最近在研究拜占庭共识,做个记录吧,有些可能也没理解透。
RBFT : Redundant Byzantine Fault Tolerance
论文地址:http://lig-membres.imag.fr/aublin/rbft/report.pdf
摘要:
提出其他已有的BFT算法(prime、Aardvark、Spinning)其实并不能真正的进行拜占庭容错,主要是由于存在一个“primary”用来排序的。如果primary作恶,整个系统的性能会显著下降而且不会被发现。而RBFT则提出了新的模式:采用多核机机器并行执行多个PBFT的协议实例,只有master实例的结果会被真正执行,每个协议实例都会被监控其性能并与master实例比较,如果master的性能不行,则会认为此master的primary节点为坏节点并发起替换流程。据测算RBFT在存在BFT攻击时的性能下降最大为3%,而其他的协议为:Prime(78%)、Aardvark(87%)、Spinning(99%)。
RBFT协议:
综述:
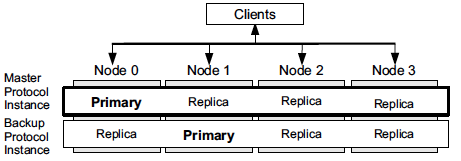
N= 3f+1个nodes(f为拜占庭节点最大数),每个node里并行跑f+1个(why?:如果f个实例的primary都是坏节点,那么系统将无法识别拜占庭错误。当f+1个的时候就能保证,见下面的定理或者引理)BFT实例(PBFT协议),只有一个为master,其他的实例为backup。每个实例都有自己的replica,f+1个实例的primary必须满足:每个node最多只是一个实例的primary。每个实例都会对请求排序,但是只有master才会真正的执行,backup只排序与master性能作比较。每个node会运行一个监控程序,监控所有f+1个实例的吞吐量。如果2f+1个node发现master和最佳的backup实例性能差达到一定阈值则此master的primary节点会被认为是恶意节点,将会选出新的primary,还可以选择将表现最好的backup升级为master不过这样需要一个机制在切换master的时候保证各个实例状态的同步(机制参考文献11)。RBFT正确的工作需要f+1个实例接收到的是同样的客户端请求。不过当一个node收到req的时候并不会直接给他自己的f+1个实例运行,而是先转发给所有的其他节点。当他收到2f+1(why?:一定会收到2f+1个,不过应该只需要f+1就可以确定好节点一定都收到了这个请求)个客户端请求copy时(包括自己的)此节点会每一个好节点最终都会接收到请求(因为请求至少发送给了一个好节点)然后再将请求发给f+1个实例去执行。与Aardvark不同的是,RBFT的view change是又监控策略控制并且应用到所有f+1个实例里,而Aardvark由协议发起。
具体步骤:
1、客户端吧请求发送到所有节点
请求格式如下:o:请求操作,rid:请求标识符,c:client
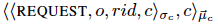
客户端需要用私钥签名,通过MAC认证。节点接到请求需要验证签名、MAC认证,如果不对则加入黑名单不执行后续。如果请求已经执行过,则直接返回执行结果给client。
2、好节点传播(propagate)请求给所有节点
传播信息格式如下:
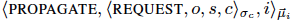
请求验证通过则节点发送PROPAGATE信息给所有其他节点。此过程可以保证只要有一个好节点收到了请求那么每一个好节点最终都会收到请求。节点接收其他节点的PROPAGATE信息要验证其MAC认证和签名。如果有效,且之前没有接受过此reqest则会发送PROPAGATE给其他节点(这么说即使client没发到节点也可以通过其他节点传来的做验证,然后转发,让其他节点也收到此req)。当一个节点收到f+1(why?:只要有一个好节点收到了这个request则所有的request就会收到这个request)个PROPAGATE信息(针对某个req)则此请求就准备好给f+1个实例去执行排序了(只排序标识符而不是整个请求即:client id 、reqest Id、 hash值,这么做可以提高性能,毕竟处理字节少了)(why?不怕被改以后无法恢复req么)。
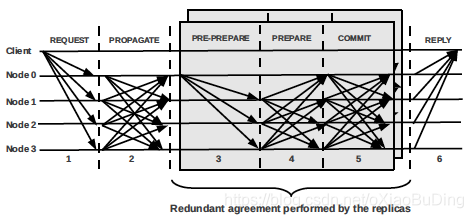
3、4、5 、 每个实例执行一个3阶段提交协议(PBFT协议)来对请求排序
RBFT的三阶段请求 (只有MAC验证)
每个实例的primary replica接收到请求后发送PRE-PREPARE消息给其他节点,包含MAC认证。非primary的replica则会存储此请求并等待对应的primary的PRE-PREPARE消息并验证其MAC。当node收到f+1个同样的request后然后这些非primary replica发送PREPARE消息给所有的replica。如果有2f个(primary不转PREPARE,最多f个是坏掉的,那么f个是好的,加上本身比坏的返回多)PREPARE和PRE-PREPARE消息吻合,则replica发送COMMIT消息给所有replica,MAC认证。收到2f+1个COMMIT信息后会将这此排好序的请求返回给其运行的node上。
6、节点执行请求并发送返回给client
RBFT的处理过程。(只有MAC验证)
节点收到排好序的请求后会执行master 的返回的请求。执行完毕后会返回给client结果,MAC认证。当客户端接收到f+1个REPLY有效且一致的返回后则接受此返回作为request执行的结果。
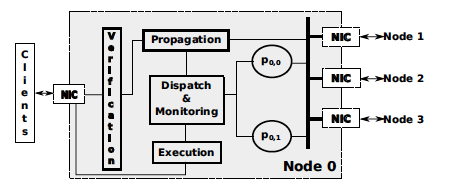
监控机制:
RBFT提供一个监控机制来发现master实例是否坏掉了。
每个节点为每个实例维护一个计数器(一共f+1个),用来记录此实例已经排序的请求数(也就是说收到2f+1个COMMIT消息的请求数)。节点会使用这些计数器周期性的计算每个实例的吞吐量并更新计数器。以下一些情况master会认为坏掉了触发协议实例变更:
1、master的吞吐量比backup的平均吞吐量低达到一定阈值。阈值是根据无拜占庭错误和有拜占庭错误的吞吐量差异设定的。
2、监控程序还监控排序时间,此机制为了保证master对于所有的client处理都是公平的。设定了每个请求的最大处理时间和client在不同实例里处理的时间差值。如果请求超过最大处理时间或者某个client在不同的实例里处理的时间差异过大也会触发协议变更
协议实例变更机制:
变更坏掉的primary。由于每个节点最多是一个实例的primary所以要动就是要所有primary全动。
每个节点维护一个计数器来记录每个实例的变更信息。如果节点发现需要变更primary则会发送INSTANCE CHANGE消息给所有的节点,MAC认证。节点接收到传来的INSTANCE CHANGE消息后验证MAC,然后跟自身的计数器比对,如果自身的更大,则忽略,如果传来的更大则查看自己是否也需要传播INSTANCE CHANGE消息(也是比较master和backup的性能),如果收到2f+1个有效的INSTANCE CHANGE消息则计数器加1然后启动view change流程(就是改primary,PBFT也是)。此后每个实例的primary都得到了更新,当然也包括master 的。(更新策略如果又换到了坏的呢?那会触发再次更新。。 前面提到的直接换最好的backup为master可能会更好点)
两种BFT攻击形式:
f个node是坏的,所以运行在此node里的所有实例都是坏的,所有的client都是坏的。
master实例运行的primary的node是好的:
此时:坏节点的目标是尽可能降低master实例的性能而不触发协议变更(why要不触发协议变更?: 论文里有证明,当primay of master为好节点时不会触发,主要是master的吞吐量比backup的平均吞吐量低达到一定阈值的这个阈值是不是随意定的是根据理论算出来的)。
方式:
- client发送req请求给所有节点,master primary节点请求验证无效,其他有效
- faulty node 给master primary节点发送无效的最大size的PROPAGATE消息,给他其他的正常
- faulty node 在master实例的replica发送最大的消息
- faulty node 在master实例的replica不参与协议
master实例运行的primary的node是坏的:
此时:坏节点的目标是尽可能的降低backup实例的性能,这样就可以留给坏的primary富裕的空间来降低master的性能而不被发现(怎么定义发现?)。
方式:
- client 给好节点发送无效的请求
- faulty node给好节点发无效且最大size的消息并且不参与PROPAGATE阶段
- faulty node在backup节点上的replicas发送无效信息,且不参与协议。
论文中的几个定理或者引理:
- 如果primary of master 是好的那么不会触发instance change
- 如果primary of master 是坏的并且吞吐量过低满足限制条件,则一定会触发instance change
- 要确保拜占庭容错,必须至少运行f+1个实例