内容以外)就是去关注别人,等人回粉。在这方面,机器人很适合干这个活,又不用人工操作,哪怕关注 2000 人只有 200 人回粉,那也是划算的。
机器人会将它运行期间关注的所有用户保存成一个列表,以便后期我能根据这个列表搞点事情。比如,我可以查看每个用户的主页,看看他们发的内容怎样,有多少粉丝,然后决定要不要继续关注他们。或者也可以获取这些人账号发布最新一张照片的时间,看看他们是不是活跃用户。
如果我们移除机器人的“关注”操作,就会发现粉丝增长率大跌,因为很少有人会根据你给他点个赞或写了条评论就关注你。
机器人程序
机器人的脚本不是很复杂,还有很大的优化空间,但是的确有效果。
你需要用到 Python(我用的 Python 3.7),Selenium,浏览器(我用的 Chrome)以及一个 Instagram 账号。机器人的大致流程为:
- 打开浏览器,登入账号
- 对于标签列表中的每个标签,机器人会打开页面,点击第一张照片,然后点赞、关注、评论三连操作,接着移到下一张照片,重复同样的操作。大概会循环200次,数字可以调整。
- 用机器人将关注的所有用户保存为一个列表
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from time import sleep, strftime
from random import randint
import pandas as pd
chromedriver_path = 'C:/Users/User/Downloads/chromedriver_win32/chromedriver.exe' # Change this to your own chromedriver path!
webdriver = webdriver.Chrome(executable_path=chromedriver_path)
sleep(2)
webdriver.get('https://www.instagram.com/accounts/login/?source=auth_switcher')
sleep(3)
username = webdriver.find_element_by_name('username')
username.send_keys('your_username')
password = webdriver.find_element_by_name('password')
password.send_keys('your_password')
button_login = webdriver.find_element_by_css_selector('#react-root > section > main > div > article > div > div:nth-child(1) > div > form > div:nth-child(3) > button')
button_login.click()
sleep(3)
notnow = webdriver.find_element_by_css_selector('body > div:nth-child(13) > div > div > div > div.mt3GC > button.aOOlW.HoLwm')
notnow.click() #comment these last 2 lines out, if you don't get a pop up asking about notifications
要想通过 Selenium 使用 Chrome,你需要安装 Chromedriver。过程很简单,没什么可说的。安装并替换上面的路径,然后变量 webdriver 就会变成我们的 Chrome 标签。
在第三段代码中,应该用你自己的用户名和密码代替字符串,用于让机器人将其输入显示的字段中。你或许已经注意到,运行第二段代码时,Chrome 会打开新的标签。在密码之后,我将登录按钮定义为一个对象,在下一行中点击它。
至于那些看着有点怪异的字符串,其实要做的事很容易,点击你想映射的元素,选择“Inspect”即可。
待你打开“检查”模式,找到对应你想映射的内容的 HTML 代码。点击后将鼠标悬停在“Copy”上,会发现出现了一些选项,让你选择怎么复制。我使用的是 XPath 和 css 选择器通过代码复制(find_element_method中)。花了我好长一会儿才让所有的引用流畅运行。有时 css 或 xPath 方向会出错,调整 sleep 次数后会好很多。
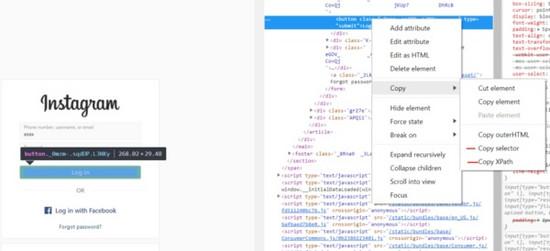
这里我选择“copy selector”后将其粘贴在 find_element_method 中(第三段代码中)。然后会得到它找到的第一个结果。如果是 find_elements_,或检索所有元素,你可以指定要哪些。
完成之后,开始循环。在 hashtag_list 中添加更多的标签。如果是第一次运行,并没有包含你所关注的用户的文件,所以可以创建一个空列表 prev_user_list。
等运行它时,程序会保存一个带有时间戳、包含机器人所关注的用户的 CSV 文件。该文件在第二次运行程序时变为 prev_user_list。追踪机器人做了哪些事情很容易也很简单。
在后续运行终以最新的时间戳进行更新,会得到一系列的 CSV 文件,对应机器人的每一次运行。
hashtag_list = ['travelblog', 'travelblogger', 'traveler']
# prev_user_list = [] - if it's the first time you run it, use this line and comment the two below
prev_user_list = pd.read_csv('20181203-224633_users_followed_list.csv', delimiter=',').iloc[:,1:2] # useful to build a user log
prev_user_list = list(prev_user_list['0'])
new_followed = []
tag = -1
followed = 0
likes = 0
comments = 0
for hashtag in hashtag_list:
tag += 1
webdriver.get('https://www.instagram.com/explore/tags/'+ hashtag_list[tag] + '/')
sleep(5)
first_thumbnail = webdriver.find_element_by_xpath('//*[@id="react-root"]/section/main/article/div[1]/div/div/div[1]/div[1]/a/div')
first_thumbnail.click()
sleep(randint(1,2))
try:
for x in range(1,200):
username = webdriver.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/article/header/div[2]/div[1]/div[1]/h2/a').text
if username not in prev_user_list:
# If we already follow, do not unfollow
if webdriver.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/article/header/div[2]/div[1]/div[2]/button').text == 'Follow':
webdriver.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/article/header/div[2]/div[1]/div[2]/button').click()
new_followed.append(username)
followed += 1
# Liking the picture
button_like = webdriver.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/article/div[2]/section[1]/span[1]/button/span')
button_like.click()
likes += 1
sleep(randint(18,25))
# Comments and tracker
comm_prob = randint(1,10)
print('{}_{}: {}'.format(hashtag, x,comm_prob))
if comm_prob > 7:
comments += 1
webdriver.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/article/div[2]/section[1]/span[2]/button/span').click()
comment_box = webdriver.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/article/div[2]/section[3]/div/form/textarea')
if (comm_prob < 7):
comment_box.send_keys('Really cool!')
sleep(1)
elif (comm_prob > 6) and (comm_prob < 9):
comment_box.send_keys('Nice work :)')
sleep(1)
elif comm_prob == 9:
comment_box.send_keys('Nice gallery!!')
sleep(1)
elif comm_prob == 10:
comment_box.send_keys('So cool! :)')
sleep(1)
# Enter to post comment
comment_box.send_keys(Keys.ENTER)
sleep(randint(22,28))
# Next picture
webdriver.find_element_by_link_text('Next').click()
sleep(randint(25,29))
else:
webdriver.find_element_by_link_text('Next').click()
sleep(randint(20,26))
# some hashtag stops refreshing photos (it may happen sometimes), it continues to the next
except:
continue
for n in range(0,len(new_followed)):
prev_user_list.append(new_followed[n])
updated_user_df = pd.DataFrame(prev_user_list)
updated_user_df.to_csv('{}_users_followed_list.csv'.format(strftime("%Y%m%d-%H%M%S")))
print('Liked {} photos.'.format(likes))
print('Commented {} photos.'.format(comments))
print('Followed {} new people.'.format(followed))
代码很简单,如果熟悉 Python,很快就能看懂。
通过循环内的 Print 语句,我可以追踪所有时间内机器人处在哪个循环内。它会打印出机器人所在的标签,循环次数以及为“评论”操作生成的随机数。我决定不让机器人在每个页面都评论,所以添加了三个不同的评论,以及一个位于 1 到 10 之间的随机数定义评论数量。循环结束后,将新关注的用户添加到之前的用户“数据库”中,使用时间戳保存新文件。
就是这些了。
运行了大概 4 天后,我的 Instagram 账号增加了大约 500 个新粉丝,仅仅几天就将粉丝翻倍。后续我会接着观察粉丝数的增长状况会不会滑落。
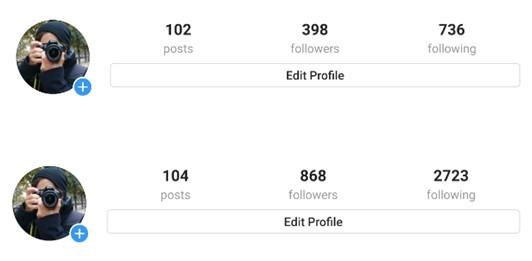
大家也可以根据我这个思路打造自己的增粉机器人。