集成模型及分类
集成模型的思路是三个臭皮匠赛过诸葛亮,利用多个弱的个体学习器结合成为一个强学习器。按照个体分类器的结合方法分为以下两类:
- Boosting trees:
The algorithm works by applying the weak learner sequentially to weighted versions of the data,where more weight is given to examples that were misclassified by earlier rounds.
——《Machine Learning - A Probabilistic Perspective》
典型方法是AdaBoost和GBDT.
- 不同的分类器通过串行训练而获得,每个新分类器都重点关注已有分类器错分的样本来获得新的分类器,递归生成多个分类器
- 采用加权求和的方法获得集成模型
- Bagging aggregated trees
一种典型的方法是随机森林
- 随机重采样获取数据集:随机有放回的方式取样得到与原数据集大小相等的数据集
- 针对此数据集搭建分类器
- 重复1-2操作S次,得到S个分类器
- 最后通过投票的方法输出预测分类结果
本文关注处理二元分类问题且决策树作为弱分类器的集成模型。
Boosting的典型方法Adaboost算法的基本思路
算法示意图

Adaboost算法一言以蔽之,加权后的数据集依据最小化错误率指标建立弱分类器,串行迭代优化直至终止条件,各弱分类器结果加权和即为输出结果。
其中:
- 数据集加权方法:第一次迭代时,所有数据等权重,后续迭代过程,增大上次错分数据的权重。
- 弱分类器建立指标:最小化错误率。
- 串行迭代优化终止条件:错误率为0或达到迭代次数限值。
- 弱分类器加权和涉及到弱分类器的权重的定义。为了保证最佳分类效果,增大错误率低的弱分类器权重,降低错误率高的弱分类器权重,从而得到强分类器。
具体地,
数据集各样本权重的定义:

错误率的定义:

分类器权重的定义:

数据集各样本权重的迭代更新:

最终弱分类器加权和
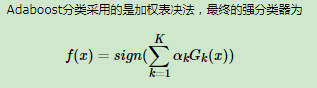
- 流程

- 算法优缺点
优点:不易过拟合
缺点:对异常值敏感
Boosting的典型方法GBDT回归算法的基本思路
算法示意图

GBDT回归算法一言以蔽之,数据集的残差依据最小化损失函数指标建立回归树,串行迭代优化直至终止条件,各弱分类器预测结果累加和即为输出结果。
其中:
- 数据集的残差(负梯度):残差是预测集累加结果与真实结果的偏差。在实际计算中与负梯度相关,当损失函数是square loss时残差与负梯度一致;当损失函数是Absolute loss时,残差的正负性符号等于负梯度;当损失函数为huber loss时,残差较小的样本数据负梯度等于残差,残差较大的样本数据负梯度等于残差的正负性符号。
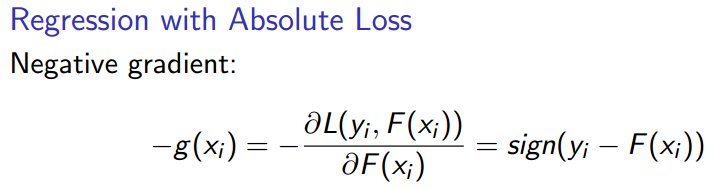

- 弱分类器建立指标:最小化损失函数。与AdaBoost方法不同地方主要是 GBDT损失函数的选择范围更广,同时对异常值的敏感度较低。


- 串行迭代优化终止条件:达到迭代次数限值(即分类器个数)。
- 弱分类器的累加和:由于GBDT是基于前次分类器的残差进行优化的,各分类器的结果是增量,因此最终函数结果为所有分类器的增量结果累加和。
GBDT分类算法
由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从单个弱分类器的输出类别计算残差。
主要有两个方法解决这个问题,一个是用指数损失函数,此时GBDT退化为Adaboost算法。 另一种方法类似于逻辑回归的对数似然损失函数,将类别的预测概率值与真实概率值的差作为损失,根据负梯度拟合残差回归树,将各残差回归树的增量结果累加得到最终预测结果。本文仅讨论用对数似然损失函数的GBDT二元分类。
具体计算流程如下:

- 算法优缺点
GBDT主要的优点有:
- 可以灵活处理各种类型的数据,包括连续值和离散值。
- 使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
GBDT的主要缺点有:
- 由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
Bagging的典型方法随机森林算法的基本思路
算法示意图

随机森林算法一言以蔽之,对于随机采样选取的数据集,在随机选择的部分样本特征中,选择一个最优的特征依据基尼不纯度或总方差指标建立CART决策树,并行得到多个决策树,各决策树预测结果通过投票输出最终结果。
其中:
- 随机采样选取的数据集:有放回地选取与源数据集相同个数的样本集,shape为(p,q)
- 随机选择的部分样本特征:m<q。
对于普通的决策树,我们会在节点上所有的q个样本特征中选择一个最优的特征来做决策树的左右子树划分,但是RF通过随机选择节点上的一部分样本特征,这个数字小于q,假设为m,然后在这些随机选择的nsub个样本特征中,选择一个最优的特征来做决策树的左右子树划分。这样进一步增强了模型的泛化能力。
- 基尼不纯度或总方差指标:CART决策树
- 并行得到多个决策树, 如果是分类算法预测,则多个决策树投出最多票数的类别或者类别之一为最终类别。如果是回归算法,多个决策树得到的回归结果进行算术平均得到的值为最终的模型输出。
- 算法优缺点
RF的主要优点有:
- 训练可以高度并行化,对于大数据时代的大样本训练速度有优势
- 由于可以随机选择决策树节点划分特征,这样在样本特征维度很高的时候,仍然能高效的训练模型
- 在训练后,可以给出各个特征对于输出的重要性
- 由于采用了随机采样,训练出的模型的方差小,泛化能力强
- 相对于Adaboost和GBDT, RF实现比较简单
- 对部分特征缺失不敏感。
RF的主要缺点有:
- 在某些噪音比较大的样本集上,RF模型容易陷入过拟合
- 取值划分比较多的特征容易对RF的决策产生更大的影响,从而影响拟合的模型的效果
分类器的性能评估指标
首先我们需要理解confusion matrix(混淆矩阵)。混淆矩阵是真实结果与预测结果配对值,形如:
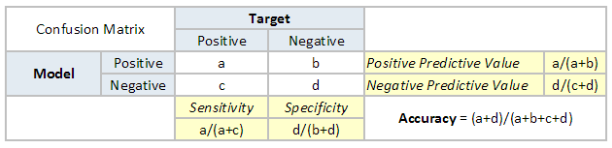
其中:
TP(a)——真实结果为真的同时预测结果为真
TN(d)——真实结果为假的同时预测结果为假
FP(b)——真实结果为假的同时预测结果为真
FN(c)——真实结果为真的同时预测结果为假
使用这些值,我们可以计算模型的准确度。
Accuracy(准确度)=(TP+TN)/(TP+TN+FP+FN)描述预测准确比例
Precision(精确度)=TP/(TP+FP) 描述预测为真的准确比例
Recall(覆盖度,Sensitivity)=TP/(TP+FN)描述实际为真的预测准确比例
Specificity(真阴率)=TN/(TN+FP)描述实际为假的预测准确比例
Receiver Operating Characteristic(ROC) 通过真阳率(Sensitivity)和假阳率(1-Specificity)总结模型性能???
The area under curve (AUC)是ROC曲线与x轴形成的图形面积,描述了模型准确分类的能力。该值越大,模型性能越好。

参考