前面学习有关弹性伸缩的论文以及k8s HPA的源码,对于云计算中弹性伸缩有了一些认识,总结一下。
弹性伸缩简介

伸缩理论关注的问题主要是在面临超出现有集群最大承载能力的时候,如何通过调整集群的规模以提高集群的承载能力,从而保证用户体验和系统服务的稳定性,同时在集群负载很低的时候,尽可能的减少闲置服务器带来的资源浪费。伸缩一般分为应用伸缩,技术伸缩以及资源伸缩。其中资源的伸缩性是指通过增加 CPU、内存等硬件资源的投入来提升软件效率以达到更高的系统性能。平常所说的集群伸缩方法大多数是指资源的伸缩性,而资源的伸缩性又可以划分为两个子类。从伸缩的方向划分,分为纵向的伸缩和横向的伸缩。

纵向伸缩是指通过提升系统当前各个节点的处理能力来达到提升系统整体处理能力的伸缩方法。提高各节点的处理能力具体来说包括服务器升级现有的配置,例如更换主频更高、多核的处理器,更换容量更大的内存条,配置读写速度更快的硬盘、甚至替换为更高端、更强劲的处理器等。
横向伸缩是单纯地通过增加节点的数量来提升系统整体的处理能力。横向伸缩的优点在于当每台服务器成本比较低的情况下,可以很容易地搭建起一个系统性能有保障的集群,相比纵向伸缩集群,这个集群面对增加的用户量或者数据量带来的性能瓶颈可以处理得更灵活、游刃有余,并且能够很好的减少由于单台服务器出现故障而对于系统整体带来的影响。
弹性伸缩算法

大致分为两种:
基于阈值的响应式伸缩算法
周期性采集监测系统某些指标cpu,mem,io,net等,通过与设定阈值进行比较从而动态改变集群数量,k8s HPA策略基于该种算法实现,缺点是系统响应速度过慢,弹性伸缩变化往往晚于负载变化
基于预测型的伸缩算法
对于过去一段时间数据进行建模,对于未来某个时刻进行预测。
预测算法主要有机器学习以及时间序列分析。时间序列分析法主要有简单移动平均,指数平滑,自回归模型
1.简单移动平均法
对于过去一段时间的值进行平均代表未来的值,预测仅仅停留在过去水平,无法预测短时间较大波动。

2.指数平滑法
给与过去不同时间的值不同权重,距离较近则权重较大,距离较远则权重较小。一种短期时间序列的预测方法,具有计算量少、预测精度高的优点,同时该方法能充分利用全部历史数据,并且按照“重近轻远”的原则进行加权平均和修匀数据,能够较好地将时间序列所包含的历史规律挖掘出来。{yt}原始时间序列,对原始时间序列进行一次指数平滑:

进行二次指数平滑:
预测方程:


3.自回归模型
自回归模型指的是一类常用的随机时间序列分析模型,其基本思想是某些时间序列是依赖于时间的一系列时间变量,构成该时序的单个序列值虽然具有不确定性的,但是整个序列的变化趋势具有一定的规律性,因此可以用相应的数学模型近似描述。AR模型是应用最为广泛的时间序列模型,通过对历史观测值的建模,基本上能够对时间序列做出很好的预测,但是AR模型也具有一定的局限性,AR模型能够做出准确预测的前提是时间序列必须为平稳序列,因此在实际的应用场景中,对于非平稳序列常需要将其转化为平稳序列后才能使用。
4.灰度预测模型
灰色预测通过鉴别系统因素之间发展趋势的差异程度,对原始数据进行生成处理,寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势。灰色预测的数据是通过生成数据模型得到的预测值的逆处理结果。灰色预测以灰色模型为基础。灰色系统理论以“部分样本信息已知,部分样本信息未知”的“小样本”来进行预测的算法模型,该模型主要通过对部分未知信息的生成来开发和提取有价值的信息,从而实现对系统运行规律的正确认识和确切描述。基于灰色系统理论 GM(1,1)模型的预测方法称为灰色预测方法。灰色预测方法对于样本量小、变化规律不明显的样本有很好的适应性,同时灰色预测法的计算量小而且其定量分析结果和定性分析结果保持一致。
样本数据:
一次累加序列:
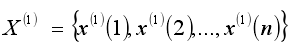

紧邻均值序列:
白花方程:

5.BP 神经网络预测模型
将正确的结果和产生的结果进行比较,得到误差,再逆推对神经网中的权重进行反馈修正,从而来完成学习的过程。

资源收集
无论是基于阈值还是基于预测算法都需要对于系统的性能指标进行收集处理
主要待收集的指标:
物理主机 cpu 内存 磁盘 网络,主机容器数量
容器 cpu, 内存,磁盘io, 网络
目前主流的指标收集技术有:
Docker容器原生API
Cadvisor收集容器数据信息
InfluxDB时序数据库
Grafana图形化展示
K8s HPA
HPA可以根据一定的性能指标自动监测以及控制集群的数量,使其满足一定的预定条件。默认使用cpu利用率来控制集群数量动态变化,同时也可以使用custom metrics来自定义指标。HPA支持的资源类型有Replication Controller, Deployment or Replica Set.


利用cpu利用率与预定的cpu利用率来进行伸缩
![]()
具体细节可以参考
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
hpa源码解析可以参考
https://blog.csdn.net/u014106644/article/details/85004766
参考文献
[1]徐建中,王俊,周迅钊,徐雷.一种基于预测的云计算的弹性伸缩策略[J].计算机与数字工程,2018,46(06):1160-1162+1231.
[1]王强,王瑞刚,周德永.基于Docker的动态负载均衡弹性伸缩系统[J].计算机与数字工程,2018,46(06):1140-1144+1159.
[1]李正寅. 服务创新平台中基于Docker的弹性负载均衡功能的设计与实现[D].北京邮电大学,2018.
[1]刘彪,王宝生,邓文平.云环境下支持弹性伸缩的容器化工作流框架[J/OL].计算机工程:1-12[2018-12-14].https://doi.org/10.19678/j.issn.1000-3428.0049811.
[1]王天泽.基于灰色模型的云资源动态伸缩功能研究[J].软件导刊,2018,17(04):131-134.
[1]陈金光. 基于阿里云的Kubernetes容器云平台的设计与实现[D].浙江大学,2018.
[1]王晓钰. 基于云平台可弹性扩缩的Web应用系统的研究与实现[D].北京邮电大学,2018.
[1]刘锦福. 基于Docker的直播云平台弹性调度系统设计及实现[D].北京邮电大学,2018.
[1]梅荣.基于云计算的弹性负载均衡服务研究[J].中国公共安全,2018(01):194-199.
[1]王晓钰,吴伟明,谷勇浩.基于云平台的弹性Web集群扩缩容机制的研究[J].软件,2017,38(11):24-28.
[1]杨若琪.云计算中弹性伸缩负载预测算法的研究和改进[J].电子制作,2017(16):40-41+59
[1]张淼. 面向云服务的弹性调度算法的研究与实现[D].哈尔滨工业大学,2017.
[1]杨茂. 基于Kubernetes的容器自动伸缩技术的研究[D].西安邮电大学,2018.