一开始,老板让调整一下 innodb_buffer_pool_size 大小,因为这台机器内存大。
看了下内存,16G,再SQL下面命令,得到结果是4G。
SELECT @@innodb_buffer_pool_size;
果断vim /etc/my.cnf
修改了 innodb_buffer_pool_size = 8G # (adjust value here, 50%-70% of total RAM)
括号中内容是官方给的建议。
然后再执行下面的命令,调整到8G,这样不用重启mysql服务,即调整完毕。
SET GLOBAL innodb_buffer_pool_size=8589934592; -- 8G
其它的几个查询:
-- show status like 'Threads%'; -- 连接数 -- show processlist; -- 查看连接,可以知道当前有哪些IP连接 -- select * from information_schema.processlist order by id; -- 查看连接
最近才知道, mysql从5.7版本开始,增加了新的字段类型: json
所以在centos6.5上装了个5.7版本作为平时测试用.

#----------------------------------------------------------------------#
# 修改yum源为aliyun
# 先备份:
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
# 下载配置文件 注意 centos版本
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
yum makecache # 生成缓存
# yum -y update # 升级所有包同时也升级软件和系统内核 不是必要
#----------------------------------------------------------------------#
### --------------------------------------------------------------------###
# 安装 mysql 5.7版本 不同于低版本的安装,稍微复杂。
yum list installed | grep mysql # 检测系统是否自带安装mysql
yum -y remove mysql-libs.x86_64 # 删除系统自带的mysql及其依赖
# 给CentOS添加rpm源,并且选择较新的源
wget dev.mysql.com/get/mysql-community-release-el6-5.noarch.rpm --no-check-certificate
yum install mysql-community-release-el6-5.noarch.rpm
vim /etc/yum.repos.d/mysql-community.repo
# 编辑此文件,将MySQL 5.7下的 enabled=1 低版本的改成 enabled=0
yum repolist enabled | grep mysql # 检查mysql57的源是否开启
# 安装mysql 服务器
yum install mysql-community-server
cat /var/log/mysqld.log | grep "password" # 找到临时密码
# 如果没有找到密码,则可能使用之前本机旧版本的密码。
service mysqld start
chkconfig mysqld on
mysql_secure_installation # 设置安全选项
mysql -uroot -p # 输入临时密码
SET PASSWORD = PASSWORD('your password'); # 设置新密码
# 如果远程连接出错:'performance_schema.session_variables' doesn't exist
# 则操作以下命令并重启服务后,再连接
mysql_upgrade -u root -p --force
service mysqld restart
设计表的时候, 字段类型直接选json 就像平常选varchar一样.
插入数据的时候, 需要转成JSON_OBJECT 。 而JSON_ARRAY 用来将多个值存成数组。 如下面的示例:
SELECT mac, JSON_OBJECT('e1',JSON_ARRAY (round( AVG( value ->> '$.e1' ), 3 ),MIN( value ->> '$.e1' ),MAX( value ->> '$.e1' )),
'e2',JSON_ARRAY (round( AVG( value ->> '$.e2' ), 3 ),MIN( value ->> '$.e2' ),MAX( value ->> '$.e2'))) as json
FROM history
WHERE
mac ='522099e6660004' and time between '2018-08-07 00:00:00' AND '2018-08-08 00:00:00'
GROUP BY
mac
value是表中的字段名,e1、e2是此字段中json的key, AVG/MIN/MAX不用多说了,大家都知道。 此句的作用是以某mac字段和时间为限定,分别取出e1的avg/min/max,然后赋给一个新的数组 “e1", 取出e2的avg/min/max,然后赋给一个新的数组 “e2",然后组成json对象,得到下面的结果。
{"e1": [25.568, 12, 121], "e2": [28.631, 12, 182]}
取值的时候,取json里面的键,可以直接用SQL语句,像下面这么写:
value -> '$.e1' 表示取出json型字段名为value中的 e1 健的值. 即使取出的数字,也带有双引号
value ->> '$.e1' 则取出数字不带有双引号, 但此时仍然不是数值类型. JSON_UNQUOTE(json_extract(json,'$.attr')) 也可以去掉引号.
value ->> '$.e1'+0 则会强制将取出的字符型数字转为数值类型. CAST('123' AS SIGNED) 或 CONVERT('123',SIGNED)的函数也行,但是执行速度没有直接 +0 快. (必须看起来的确是数字)
如果跑py脚本,没有安装环境,则依次执行以下命令。
或者参考更详细的python升级2.7 https://www.cnblogs.com/frx9527/p/python27.html
yum install gcc gcc-c++ -y yum -y install mysql-devel yum install python-devel pip install --upgrade pip pip install MySQL-python -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
以下脚本运行在python2.7 因为python3以上不再有 MySQLdb
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import MySQLdb, time, datetime, json
print(datetime.datetime.now())
HOST = 'node-6'
db = MySQLdb.connect(HOST, "root", "123456", "monitor_db")
cursor = db.cursor()
def get_date(str_date):
t = time.strptime(str_date, '%Y-%m-%d')
y, m, d = t[0:3]
return datetime.datetime(y, m, d)
def insert_device_data(cursor, data):
sql = "INSERT INTO history_daily (mac, time, json) VALUES (%s, %s, %s)"
# print sql
cursor.executemany(sql, data)
def fetch_device_minutely_data(cursor, start, end, mac):
try:
sql = '''
SELECT
mac,
CASE version %s
END json
FROM
history
WHERE
mac ='%s'
and time between '%s' AND '%s'
GROUP BY
mac,
version
''' % (jsonkey, mac, start, end)
# print(sql) # 壮观的 case ... when
cursor.execute(sql)
data = cursor.fetchall()
if data:
for d in data:
mac = d[0]
json = d[1]
device_data = []
device_data.append((mac, start, json))
insert_device_data(cursor, tuple(device_data))
except MySQLdb.OperationalError, e:
print(e)
time.sleep(10)
db = MySQLdb.connect(HOST, "root", "123456", "monitor_db")
cursor = db.cursor()
fetch_device_minutely_data(cursor, start, end, mac)
# 设备表 id , version
version_sql = 'SELECT id, version FROM device_version GROUP BY id, version'
cursor.execute(version_sql)
versions = cursor.fetchall() # version 从2到10
jsonkey = ""
if versions:
for version in versions:
print (version[0])
sensor_sql = '''
SELECT s.sensor_key FROM device_version_sensor dvs,sensor s WHERE dvs.sensor_id = s.id AND dvs.device_version_id = '%d'
''' % (version[0]) # e1 e2 e3 ...
cursor.execute(sensor_sql)
keys = cursor.fetchall()
if keys:
jsonkey += "WHEN " + str(int(version[1])) + " THEN JSON_OBJECT("
for i, sensorKey in enumerate(keys):
key = sensorKey[0]
jsonkey += "'" + str(key) + "',JSON_ARRAY (round( AVG( value ->> '$." + str(
key) + "'+0 ), 3 ),MIN( value ->> '$." + str(
key) + "'+0 ), MAX( value ->> '$." + str(key) + "'+0 ))"
if i != len(keys) - 1:
jsonkey += ","
jsonkey += ")"
# mac 列表
sql_mac = 'SELECT DISTINCT mac FROM `history` where mac is not NULL';
cursor.execute(sql_mac)
mac_tuple = cursor.fetchall() # version 从2到10
start_date = get_date((datetime.datetime.now() + datetime.timedelta(days=-6)).strftime("%Y-%m-%d"))
end_date = get_date((datetime.datetime.now()).strftime("%Y-%m-%d"))
days = (end_date - start_date).days
for i in range(days):
start_day = start_date + datetime.timedelta(days=i)
end_day = start_date + datetime.timedelta(days=i + 1)
for mac in mac_tuple:
# print (mac[0])
fetch_device_minutely_data(cursor, start_day, end_day, mac[0])
db.commit()
db.close()
print(datetime.datetime.now())
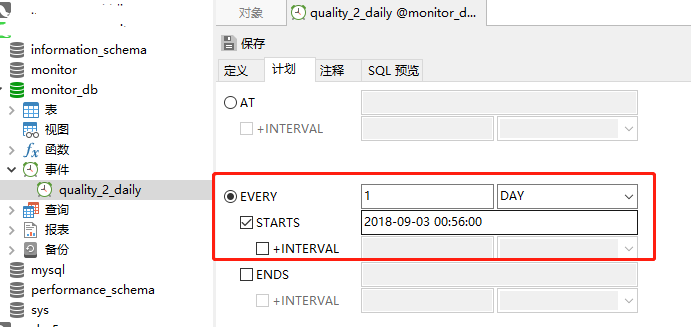
SQL语句创建简单的定时任务,每天凌晨执行前一天的数据汇总,求取表中每个城市的最大值。
对应地将json中的quality值由汉字转换为数字,先存入临时表,最后求取个最大值存放到 quality_daily 表中。如果SQL搞定没问题,就没必要麻烦python了。
定义:
begin
-- 取出所有 quality
INSERT INTO quality_tmp ( time, quality, city_code ) SELECT
DATE_FORMAT( time, "%Y-%m-%d" ) AS time,
IF
(
aqi_json ->> "$.quality" = "优",
1,
IF
(
aqi_json ->> "$.quality" = "良",
2,
IF
(
aqi_json ->> "$.quality" = "轻度污染",
3,
IF
( aqi_json ->> "$.quality" = "中度污染",
4,
IF
( aqi_json ->> "$.quality" = "重度污染",
5,
IF(aqi_json ->> "$.quality" = "严重污染", 6, 0)) )
)
)
) AS quality,
city_code
FROM
`hangzhou_aqi`
WHERE
time >= date_sub( curdate( ), INTERVAL 1 DAY )
AND time < curdate( );
-- 求出最大值
INSERT into quality_daily(time,quality,city_code)
SELECT time, max(quality), city_code from quality_tmp GROUP BY time,city_code ;
-- 清空临时表
delete from quality_tmp;
end
设定 计划 为每一天。