RDD依赖关系
之前,我们有谈到过RDD的五大特性。其中一个就是:RDD有一系列的依赖关系,依赖于其他的RDD。RDD依赖关系根据partition之间的关系划分为窄依赖和宽依赖。
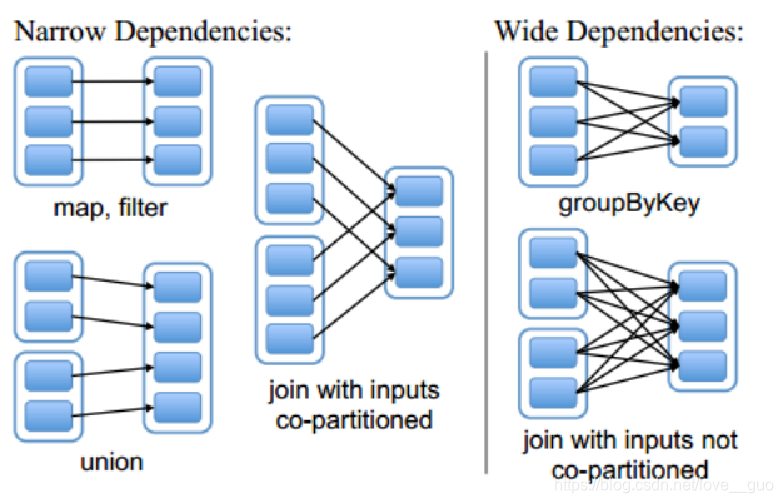
1.窄依赖
如果父RDD与子RDD,partition之间的关系是一对一,那么我们就称这种RDD的依赖关系是窄依赖。这种依赖之间不会发生shuffle。
上图中,map,filter,union,join with inputs co-partitioned过程就是窄依赖。
2.宽依赖
如果父RDD与子RDD,partition之间的关系是一对多,那么我们就称这种RDD的依赖关系是宽依赖。一般来说,宽依赖会导致shuffle
上图中,groupByKey,join with inputs not co-partitioned过程就是宽依赖。
默认情况下,groupByKey返回的RDD的区数与父RDD是一致的,如果你在使用groupByKey的时候,传入一个int类型的值,此时返回的RDD的区数就是这个值。
3.宽窄依赖的作用
将job切割成一个个的stage。
DAG有向无环图
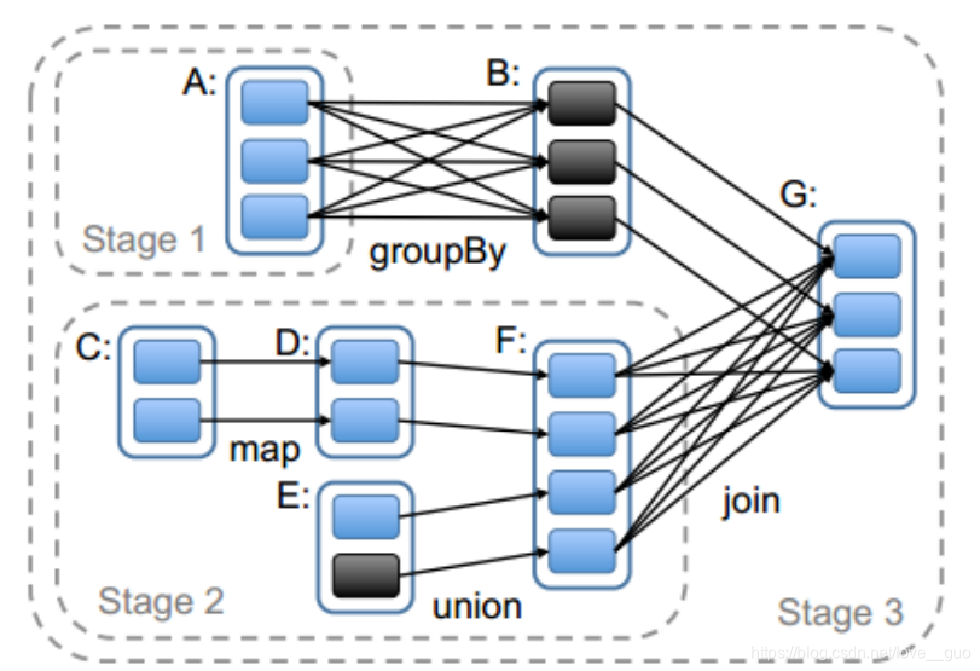
Q:为什么要将job切割成stage?
A:因为stage与stage之间是宽依赖,有shuffle;stage内部之间是窄依赖,没有shuffle。而shuffle阶段会将数据落地(将数据写入到磁盘中)
Q:为什么shuffle write阶段必须要写磁盘呢?
A:防止reduce task拉去数据失败。
Q:形成一个DAG有向无环图,为什么需要从最后一个RDD向前回溯?
A:RDD的五大特性中有一个是RDD有一系列的依赖关系,依赖于其他的RDD。而这种依赖关系是子RDD知道父RDD,而父RDD不知道子RDD。所以需要从后往前回溯。
Pipeline计算
MapReduce的计算模式是:1+1=2 2+1=3
Spark的计算目是是:1+1+1=3

上图中task计算模式就是pipeline的计算模式。
task0:这条线所贯穿的partition中的计算逻辑,并且已递归函数展开式的形式整合在一起,fun2(fun1(textFile(b1)))最好是发送到b1以及b1副本所在的节点。存储集群最好包含计算集群。
Q:stage中每一个task(管道计算模式)在什么时候会落地磁盘?
A:1).如果stage后面是action类算子
collect:将每一个管道的计算结果收集到Driver端的内存中
saveAsTextFile:将每一个管道的计算结果写到指定目录
count:将管道的计算结果统计记录数,返回给Driver
2).如果stage后面是stage
在shuffle write节点会写磁盘。
Q:spark计算过程中,是不是非常消耗内存?
A:并不是,虽然Spark集群是基于内存计算的,但是由于RDD是存储的计算逻辑,并不存储真实的数据。
Q:spark计算过程中,什么样的场景最耗内存?
A:当有控制类算子的时候,cache(),persist()
Q:如果管道中有cache逻辑,那么cache是如何缓存数据的?
A:我们可以将管道想象成一个水管,当这个水管经过cache算子的时候,会破一个小口,将水存储到池子中。而水管中水并不会少,而池子中的水却变多了。
Q:RDD弹性分布式数据集,既然RDD中不存储数据,那么为什么还依然叫数据集?
A:虽然RDD中不存储数据,但是RDD具有操作数据的能力。