测试环境
hadoop版本:2.6.5
spark版本:2.3.0
hive版本:1.2.2
master主机:192.168.11.170
slave1主机:192.168.11.171
代码实现
针对Hive表的sql语句会转化为MR程序,一般执行起来会比较耗时,spark sql也提供了对Hive表的支持,同时还可以降低运行时间。
1.创建idea工程
pom.xml依赖如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tongfang.learn</groupId>
<artifactId>learn</artifactId>
<version>1.0-SNAPSHOT</version>
<name>learn</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<spark.core.version>2.3.0</spark.core.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.core.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.core.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
</project>
同时将hive-site.xml配置文件放到工程resources目录下,hive-site.xml配置如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- hive元数据服务url -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.11.170:9083</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- hive元数据库访问url -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.11.170:3306/hive?createDatabaseIfNoExist=true&characterEncoding=utf8&useSSL=true&useUnicode=true&serverTimezone=UTC</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- hive元数据库用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- hive元数据库访问密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>chenliabc</value>
</property>
<!-- hive在hdfs上的存储路径 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 集群hdfs访问url -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.11.170:9000</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoStartMechanism</name>
<value>checked</value>
</property>
</configuration>
实例代码:
import org.apache.spark.sql.SparkSession;
public class HiveTest {
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("Java Spark Hive Example")
.enableHiveSupport()
.getOrCreate();
spark.sql("create table if not exists person(id int,name string, address string) row format delimited fields terminated by '|' stored as textfile");
spark.sql("show tables").show();
spark.sql("load data local inpath '/home/hadoop/software/person.txt' overwrite into table person");
spark.sql("select * from person").show();
}
}
person.txt如下:
1|tom|beijing
2|allen|shanghai
3|lucy|chengdu
2.打包运行
在运行前需要确保hadoop集群正确启动,同时需要启动hive metastore服务。
./bin/hive --service metastore
提交spark任务:
spark-submit --class com.tongfang.learn.spark.hive.HiveTest --master yarn learn.jar
运行结果:
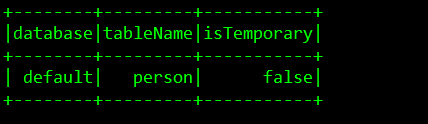

当然也可以直接在idea中直接运行,代码需要细微调整:
public class HiveTest {
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.master("local[*]")
.appName("Java Spark Hive Example")
.enableHiveSupport()
.getOrCreate();
spark.sql("create table if not exists person(id int,name string, address string) row format delimited fields terminated by '|' stored as textfile");
spark.sql("show tables").show();
spark.sql("load data local inpath 'src/main/resources/person.txt' overwrite into table person");
spark.sql("select * from person").show();
}
}
在运行中可能报以下错:
Exception in thread "main" org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.io.IOException: (null) entry in command string: null chmod 0700 C:\Users\dell\AppData\Local\Temp\c530fb25-b267-4dd2-b24d-741727a6fbf3_resources;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:106)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:194)
at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:114)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:102)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.externalCatalog(HiveSessionStateBuilder.scala:39)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog$lzycompute(HiveSessionStateBuilder.scala:54)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog(HiveSessionStateBuilder.scala:52)
at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anon$1.<init>(HiveSessionStateBuilder.scala:69)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.analyzer(HiveSessionStateBuilder.scala:69)
at org.apache.spark.sql.internal.BaseSessionStateBuilder$$anonfun$build$2.apply(BaseSessionStateBuilder.scala:293)
at org.apache.spark.sql.internal.BaseSessionStateBuilder$$anonfun$build$2.apply(BaseSessionStateBuilder.scala:293)
at org.apache.spark.sql.internal.SessionState.analyzer$lzycompute(SessionState.scala:79)
at org.apache.spark.sql.internal.SessionState.analyzer(SessionState.scala:79)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:74)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:638)
at com.tongfang.learn.spark.hive.HiveTest.main(HiveTest.java:15)
解决方案:
1.下载hadoop windows binary包,点击这里。
2.在启动类的运行参数中设置环境变量,HADOOP_HOME=D:\winutils\hadoop-2.6.4,后面是hadoop windows 二进制包的目录。
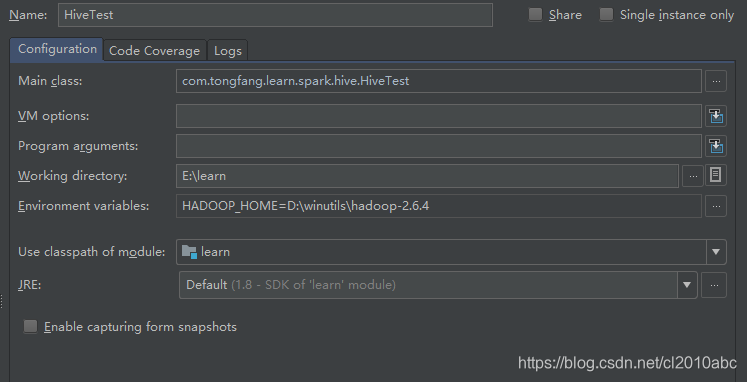
运行结果:


总结
本文讲解了spark-sql访问Hive表的代码实现与两种运行方式。