软工个人项目之生成和求解数独
在这次完成个人项目的过程中,我第一次尝试了写csdn博客,用vs进行性能分析,在vs里面写单元测试,这次收获了很多。虽然还有很多需要改进的地方,但我会做得越来越好的~
1、Github地址
首先给出我的github的地址:
https://github.com/hll455/Project-Sodoku
2、psp表格—估计花费时间
| psp2.1 | Personal Software Process Stages | 预估耗时(分钟) |
|---|---|---|
| Planning | 计划 | 30 |
| Estimate | 估计这个任务需要多少时间 | 20 |
| Development | 开发 | 1440 |
| Analysis | 需求分析(包括学习新技术) | 1000 |
| Design Spec | 生成设计文档 | 40 |
| Design Review | 设计复审(和同事审核设计文档) | 60 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 90 |
| Design | 具体设计 | 1200 |
| Coding | 具体代码 | 1200 |
| Code Review | 代码复审 | 600 |
| Test | 测试(自我测试、修改代码、修改提交) | 1200 |
| Reproting | 报告 | 1200 |
3、解题思路
1)生成数独
之前对数独没有太多了解,只知道数独每一行每一列每一宫都需要满足1-9不重复。我对生成数独的第一理解,就是相当于对全是0的数独的求解,由于第一行第一个数固定,所以第一行固定排列(一共有8!=40320种),之后开始递归搜索遍历,这样生成到最后一个数字时则生成了数独;生成一个数独之后,可对整个数独进行转置40320✖2=80640,再对2、3行,4、5、6行,7、8、9行交换顺序,这样就可以满足(80640✖2✖6✖6>1000000)。但具体实现时,发现这样的话每生成一个数独的递归求解时,会花费很多时间,在结果的性能评分上肯定不行,所以我就去网上找了一下数独有没有什么简单的规律,比如只需要确定一行,剩下的都可以直接写出来,果然,有一种简单数独就是这样的规律,即:只需要确定第一行,后面的8行都可以通过平移第一行来获得。
6 1 2 3 4 5 7 8 9
7 8 9 6 1 2 3 4 5
3 4 5 7 8 9 6 1 2
9 6 1 2 3 4 5 7 8
5 7 8 9 6 1 2 3 4
2 3 4 5 7 8 9 6 1
8 9 6 1 2 3 4 5 7
4 5 7 8 9 6 1 2 3
1 2 3 4 5 7 8 9 6
由上面的数组可以看到,以第一行为基准,9行分别移动的位数为{0,3,6,1,4,7,2,5,8},根据此位移数组,我们可以根据第一行唯一确定一个数独。生成一个数独后,剩余的数独与上面类似,都可以转换成位移数组的位置交换来体现:即3,6可以互换,8,2,5可以互换,7,1,4可以互换,这样可以生成8!✖2✖6✖6=2903040>1000000,符合题目要求。
2)求解数独
我看到求解数独时,思路就是按照我们做数独的思路,当所在位置的数字为0的时候,我们就找这一行、这一列、这一宫有没有1-9中没有出现的数字,有的话则继续往后填写,没有的话则返回上一步,将上一步填写的数字换成另外一个符合要求的数字,依次类推,直到数独中的最后一个0被填充完成,则求解成功。这样的话,只需要递归求解就好,不过如果每次对一个0的那一行那一宫那一列遍历的话,时间复杂度会很高,所以我采取“以空间换时间”,对数独进行预处理,直接将行列宫的数字出现与否用数组表示出来,这样,在每次判断是否可以填入某数时,则不需要进行遍历,只需要直接查看该数组的某一个元素的值是否为0。这里我设置了一个三维数组大小为visit[3][10][10]的数组,利用每个元素的值来表示该宫/行/列中的某个数字是否出现过,0为未出现,1为出现。visit数组第一维中0表示宫,1表示行,2表示列,第二维中表示第几行/第几列/第几宫(范围为0到9),第三维表示1-9数字。
4、设计实现过程
1)类与函数及函数间关系
其实最开始写的代码为面向过程的c语言,后来因为单元测试需要类,所以我将面向过程直接改成了面向对象的c++。
只设置了一个类sodoku,将输入的两个参数作为属性;
主要设置了三个函数,其中choosecors函数对solvesodoku和createsodoku函数进行调用。
-
choosecors函数——对输入的参数进行处理,
-
createsodoku函数——生成数独,
-
solvesodoku——求解数独。
流程图如下所示:
2)单元测试的设计
我设计了10个测试用例,其中5个检查生成数独时输入参数的合法性,1个测试非-s和-c的输入的处理,2个测试求解数独的正确性和格式的正确性,2个检查生成数独时输入参数的合法性。完成对所有路径的测试,除了输入时的参数个数问题不能在单元测试中体现。
十个测试用例分别为:其中choosecors函数的输入参数分别为argv[1]和argv[2]
1、int ans = s1.choosecors("-c", "a");
2、int ans = s1.choosecors("-c", "1000001");
3、int ans = s1.choosecors("-c", "123");
4、int ans = s1.choosecors("-c", "-1");
5、int ans = s1.choosecors("-c", "");
6、int ans = s1.choosecors("-a", "123");
7、int ans = s1.choosecors("-s", "test1.txt");
8、int ans = s1.choosecors("-s", "123.t");
9、 s1.choosecors("-s", "test2.txt");
10、s1.choosecors("-s", "test1.txt");
-前八个分别用ans获得返回值与期望值进行比较 ,后两个用print数组与设定的期望数组进行比较
3)单元测试的实例截图(其中三个)
由于篇幅有限,这里只放三个,剩下的可以在代码库中看到。
a、s1.choosecors("-s", “test1.txt”);
测试cpp中:
TEST_METHOD(TestMethod10)
{
// TODO: Your test code here
sudoku s1;
s1.choosecors("-s", "test1.txt");
char aa[300] = {
"6 1 2 3 4 5 7 9 8\n"
"3 4 5 9 7 8 6 1 2\n"
"9 7 8 6 1 2 3 4 5\n"
"1 8 3 4 2 9 5 7 6\n"
"4 5 9 7 8 6 1 2 3\n"
"7 2 6 1 5 3 4 8 9\n"
"2 3 4 5 9 7 8 6 1\n"
"5 9 7 8 6 1 2 3 4\n"
"8 6 1 2 3 4 9 5 7\n"
};
Assert::AreEqual(aa, print);//print为输出至文件的字符串
}
其中test1.txt如下所示:
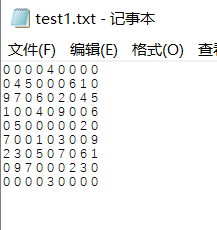
b、int ans = s1.choosecors("-c", “a”);
测试cpp中:
TEST_METHOD(TestMethod1)
{
// TODO: Your test code here
sudoku s1;
int ans = s1.choosecors("-c", "a");
Assert::AreEqual(1, ans);
}
源代码中:
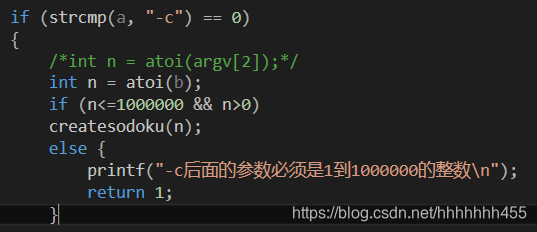
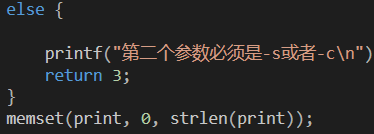
c、int ans = s1.choosecors("-a", “123”);
测试cpp中:
TEST_METHOD(TestMethod6)
{
// TODO: Your test code here
sudoku s1;
int ans = s1.choosecors("-a", "123");
Assert::AreEqual(3, ans);
}
源代码中:
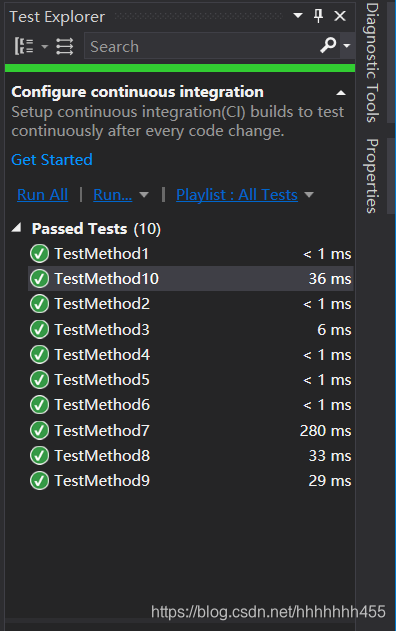
3)单元测试的结果
对于十个测试用例,实际值与预期值都相同,如图所示:
5、关于改进
在完成基本功能过后,改进算是花了很多时间吧,从完成基本功能到一些小bug的修复,再到各种情况输入的处理,最后到性能时间的优化。这里主要说明性能的优化过程。
1)关于输出至文件
最开始实现生成和求解数独的时候,没有直接输入到文件,而是用printf打印到命令行里。个数少的时候还好,但是个数多时发现占的时间很多,如下图所示:
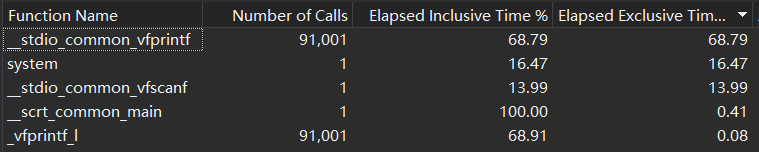
后来输入至文件的时候,对于生成数独,我采取了生成一个字符便fputc的办法,而求解数独时采用的是生成一个数组便puts,发现效果不尽人意。于是后来想到了一个办法,那就是将所有的要输入至文件的字符串全部存进一个字符数组里(包括要求格式里的空格和回车)。这里我采用的是一个print数组,用整型变量p表示指针,随着p的移动来将字符插入print数组里,最后一起fputs入文件;同样的求解数独里,我将save数组一个接一个的拼接至print数组里再一起fputs入数组。这样,时间有很大程度的缩减,但其实输出依旧占据了很大时间。
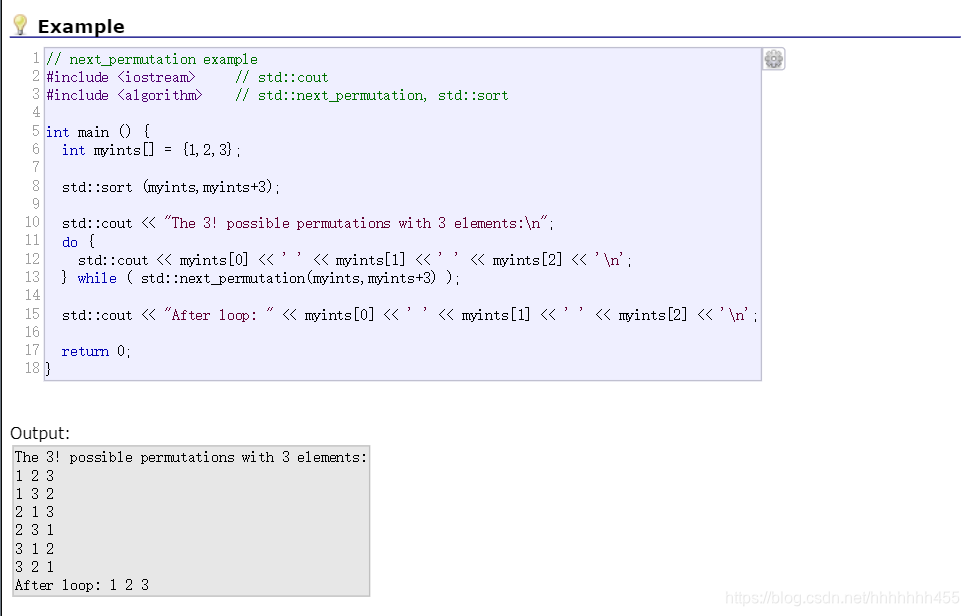
2)关于生成数独里的next_permutation
这是一个生成全排列函数,是在我对数独考虑全排列变换时发现的一个函数,据说它的效率很高,可以生成不重复的下一个全排列函数,具体的介绍在下一个代码部分。刚开始接触到这个函数时便直接使用了,不管第2、3行的2个排列还是4、5、6,7、8、9行的分别6个全排列,我在createsodoku函数里写了4次next_permutation。后来,我在性能分析时发现,其实next_permutation花费的时间也很多,原因是这个函数调用了很多其他的函数,比如交换函数。在生成100000个数独里如果反反复复的调用它,花费时间在整个运行程序中会更加突出。如下图所示:
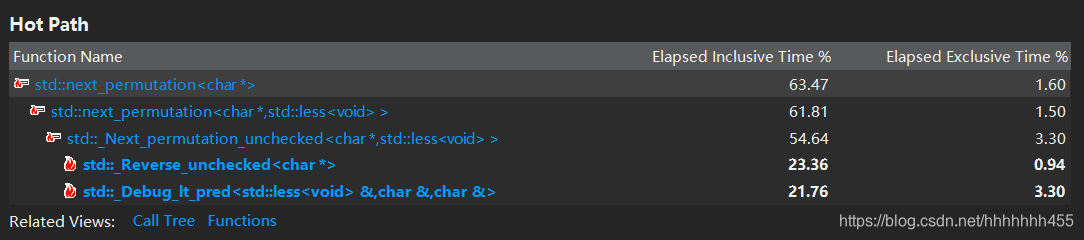
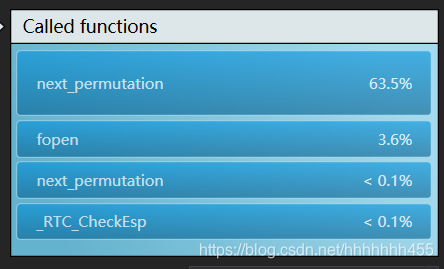
之后我的解决方法就是争取少用next_permutation。我将行交换的72种排列放入一个二维字符数组里直接进行求解,另外将next_permutation放在外层,尽可能地少调用…(ps:这个方法太笨了,如果不是为了更快我是不会用的…)
3)展示性能分析图
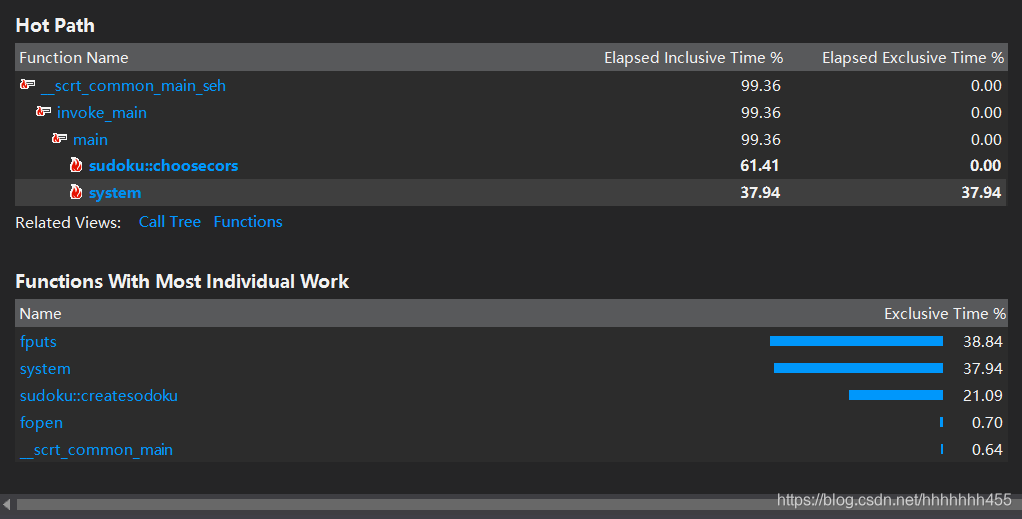
a、生成数独
1000000个运行时间大概在2.6s左右,感觉还可以再优化的,因为周围有同学只有1.5s左右。我尝试将fputs改成ofstream里的输出至文件,还尝试了改变将整型数组改成字符数组,但速度并没有有所提升,所以就放弃了,如果我还有时间提升性能的话,应该就要修改算法了。

生成数独的性能分析图如下所示:由图可见,占用时间最多的还是fputs函数。
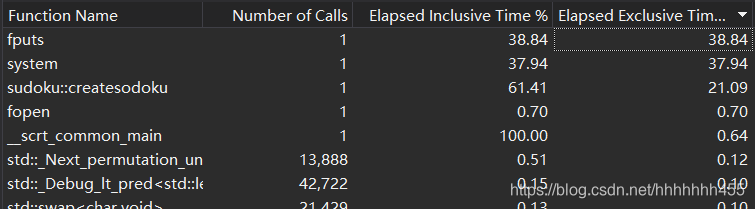
b、求解数独
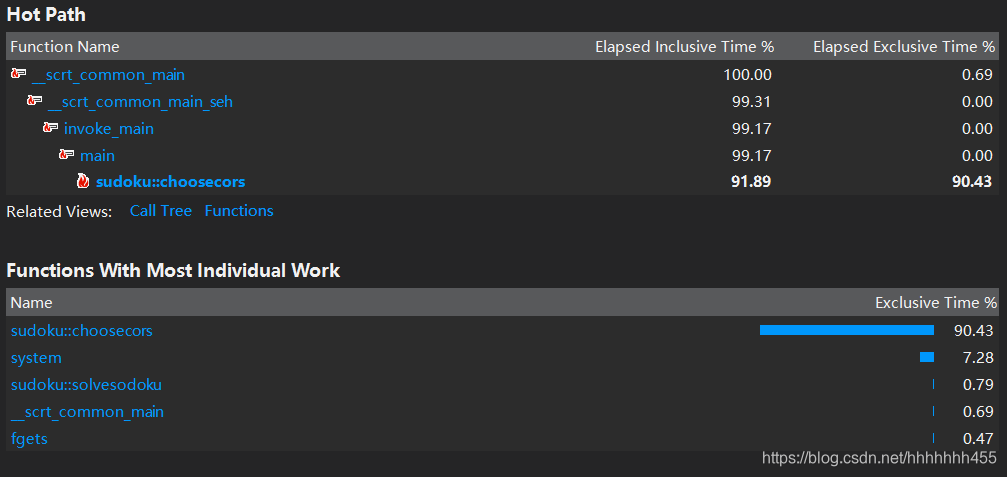
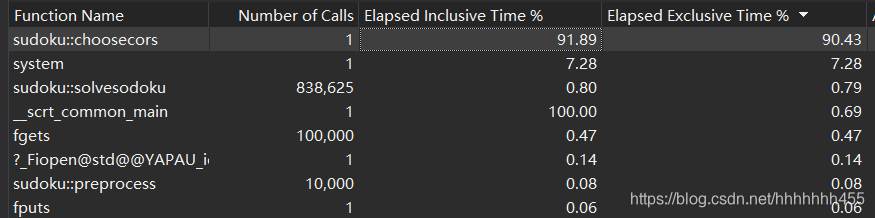
没有过多优化来缩短时间,如果继续优化的话,我应该考虑在预处理choosecors函数上进行更深度的优化,下面是它的性能分析图
6、关键代码说明
1)choosecors函数:int sudoku::choosecors(char a[], char b[])
a、生成数独分支
这里利用atoi函数将字符串转换成数字,b为输入的生成数独的个数。这里atoi也能保证输入的合法性,如果b为字母,则atoi(b)=0,跳入return1的分支。
int n = atoi(b);
if (n<=1000000 && n>0)
createsodoku(n);
else {
printf("-c后面的参数必须是1到1000000的整数\n");
return 1;//方便单元测试
}
return 6;//方便单元测试
b、求解数独分支
输入的第二个参数作为fp2,进行读入。由于fgets以回车视为结尾,所以每次获取一行,num表示行数,当集满9行时进行处理,首先进行预处理,预处理中设置visit函数,再进入solvesodoku进行递归求解,最后将每次求得的数独带空格和回车地拼接到输出字符串print。print负责将所有字符串输出至sudoku.txt文件里。
while (!feof(fp2)) {
fgets(temp, 22, fp2);
if (strcmp(temp, "\n") == 0)
continue;
strcat(save[num], temp);
num++;
if (num == 9) {
num = 0;
//save数组已经装下一个数独,开始求解
memset(visit, 0, sizeof(visit));
/*初始化visit 行列宫都属于[0,8]*/
//注意 每一行一个数字过后紧跟着空格 换算至没有空格时候的visit数组
findans = 0;
preprocess();//预处理函数
solvesodoku(0, 0);
//firstsodoku初始值为1
//是为了满足输出时最后一个数独后没有空行而引入的变量
if (firstsodoku == 0) {
char temm[] = "\n";
strcat(print, temm);
}//如果不是第一行 则在前面输出空格
if (firstsodoku == 1) {
firstsodoku = 0;
}
for (int i = 0; i<9; i++)
strcat(print, save[i]);
memset(save, 0, sizeof(save));
memset(visit, 0, sizeof(visit));
}
}
c、预处理函数
visit函数在设计部分我有介绍,是利用每个元素的值来表示该宫/行/列中的某个数字是否出现过,进行预处理后,求解数独时便不用每行每列每宫进行遍历。save数组为输入的一个数独,带每行末尾的回车和每行内的空格,在进行预处理时,需要跳过空格,考虑save中实际数字和visit数组的对应关系。
for (int i = 0; i < 9; i++)
for (int j = 0; j < 17; j++)
{
if (save[i][j] != '0'&& save[i][j] != ' ')
{
visit[0][i / 3 * 3 + j / 6][save[i][j] - '0'] = 1;//宫
visit[1][i][save[i][j] - '0'] = 1;//行
visit[2][j / 2][save[i][j] - '0'] = 1;//列
}
}
2)createsodoku函数:
这里需要介绍的是next_permutation函数,这个函数是全排列函数,能够保证不重复的得到全部的全排列,符合我们的要求。参考的网址为http://www.cplusplus.com/reference/algorithm/next_permutation/,这里介绍了它的用法,符合我的设计需要,具体用法如下图所示。这里我利用next_permutation函数,进行第一行后面8个数,第2、3行,第4、5、6行,第7、8、9行的全排列,保证生成的数独不重复而且符合要求。
下面是我的最终修改前的createsodoku函数:
void sudoku::createsodoku(int n)
{
FILE* create_outputfile;
create_outputfile = fopen("sudoku.txt", "w");
if (!create_outputfile)
{
printf("CANNOT open the sudoku.txt!\n");
exit(1);
}
int shift[9] = { 0,3,6,1,4,7,2,5,8 };
char num[10] = "612345789";
for(int i = 0; i < 2 && n; i++)
{ //第2、3行交换
if (i)
next_permutation(shift + 1, shift + 3);
for (int j = 0; j < 6 && n; j++)
{//第4、5、6行交换
if (j)
next_permutation(shift + 3, shift + 6);
for (int k = 0; k < 6 && n; k++)
{//第7、8、9行交换
if (k)
next_permutation(shift + 6, shift + 9);
for (int l = 0; l < 40320 && n; l++)
{//8个数字的全排列
if (l)
next_permutation(num + 1, num + 9);
//生成一个数独
for (int m = 0; m < 9; m++)
{
for (int h = 0; h < 9; h++)
{
print[p++] = num[(h + shift[m]) % 9];
if (h != 8)
print[p++] = ' ';
}
print[p++] = '\n';
}
n--;
//保证除了最后一个数独末尾只有一个回车,其余数独的末尾都有两个回车
if (n!=0)
print[p++] = '\n';
sum++;
}
}
}
}
fputs(print, create_outputfile);
//注意一定要fclose
fclose(create_outputfile);
}
在性能分析时,由于发现next-permutation函数耗费时间过大,于是将部分的全排列函数手动排列放如字符数组里直接进行处理…这样确实快了将近1s。修改后的部分函数内容为:
//change二维字符数组记录了2、3行,4、5、6行,7、8、9行的全排列结果。
for (int j = 0; j < 40320 && n; j++) {
if (j)
next_permutation(num + 1, num + 9);
for (int i = 0; i < 72 && n; i++) {
//下面是生成一个数独
for (int m = 0; m < 9; m++)
{
for (int h = 0; h < 9; h++)
{
print[p++] = num[(h + (change[i][m]-'0')) % 9];
if (h != 8)
print[p++] = ' ';
}
print[p++] = '\n';
}
n--;
if (n!=0)
print[p++] = '\n';
}
}
print[p] = '\0';
3)solvesodoku函数部分:void sudoku::solvesodoku(int i, int j)
这里主要是一个递归,处理数独中为0的地方。k从1到9向里面填数,凡是符合0所在行所在列所在宫没有出现这个数即可填入,再进入下一个递归。如果没有找到符合要求的数而又没有求解完成,则进入上一层递归重新填数,直到求解完成。findans用来判断是否读到最后一个字符。
if (save[i][j] == '0')
{//解
bool flag = 0;
for (int k = 1; k <= 9; k++)
{
if (visit[0][i / 3 * 3 + j / 6][k] == 0 && visit[1][i][k] == 0 && visit[2][j / 2][k] == 0)
{//找到符合要求的数字
save[i][j] = k+'0';
visit[0][i / 3 * 3 + j / 6][k] = 1;//宫
visit[1][i][k] = 1;//行
visit[2][j / 2][k] = 1;//列
flag = 1;
solvesodoku(i, j);
}
if (flag)
{
flag = 0;
if (findans)
return;
else
{
save[i][j] = '0';
visit[0][i / 3 * 3 + j / 6][k] = 0;//宫
visit[1][i][k] = 0;//行
visit[2][j / 2][k] = 0;//列
}
}
}
}
7、利用cppcheck进行代码质量分析
消除了所有警告:

8、psp表格—实际花费时间
| psp2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| Estimate | 估计这个任务需要多少时间 | 20 | 10 |
| Development | 开发 | 1440 | 1200 |
| Analysis | 需求分析(包括学习新技术) | 1000 | 1000 |
| Design Spec | 生成设计文档 | 40 | 60 |
| Design Review | 设计复审(和同事审核设计文档) | 60 | 40 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 90 | 60 |
| Design | 具体设计 | 1200 | 1440 |
| Coding | 具体代码 | 1200 | 1500 |
| Code Review | 代码复审 | 600 | 1200 |
| Test | 测试(自我测试、修改代码、修改提交) | 1200 | 1500 |
| Reproting | 报告 | 1200 | 1000 |