文章目录
YARN
概念
- yarn 是Hadoop的
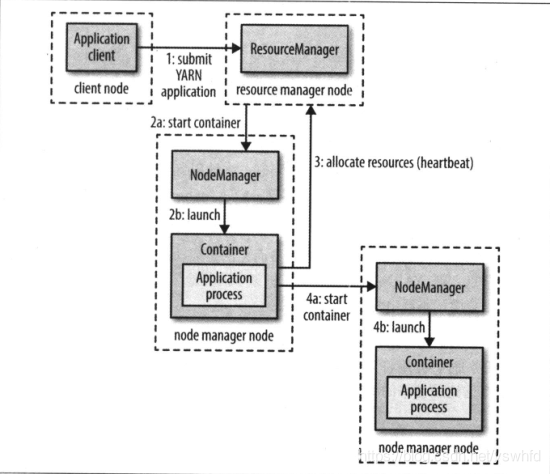
资源调度系统 - yarn 通过两类长期运行的的守护进程提供自己的核心服务。
- 管理集群上资源使用的资源管理器(
ResourceManager) - 运行在所有节点上且能够启动和监控容器(
Container)的节点管理器(node manager)- 容器用于执行特定应用程序的进程,每个容器都有资源限制(内存,CPU等)。
- 管理集群上资源使用的资源管理器(
3. SPARK采用粗粒度的资源申请,而Mapreduce采用细粒度的资源申请。

YARN中的调度
- 理想情况下,YARN中的应用发出资源申请,应该立即被满足。然而现实中资源是有限的,在繁忙的集群中,一个应用经常需要等待才能获取相应的资源。YARN调度器的工作就是根据既定策略为应用分配资源。
- YARN中提供了三种调度器:
- FIFO调度器(FIFO Scheduler)
FIFO调度器将应用放置在一个队列中,然后按按照提交顺序运行任务。简单易懂但不适合共享集群
- 容量调度器(Capacity Scheduler)
- 容量调度器允许多个组织共享一个Hadoop集群,每个组织可以分配到全部资源的一部分。每个组织被分配到指定的队列,每个
队列配置一定的资源。 - 单个作业使用的资源不会超过队列的容量。然而队列中有多个作业,并且资源不够用了怎么办?如果还有空余资源,那么容量调度器可能将资源分配给队列中的作业,即便超过了队列容量,这称为
弹性队列 - 可以为一个队列设置最大容量限制,就不会过多侵占其他队列容量了,但是这同时牺牲了队列弹性
- 公平调度器(Fair Scheduler)
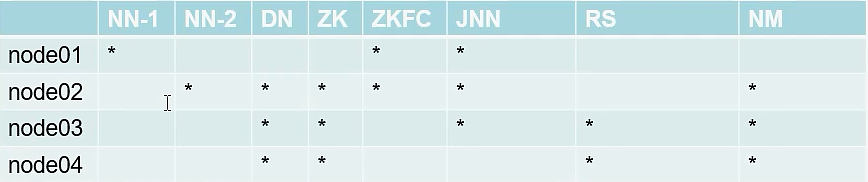
Yarn HA环境搭建
参考文档:http://hadoop.apache.org/
- 配置
1. Configure parameters as follows:etc/hadoop/mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2. etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node4</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node3:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node4:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>
3. 分发配置到其他机器
scp mapred-site.xml yarn-site.xml node2:`pwd`
scp mapred-site.xml yarn-site.xml node3:`pwd`
scp mapred-site.xml yarn-site.xml node4:`pwd`
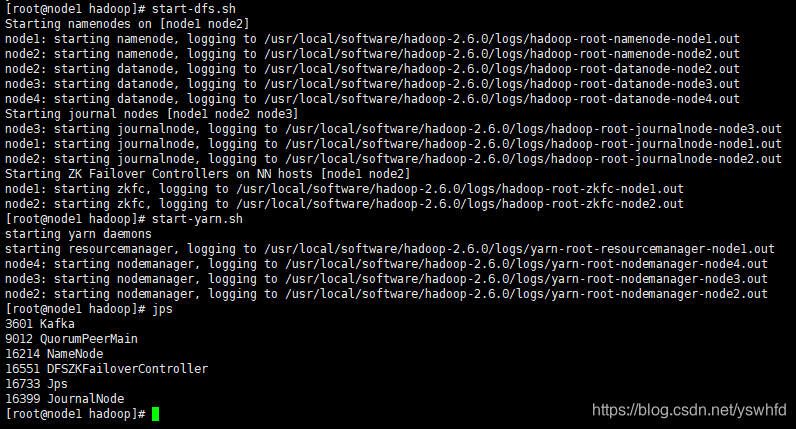
4. 启动 (start-all.sh 也可以,简易执行下面)
//node1
start-dfs.sh
start-yarn.sh
//node3/node4
yarn-daemon.sh start resourcemanager
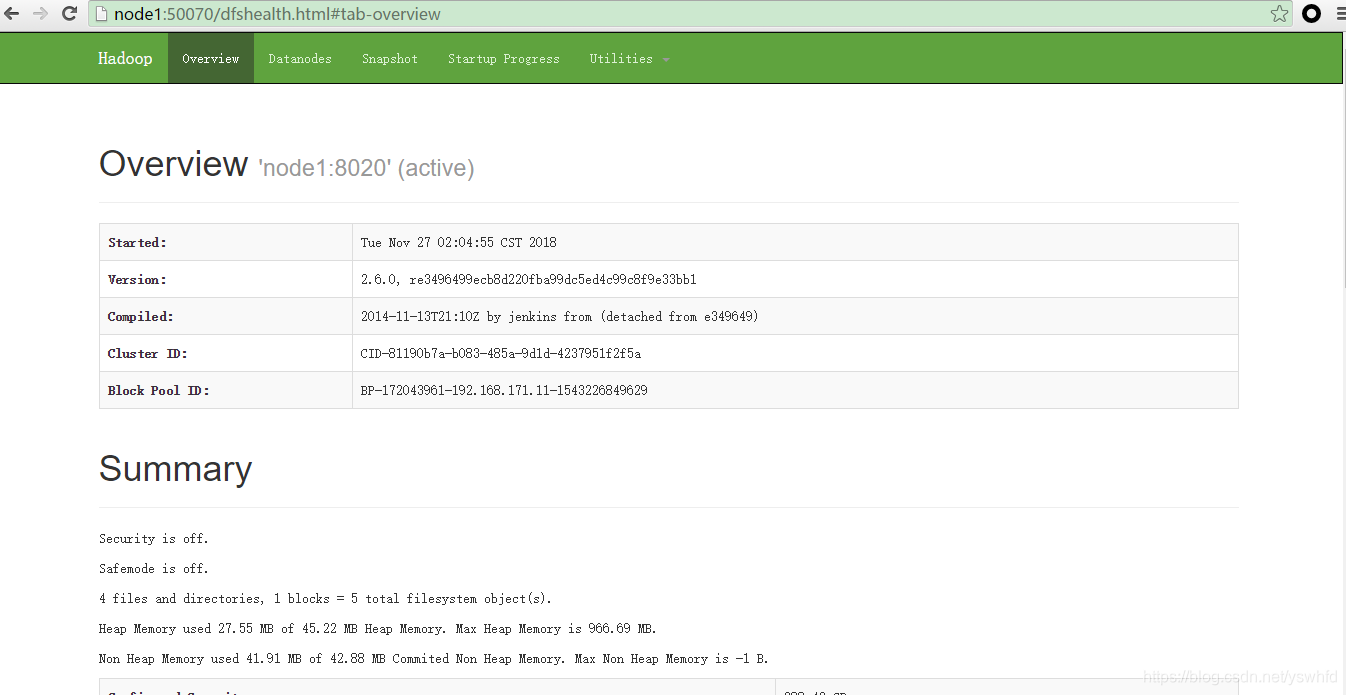
5. 查看页面
//hdfs
node1:50070
node2:50070
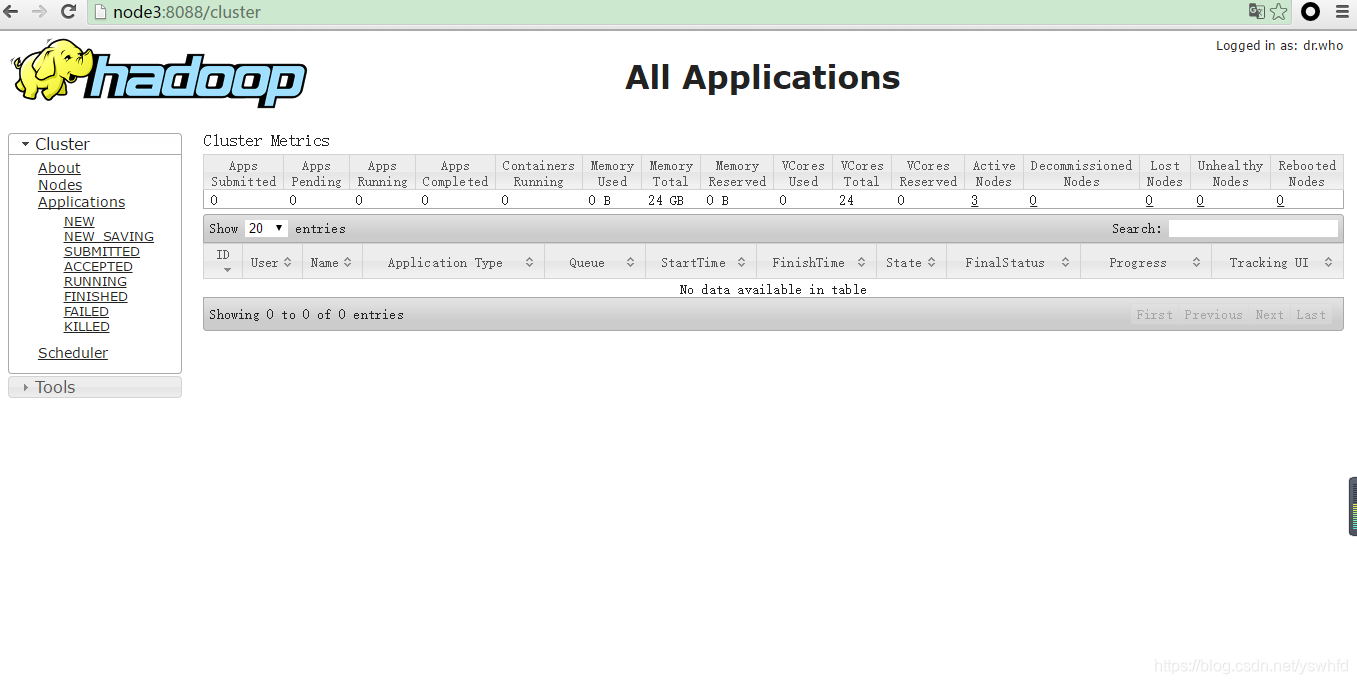
//yarn
node3:8088
node4:8088
6. cd $HADOOP_HOME/share/hadoop/mapreduce
hadoop jar ./hadoop-mapreduce-examples-2.6.0.jar wordcount /usr/root/test.txt /output
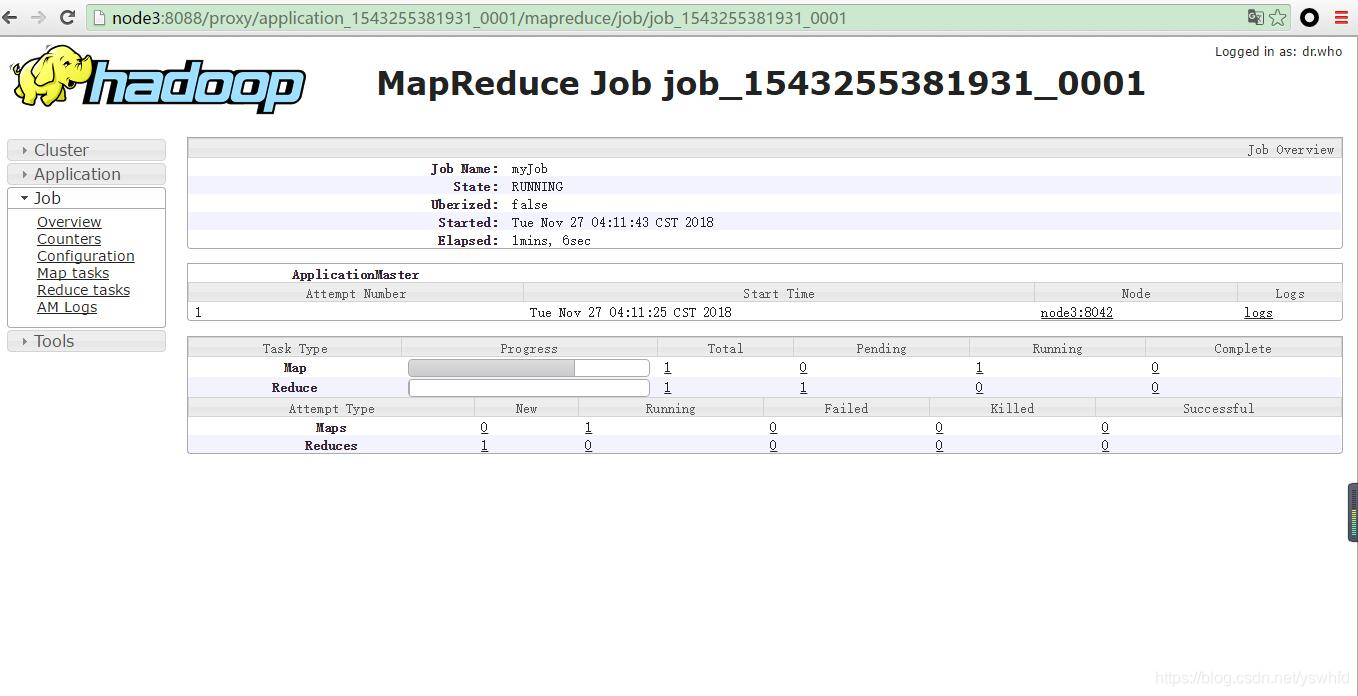
yarn 页面查看
node3:8088
application_1543255381931_0001
7. 日志查看
yarn -kill application_1543255381931_0001
yarn logs -applicationId application_1543255381931_0001 >> application_1543255381931_0001.log
//过滤错误日志
cat application_1543255381931_0001.log | grep Exception >> application_1543255381931_0001--.ex
//可以自己写个脚本
vim killAppLogs.sh
#!/bin/bash
yarn application -kill $1
yarn logs -applicationId $1 > $1-$2.log
cat $1-$2.log | grep Exception > $1-$2-ex
sh kill killAppLogs.sh + applicationId
7.以上是全部配置,如您在安装过程中有任何问题或有更好的意见或建议,欢迎指正交流,V:251753735