1、首先下载selenium。用命令pip install selenium。

2、下载chromedriver,本人的chrome浏览器的版本号是68,对应的chromedriver版本用的是2.40,大家可以参照一下这篇博客https://blog.csdn.net/weixin_42244754/article/details/81541894
3、把下载后的chromedriver.exe放到chrome浏览器的目录和python的根目录,请参考如下的目录信息。


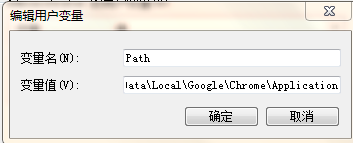
4、在环境变量中进行配置:将C:\Users\Administrator\AppData\Local\Google\Chrome\Application(根据自己的目录进行)添加到环境变量中。
5、注意,如果在步骤3中,chromedriver.exe没有放入python目录下,会出现下图所示的错误,所以切记,切记,切记,一定要在两个目录下都放入。

6、以上就完成了基本的配置,测试一下如下代码:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")执行会重新打开一个百度的界面如下图
