使用tesseract训练教程完成全国企业信息中心湖南验证码的字库建立。
准备工具
Tesseract3.01和3.02。下载名称:tesseract-ocr-setup-3.02.02.exe
下载chi_sim.traindata字库(中文字库)
下载jTessBoxEitor用于修改box文件 (简单来说通过这个工具获取字体的形状)
Win7环境下运行,需要管理员权限
1. 准备
利用jTessBoxEitor将jpg图像转换成tif图像。
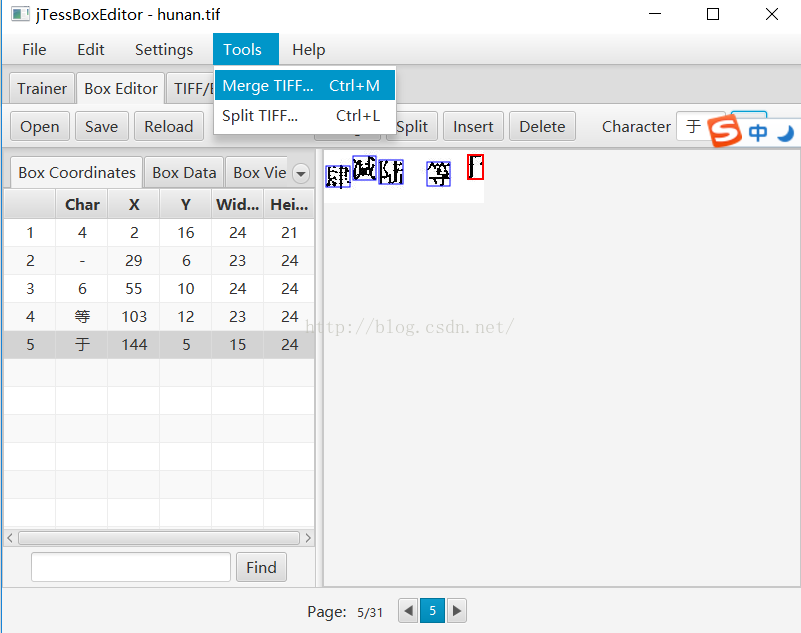
进入界面选取所有的jpg格式的验证码图像
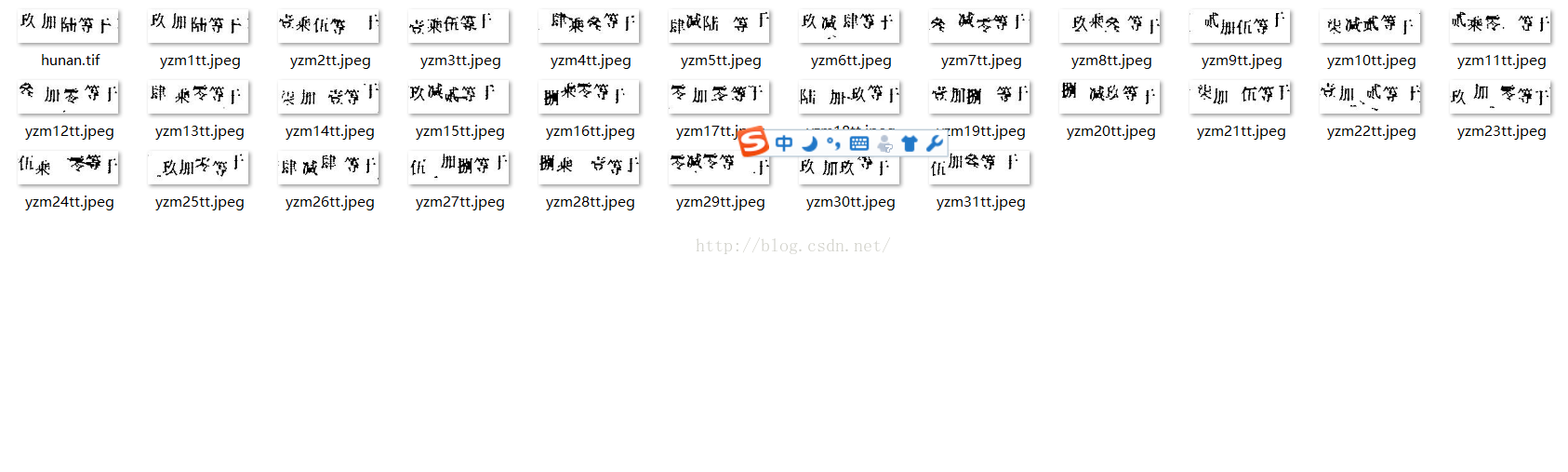
生成了名为hunan.tif综合所有图片的验证码图片。
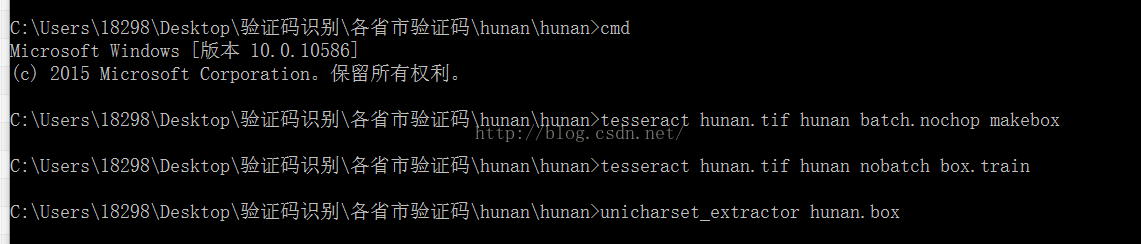
接着为了训练字库。要生成.box文件。在目录下用cmd运行。
命令如下:tesseract hunan.tif hunan batch.nochopmakebox(我是默认字库改成中文简体字库)如不是。请输入tesseracthunan.tif hunan -l chi_sim batch.nochop makebox(-l chi_sim是为了调用chi_sim也就是中文简体字库)

将图片文件和box文件放在同一目录
2用jTessBoxEditor.jar打开tif文件,然后根据实际情况修改box文件
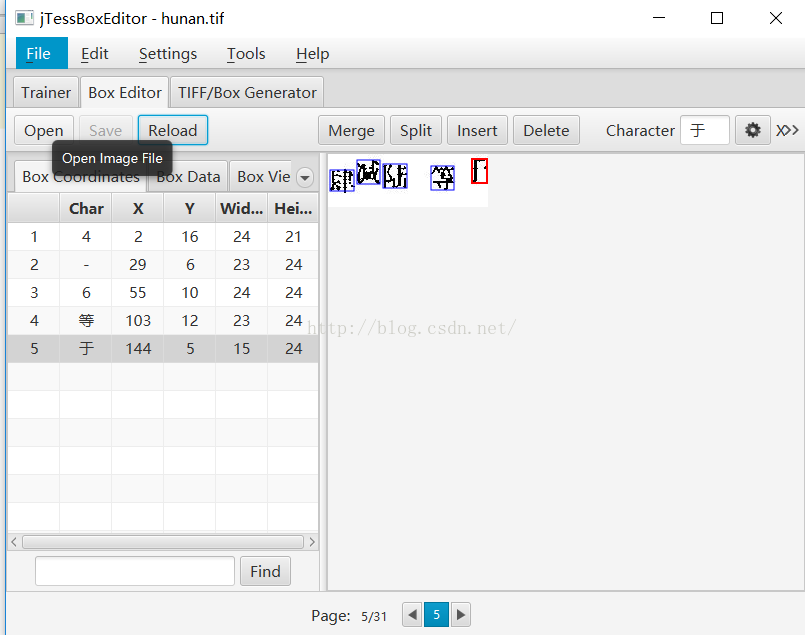
在此处为了识别方便讲繁体中文或者简体中文的汉字全部转换为阿拉伯数字,同时将汉字符号改成符号,如加改成+。
这个识别率在样本在一定范围内会增加,但是如果样本数量过多,导致字符特征过多,会让识别率降低。所以建议根据需求决定自己做的样本空间的大小。
3.如何修改添加汉字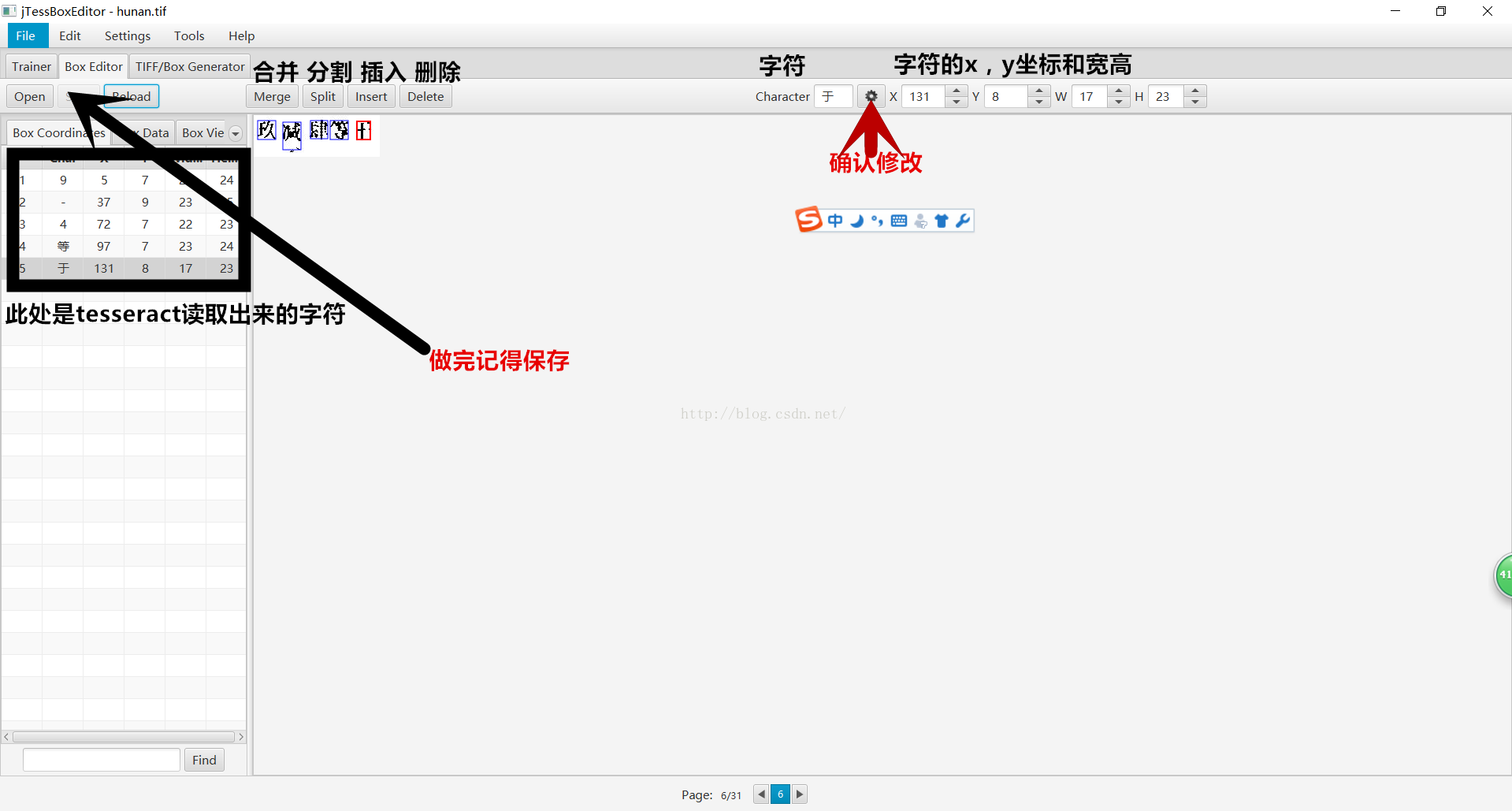
功能在图片上已经说明,根据说明调整字体结构和提高识别率。
Eg:
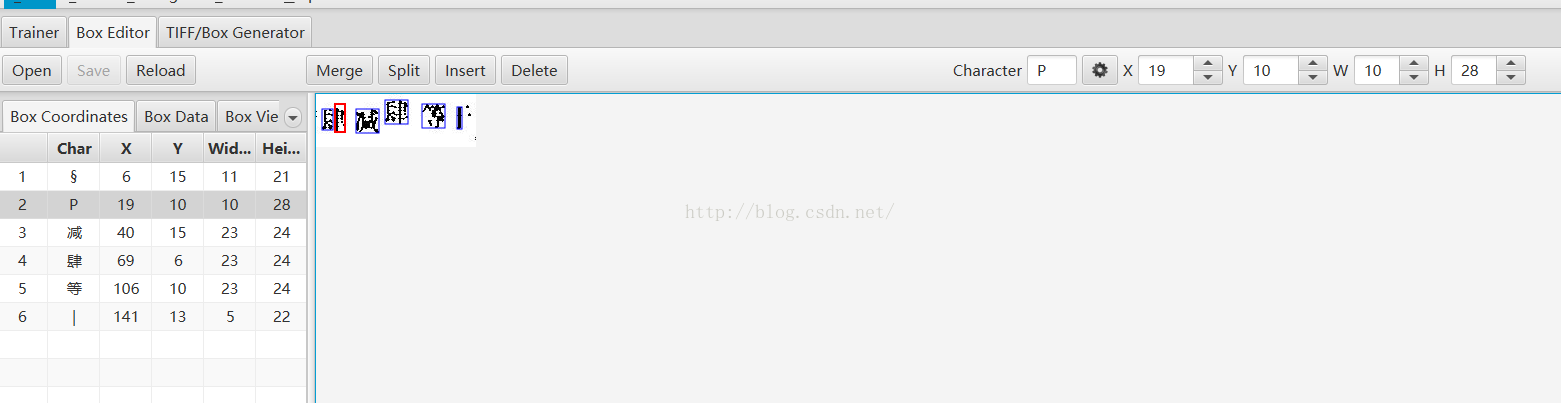
需要改成
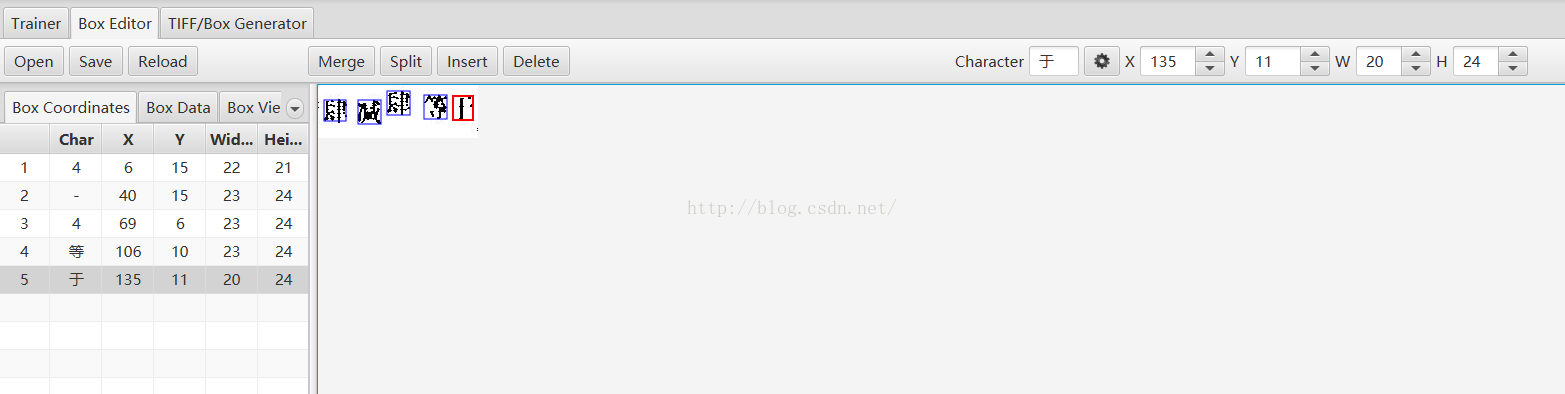
因为tesseract识别的是字符特征。所以可以直接改成数字方便java端读取。
4.生成.tr文件
命令:tesseract hunan.tif hunan nobatchbox.train
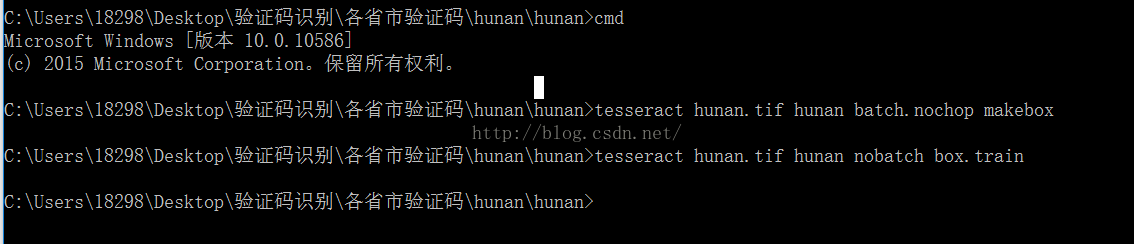
5.接着生成一个unicharset文件
命令:unicharset_extractor hunan.box
6.新建一个font_properties.txt文件
里面内容写入
湖南 0 0 0 0 0表示普通默认字体
字体属性文件
<fontname><italic> <bold> <fixed> <serif> <fraktur>
在<字体>是一个字符串命名的字体 ; <斜体>,<加粗>,<固定>,<衬线>和<哥特体>都是简单的0或1标志指示字体是与否的属性。
例如湖南 1 1 0 0 0
就是表示湖南字体斜体加粗.
7.运行命令
mftraining -F font_properties.txt -Uunicharset -O unicharset hunan.tr
cntraining hunan.tr

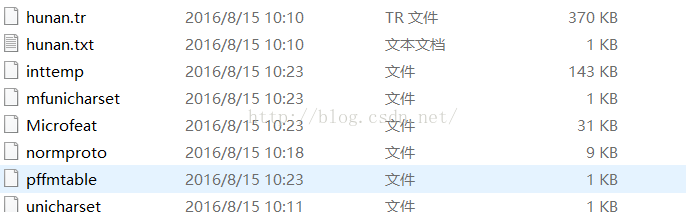
生成
8合并文件
a) unicharset改名为hunan. unicharset
b) inttemp改名为hunan.inttemp
c) normproto改名为hunan. normproto
d) pffmtable改名为hunan. Pffmtable
在cmd下执行combine_tessdatahunan.
生成湖南验证码字库。

9.将湖南字库加入Tesseract-OCR 安装目录下的tessdata
10.接着对新建的字库进行测试
将hunan.tif加入tesseract字库中进行测试。

输入命令:tesseract hunan,tif hunan -l hunan

发现结果和预期一样字库建立成功。
接着利用这种字库可大大提高对特定验证码的识别率。
同时给出的图片验证码都是经过腐蚀算法二值化处理的图片。经过这样处理对各省市的验证码处理率可达到80%