# 前期实际留存率数据
(day <- seq(1:7)) # 天数
(ratio <- c(0.392,0.278,0.196,0.166,0.106,0.096,0.046)) # 留存率值
# 利用nls函数求出幂指数函数y=a*x^b的系数a、b
fit <- nls(ratio~a*day^b,start = list(a=1,b=1))
# 查看模型结果
summary(fit)
# 对新增用户在接下来365日每天的留存率进行预测
predicted <- predict(fit,data.frame(day=seq(1,365)))
# 查看预测结果
predicted
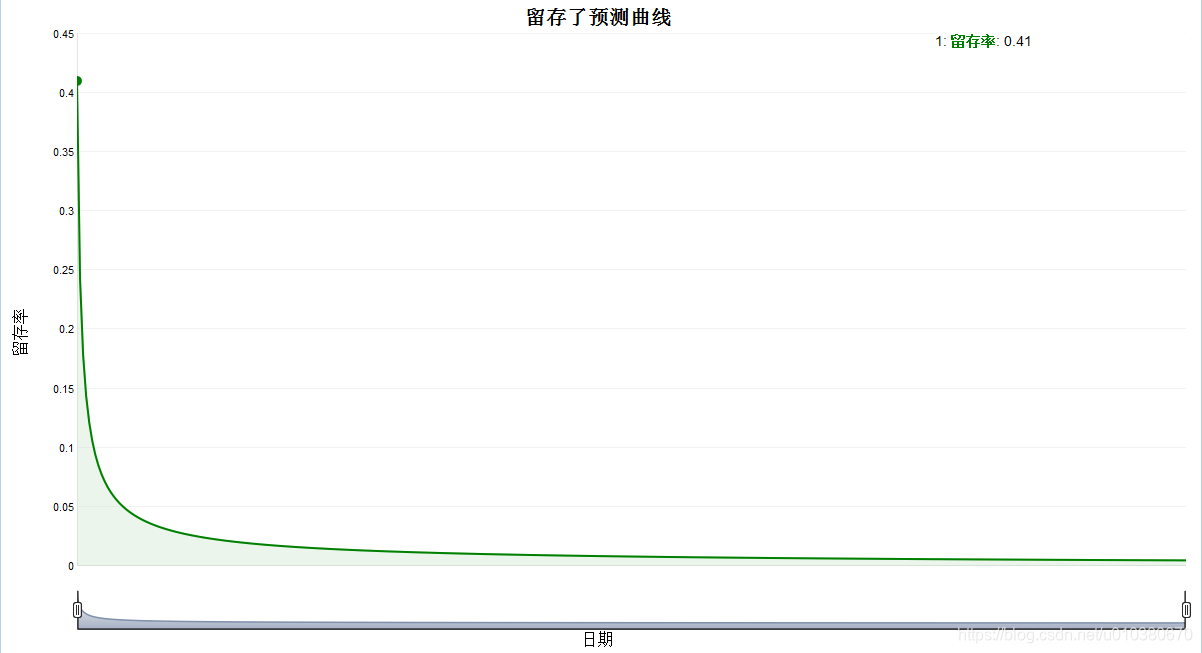
# 绘制留存率预测曲线
library(dygraphs)
data <- as.data.frame(predicted)
data <- ts(data)
dygraph(data,main="留存了预测曲线") %>%
dySeries("predicted",label="留存率",strokeWidth = 2) %>%
dyOptions(colors = "green",fillGraph = TRUE,fillAlpha = 0.4) %>%
dyHighlight(highlightCircleSize = 5,
highlightSeriesBackgroundAlpha = 0.2,
hideOnMouseOut = FALSE) %>%
dyAxis("x", label = "日期",drawGrid = FALSE) %>%
dyAxis("y", label = "留存率") %>%
dyRangeSelector()
# 导入实际留存率数据
actual <- read.csv("实际留存数据.csv")
# 对类型1的游戏进行留存率预测
type1 <- actual[1:7,2]
day <- seq(1:7)
fit1 <- nls(type1~a*day^b,start = list(a=1,b=1))
fit1
predicted1 <- round(predict(fit1,data.frame(day=seq(1,365))),3)
# 对类型2的游戏进行留存率预测
type2 <- actual[1:7,3]
day <- seq(1:7)
fit2 <- nls(type2~a*day^b,start = list(a=1,b=1))
fit2
predicted2 <- round(predict(fit2,data.frame(day=seq(1,365))),3)
# 将预测值与原始值合并在一起
result <- data.frame(actual,predicted1,predicted2)
head(result)
# 导入T值
tvalue <- read.csv("T值.csv")
# 对type1类型的游戏计算调整预测值
result$adjust.predicted1 <- tvalue$T1*result$predicted1
# 对type2类型的游戏计算调整预测值
result$adjust.predicted2 <- tvalue$T2*result$predicted2
# 查看数据前六行
head(result)
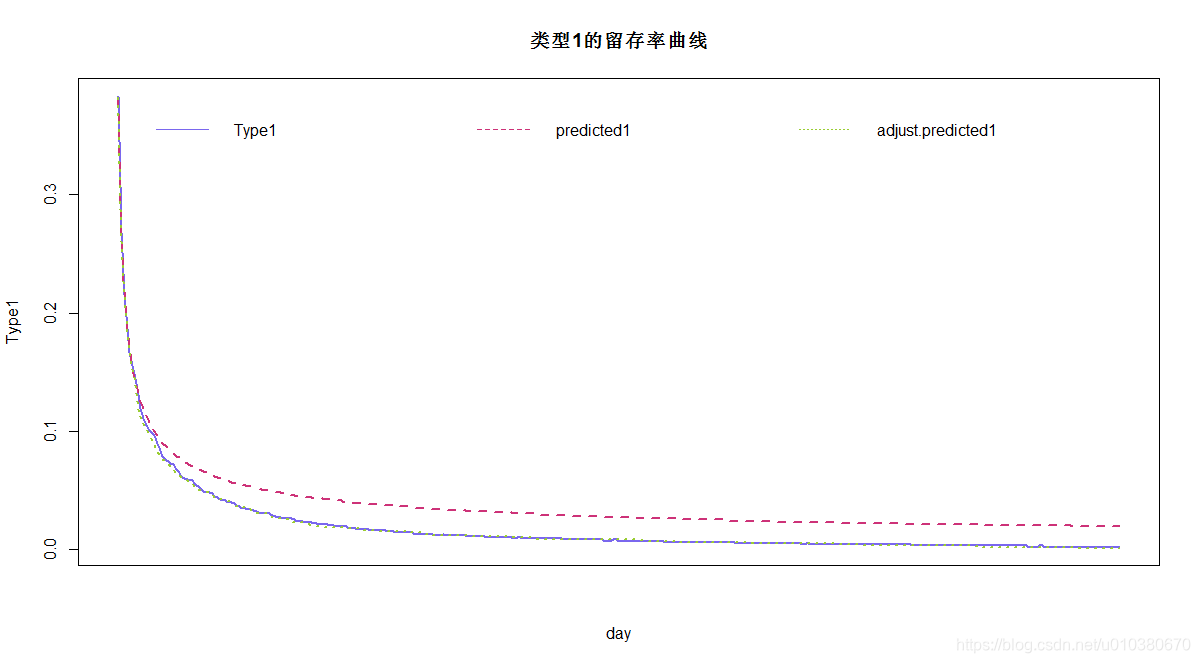
# 绘制留存率曲线
# 绘制type1的预测曲线
# 绘制实际留存率曲线
plot(Type1~day,data=result,col="slateblue2",main="类型1的留存率曲线",
type="l",xaxt="n",lty=1,lwd=2)
# 绘制留存率预测曲线
lines(predicted1~day,dat=result,col="violetred3",type="l",lty=2,lwd=2)
# 绘制留存率调整预测曲线
lines(adjust.predicted1~day,data=result,col="yellowgreen",type="l",lty=3,lwd=2)
# 增加图例
legend("top",legend=colnames(result)[c(2,4,6)],lty = 1:3,ncol=3,
col=c("slateblue2","violetred3","yellowgreen"),bty = "n")
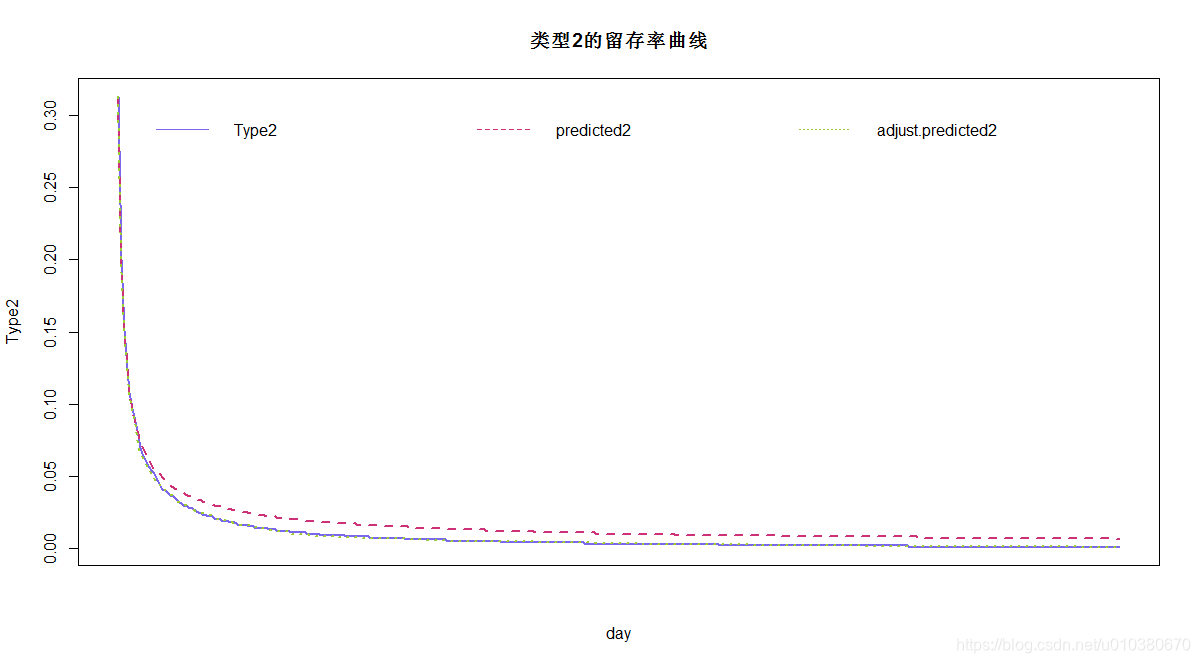
# 绘制type2的预测曲线
# 绘制实际留存率曲线
plot(Type2~day,data=result,col="slateblue2",main="类型2的留存率曲线",
type="l",xaxt="n",lty=1,lwd=2)
# 绘制留存率预测曲线
lines(predicted2~day,dat=result,col="violetred3",type="l",lty=2,lwd=2)
# 绘制留存率调整预测曲线
lines(adjust.predicted2~day,data=result,col="yellowgreen",type="l",lty=3,lwd=2)
# 增加图例
legend("top",legend=colnames(result)[c(3,5,7)],lty = 1:3,ncol = 3,
col=c("slateblue2","violetred3","yellowgreen"),bty = "n")
常用3种KNN:
knn()
kknn()
train()
# KNN近邻分类
# 随机抽取1/2的样本作为训练集,另外一半的样本作为测试集来验证模型的效果
iris1<-iris
set.seed(1234)
# 利用caret包的createDataPartition函数按不同类别等比例抽取50%
library(caret)
ind <- createDataPartition(iris1$Species,times=1,p=0.5,list=F)
traindata <-iris1[ind,] #构建训练集
testdata <- iris1[-ind,] #构建测试集
# 利用class包中的knn函数对测试集的分类进行预测。
library(class)
a=knn(traindata[,1:4],testdata[,1:4],traindata[,5],k=3) #指定k值为3
a[1];a[75] # 查看第一条和最后一条测试数据的预测结果
# KNN算法流程验证:
ceshi <- function(n=1,k=3){
# 计算第n个测试集样本与训练集样本的距离
x <- (traindata[,1:4]-testdata[rep(n,75),1:4])^2
traindata$dist1 <- apply(x,1,function(x) sqrt(sum(x)))
# 对距离进行升序排序,选择最近的K个邻居
mydata <- traindata[order(traindata$dist1)[1:k],5:6]
# 统计不同类别的频数
result <- data.frame(sort(table(mydata$Species),decreasing = T))
# 给出最后的预测结果
return(result[1,1])
}
ceshi() # 第一个样本的预测结果
ceshi(n=75) # 最后一个样本的预测结果
# 朴素贝叶斯分类
# 导入car数据集
car <- read.table("car.data",sep = ",")
# 对变量重命名
colnames(car) <- c("buy","main","doors","capacity",
"lug_boot","safety","accept")
# 随机选取75%的数据作为训练集建立模型,25%的数据作为测试集用来验证模型
library(caret)
# 构建训练集的下标集
ind <- createDataPartition(car$accept,times=1,p=0.75,list=FALSE)
# 构建测试集数据好训练集数据
carTR <- car[ind,]
carTE <- car[-ind,]
# 使用naiveBayes函数建立朴素贝叶斯分类器
library(e1071)
naiveBayes.model <- naiveBayes(accept~.,data=carTR)
# 预测结果
carTR_predict <- predict(naiveBayes.model,newdata=carTR) # 训练集数据
carTE_predict <- predict(naiveBayes.model,newdata=carTE) # 测试集数据
# 构建混淆矩阵
tableTR <- table(actual=carTR$accept,predict=carTR_predict)
tableTE <- table(actual=carTE$accept,predict=carTE_predict)
# 计算误差率
errTR <- paste0(round((sum(tableTR)-sum(diag(tableTR)))*100/sum(tableTR),
2),"%")
errTE <- paste0(round((sum(tableTE)-sum(diag(tableTE)))*100/sum(tableTE),
2),"%")
errTR;errTE
# 使用决策树算法建立分类树
# 使用C50函数实现C5.0算法
library(C50)
C5.0.model <- C5.0(accept~.,data=carTR)
# 使用rpart函数实现CART算法
library(rpart)
rpart.model <- rpart(accept~.,data=carTR)
# 使用ctree函数实现条件推理决策树算法
library(party)
ctree.model <- ctree(accept~.,data=carTR)
# 预测结果,并构建混淆矩阵,查看准确率
# 构建result,存放预测结果
result <- data.frame(arithmetic=c("C5.0","CART","ctree"),
errTR=rep(0,3),errTE=rep(0,3))
for(i in 1:3){
# 预测结果
carTR_predict <- predict(switch(i,C5.0.model,rpart.model,ctree.model),
newdata=carTR,
type=switch(i,"class","class","response")) # 训练集数据
carTE_predict <- predict(switch(i,C5.0.model,rpart.model,ctree.model),
newdata=carTE,
type=switch(i,"class","class","response")) # 测试集数据
# 构建混淆矩阵
tableTR <- table(actual=carTR$accept,predict=carTR_predict)
tableTE <- table(actual=carTE$accept,predict=carTE_predict)
# 计算误差率
result[i,2] <- paste0(round((sum(tableTR)-sum(diag(tableTR)))*100/sum(tableTR),
2),"%")
result[i,3] <- paste0(round((sum(tableTE)-sum(diag(tableTE)))*100/sum(tableTE),
2),"%")
}
# 查看结果
result

# 集成学习及随机森林
# 使用adabag包中的bagging函数实现bagging算法
library(adabag)
bagging.model <- bagging(accept~.,data=carTR)
# 使用adabag包中的boosting函数实现boosting算法
boosting.model <- boosting(accept~.,data=carTR)
# 使用randomForest包中的randomForest函数实现随机森林算法
library(randomForest)
randomForest.model <- randomForest(accept~.,data=carTR)
# 预测结果,并构建混淆矩阵,查看准确率
# 构建result,存放预测结果
result <- data.frame(arithmetic=c("bagging","boosting","随机森林"),
errTR=rep(0,3),errTE=rep(0,3))
for(i in 1:3){
# 预测结果
carTR_predict <- predict(switch(i,bagging.model,boosting.model,randomForest.model),
newdata=carTR) # 训练集数据
carTE_predict <- predict(switch(i,bagging.model,boosting.model,randomForest.model),
newdata=carTE) # 测试集数据
# 构建混淆矩阵
tableTR <- table(actual=carTR$accept,
predict=switch(i,carTR_predict$class,carTR_predict$class,carTR_predict))
tableTE <- table(actual=carTE$accept,
predict=switch(i,carTE_predict$class,carTE_predict$class,carTE_predict))
# 计算误差率
result[i,2] <- paste0(round((sum(tableTR)-sum(diag(tableTR)))*100/sum(tableTR),
2),"%")
result[i,3] <- paste0(round((sum(tableTE)-sum(diag(tableTE)))*100/sum(tableTE),
2),"%")
}
# 查看结果
result

# 人工神经网络与支持向量机
# 使用nnet包中的nnet函数建立人工神经网络模型
library(nnet)
# 隐藏层有3个节点,初始随机权值在[-0.1,0.1],权值是逐渐衰减的,最大迭代数是200
nnet.model <- nnet(accept~.,data=carTR,size=3,rang=0.1,decay=5e-4,maxit=200)
# 使用kernlab包中的ksvm函数建立支持向量机模型
library(kernlab)
# 使用rbfdot选项制定径向基核函数
svm.model <- ksvm(accept~.,data=carTR,kernel="rbfdot")
# 利用模型对结果进行预测
# 构建混淆矩阵
nnet.t0 <- table(carTR$accept,predict(nnet.model,carTR,type="class"))
nnet.t <- table(carTE$accept,predict(nnet.model,carTE,type="class"))
svm.t0 <- table(carTR$accept,predict(svm.model,carTR,type="response"))
svm.t <- table(carTE$accept,predict(svm.model,carTE,type="response"))
# 查看各自错误率
nnet.err0 <- paste0(round((sum(nnet.t0)-sum(diag(nnet.t0)))*100/sum(nnet.t0),
2),"%")
nnet.err <- paste0(round((sum(nnet.t)-sum(diag(nnet.t)))*100/sum(nnet.t),
2),"%")
svm.err0 <- paste0(round((sum(svm.t0)-sum(diag(svm.t0)))*100/sum(svm.t0),
2),"%")
svm.err <- paste0(round((sum(svm.t)-sum(diag(svm.t)))*100/sum(svm.t),
2),"%")
nnet.err0;nnet.err;svm.err0;svm.err
# 模型评估
# k折交叉验证
# 构建10折交叉验证
#下面构造10折下标集
library(caret)
ind<-createFolds(car$accept,k=10,list=FALSE,returnTrain=FALSE)
# 下面再做10折交叉验证,这里仅给出训练集和测试集的分类平均误判率。
E0=rep(0,10);E1=E0
library(C50)
for(i in 1:10){
n0=nrow(car)-nrow(car[ind==i,]);n1=nrow(car[ind==i,])
a=C5.0(accept~.,car[!ind==i,])
E0[i]=sum(car[!ind==i,'accept']!=predict(a,car[!ind==i,]))/n0
E1[i]=sum(car[ind==i,'accept']!=predict(a,car[ind==i,]))/n1
}
(1-mean(E0));(1-mean(E1))
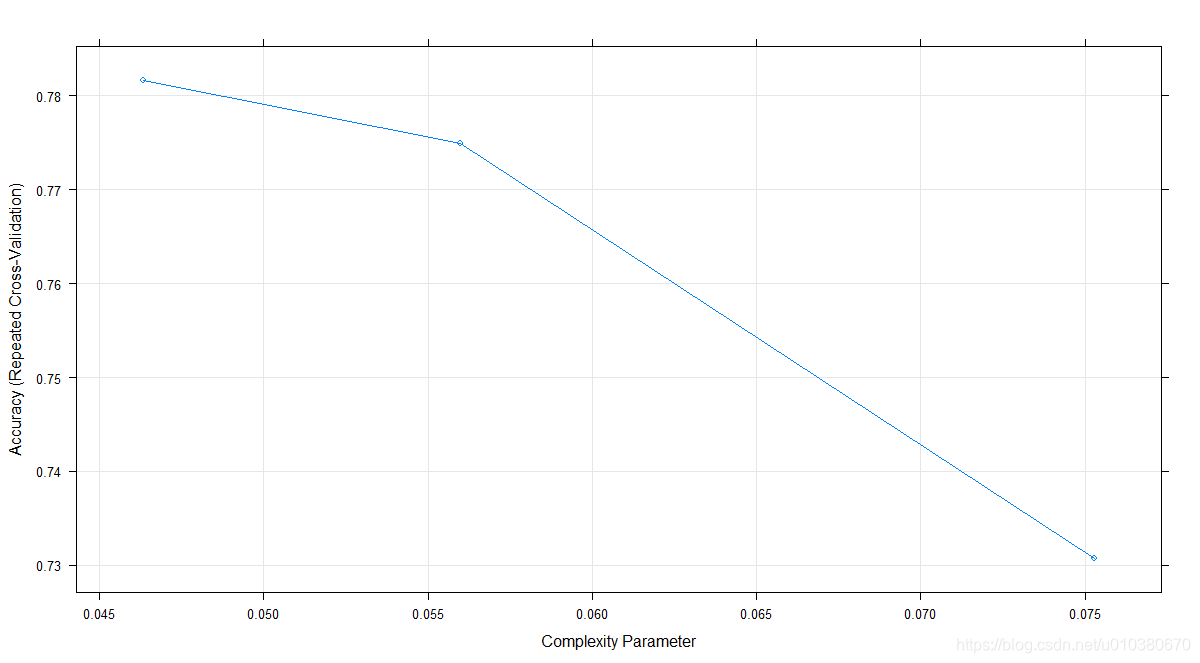
# 利用caret包中的train函数完成交叉验证
library(caret)
control <- trainControl(method="repeatedcv",number=10,repeats=3)
model <- train(accept~.,data=car,method="rpart",
trControl=control)
model
plot(model)
# 数据准备
w <- read.csv("用户流失预测数据.csv") # 导入数据
w <- w[,-1] # 剔除用户ID
w$活跃度 <- round(w$登录总次数/7,3) #增加活跃度字段
w$玩牌胜率 <- round(w$赢牌局数/w$玩牌局数,3) # 增加玩牌胜率字段
# 对数据进行哑变量处理,进行相关性分析
library(caret)
dmy <- dummyVars(~.,data=w) # 构建哑变量对象
trsf <- data.frame(predict(dmy,newdata=w)) # 对数据进行虚拟化处理
M <- round(cor(trsf[,1:2],trsf[,c(-1,-2)]),3) # 进行相关性分析
M
library(corrplot)
corrplot(M,method="ellipse",col = c("green","black")) # 对相关系数进行可视化
# 利用随机森林模型中查看每个属性的重要性
library(randomForest)
model <- randomForest(是否流失~.,data=w,importance=TRUE) # 建立随机森林模型
varImpPlot(model,main="Variable Importance Random Forest") # 查看变量重要性
# 随机选取75%的数据作为训练集建立模型,25%的数据作为测试集用来验证模型
library(caret)
# 构建训练集的下标集
ind <- createDataPartition(w$是否流失,times=1,p=0.75,list=FALSE)
# 构建测试集数据好训练集数据
traindata <- w[ind,]
testdata <- w[-ind,]
# 数据建模
# 利用10折交叉验证来选择最优参数
control <- trainControl(method="repeatedcv",number=10,repeats=3)
rpart.model <- train(是否流失~.,data=w,method="rpart",
trControl=control)
rf.model <- train(是否流失~.,data=w,method="rf",
trControl=control)
nnet.model <- train(是否流失~.,data=w,method="nnet",
trControl=control)
# 查看模型结果
rpart.model
rf.model
nnet.model
# 利用决策树、随机森林、人工神经网络构建分类器,并对查看预测错误率
# 利用rpart函数建立分类树
rpart.model <- rpart::rpart(是否流失~.,data=traindata,control=(cp=0.0137457))
# 利用randomForest函数建立随机森林
rf.model <- randomForest::randomForest(是否流失~.,data=traindata,mtry=2)
# 利用nnet函数建立人工神经网络
nnet.model <- nnet::nnet(是否流失~.,data=traindata,size = 1,decay = 0.1)
# 构建result,存放预测结果
result <- data.frame(arithmetic=c("决策树","随机森林","人工神经网络"),
errTR=rep(0,3),errTE=rep(0,3))
for(i in 1:3){
# 预测结果
traindata_predict <- predict(switch(i,rpart.model,rf.model,nnet.model),
newdata=traindata,type="class") # 对训练集数据预测
testdata_predict <- predict(switch(i,rpart.model,rf.model,nnet.model),
newdata=testdata,type="class") # 对测试集数据预测
# 构建混淆矩阵
tableTR <- table(actual=traindata$是否流失,traindata_predict)
tableTE <- table(actual=testdata$是否流失,testdata_predict)
# 计算误差率
result[i,2] <- paste0(round((sum(tableTR)-sum(diag(tableTR)))*100/sum(tableTR),
2),"%")
result[i,3] <- paste0(round((sum(tableTE)-sum(diag(tableTE)))*100/sum(tableTE),
2),"%")
}
# 查看结果
result
# 下面用不同数目(1~500棵)树训练随机森林
n = 500
NMSE = NMSE0 <- rep(0,n)
for(i in 1:n){
a <- randomForest(是否流失~.,data=traindata,ntree=i)
y0 <- predict(a,traindata)
y1 <- predict(a,testdata)
NMSE0[i] <- sum(traindata[,'是否流失']!=y0)/nrow(traindata)
NMSE[i] <- sum(testdata[,'是否流失']!=y1)/nrow(testdata)
}
plot(1:n,NMSE,type="l",ylim=c(min(NMSE,NMSE0),max(NMSE,NMSE0)),
xlab="树的数目",ylab="误差率",lty=2)
lines(1:n,NMSE0)
legend("topright",lty=1:2,c("训练集","测试集"))