今天我们来完成一个小项目《实战爬虫》-爬取熊猫直播平台的数据。
爬虫到底是个怎么回事呢?
爬虫,模拟网页发出抓取数据的请求,也就是一个抓取目标数据的一个过程。
过程:
模拟HTTP请求,向服务器发送这个请求,获取到服务器返回我们的HTML。
用正则表达式提取我们要的数据(名字+人气)。
所以,正则表达式是一个必备的工具,需要熟练掌握,打下学习Python爬虫的基础。
那么,做爬虫的时候,我们分成三个策略步骤:
1.明确你的目的数据,要抓取哪些信息。
2.找到你的目的数据所在的网址。
3.分析网页的结构找到数据所在的标签位置。
除此之外,我们还需要知道要引用哪些功能模块:
import re:要用正则表达式来抓取数据。
from urllib import request:负责打开浏览url内的html文本。
现在我们来打开熊猫直播平台,选取一个人最多的模块,不出意外应该是LOL模块:
https://www.panda.tv/cate/lol

要抓取的数据肯定是选主播的名字+实时人气,然后进行一个排行。
F12打开开发者模式,查看源码。
分别找到主播名字和实时人气所在的位置。
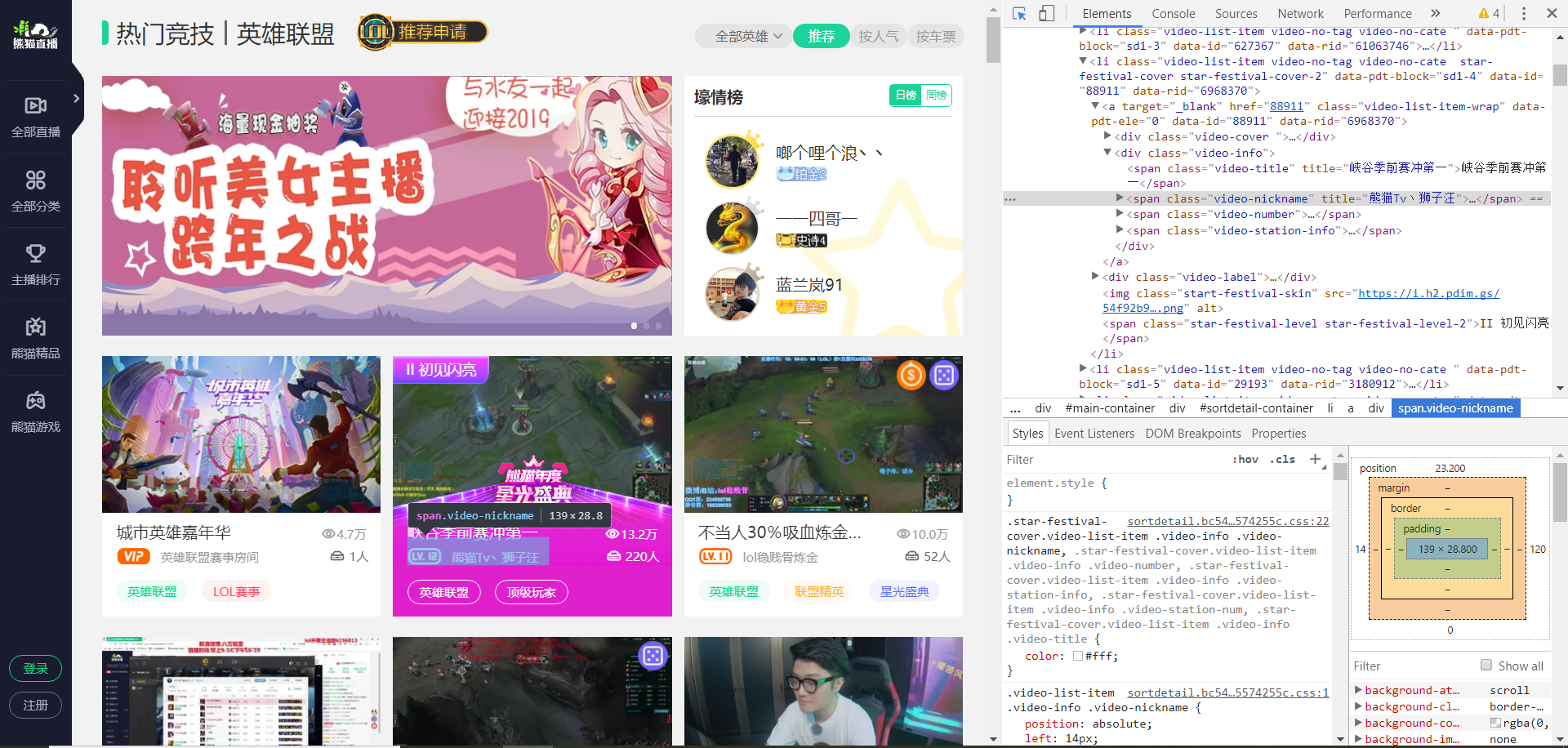
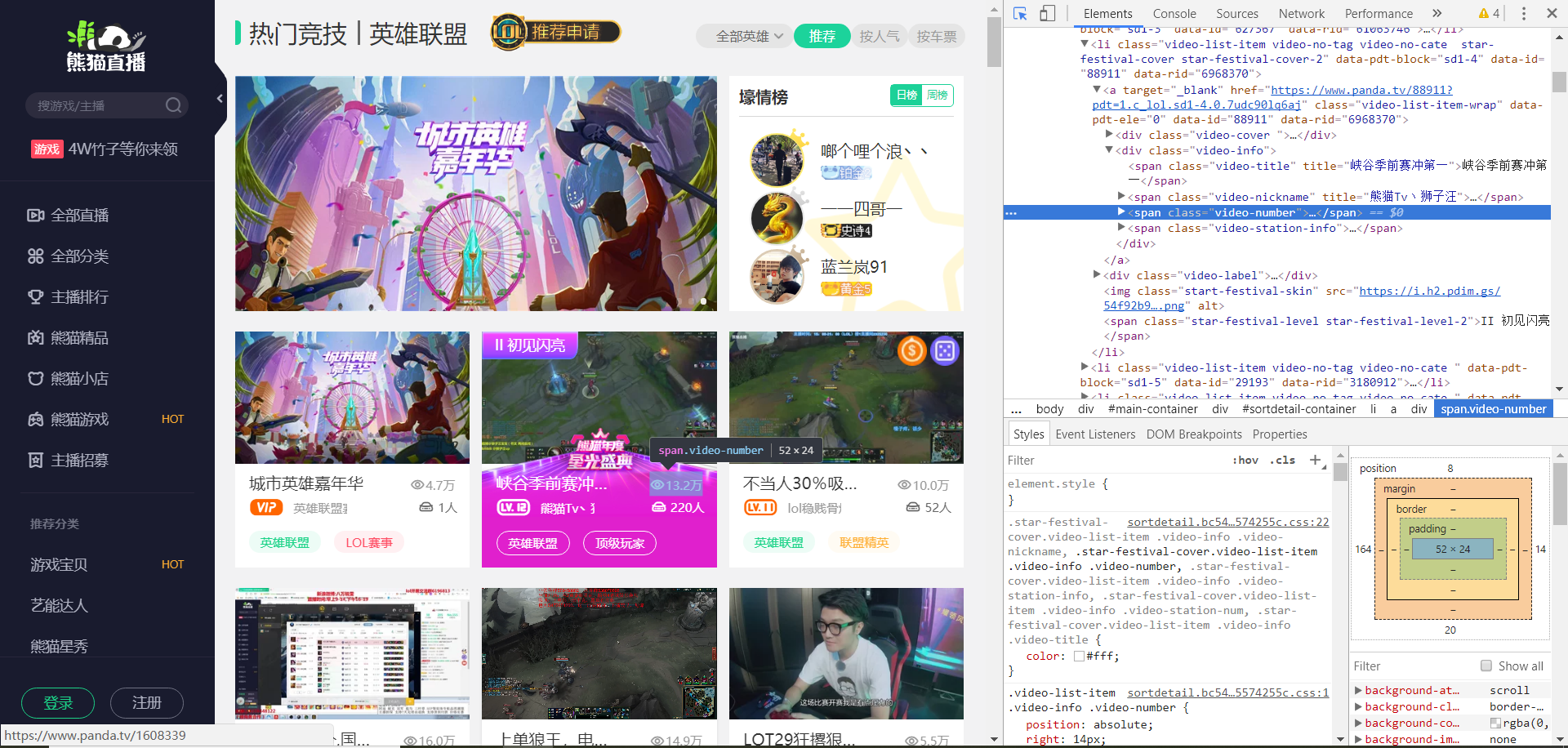
我们可以发现,这两行代码正好是放在一起的,然后我们自然就是根据代码来找名字和人气的位置。


我们可以发现,这两个我们要抓取的数据,都是被</i> </span>所包裹着,但是我们肯定不能弄一样的正则表达式寻找方式啊,不然代码就会有BUG。
于是我重新给实时人气找另一种的正则表达式寻找方式,我们把上面给折叠掉:

这样,这两种数据的抓取方式都出来了:
主播名字:</i>([\s\S]*?)</span>
实时人气:<i class="ricon ricon-eye"></i>([\s\S]*?)</span>
([\s\S]*?)就是我们的目标数据了,进行贪婪的匹配模式,关于贪婪匹配的知识点我们需要了解到。
那么问题来了,我们是要爬取所有lol主播的数据,并进行一个排行。所以我们得找到存储这两个数据的html模块:
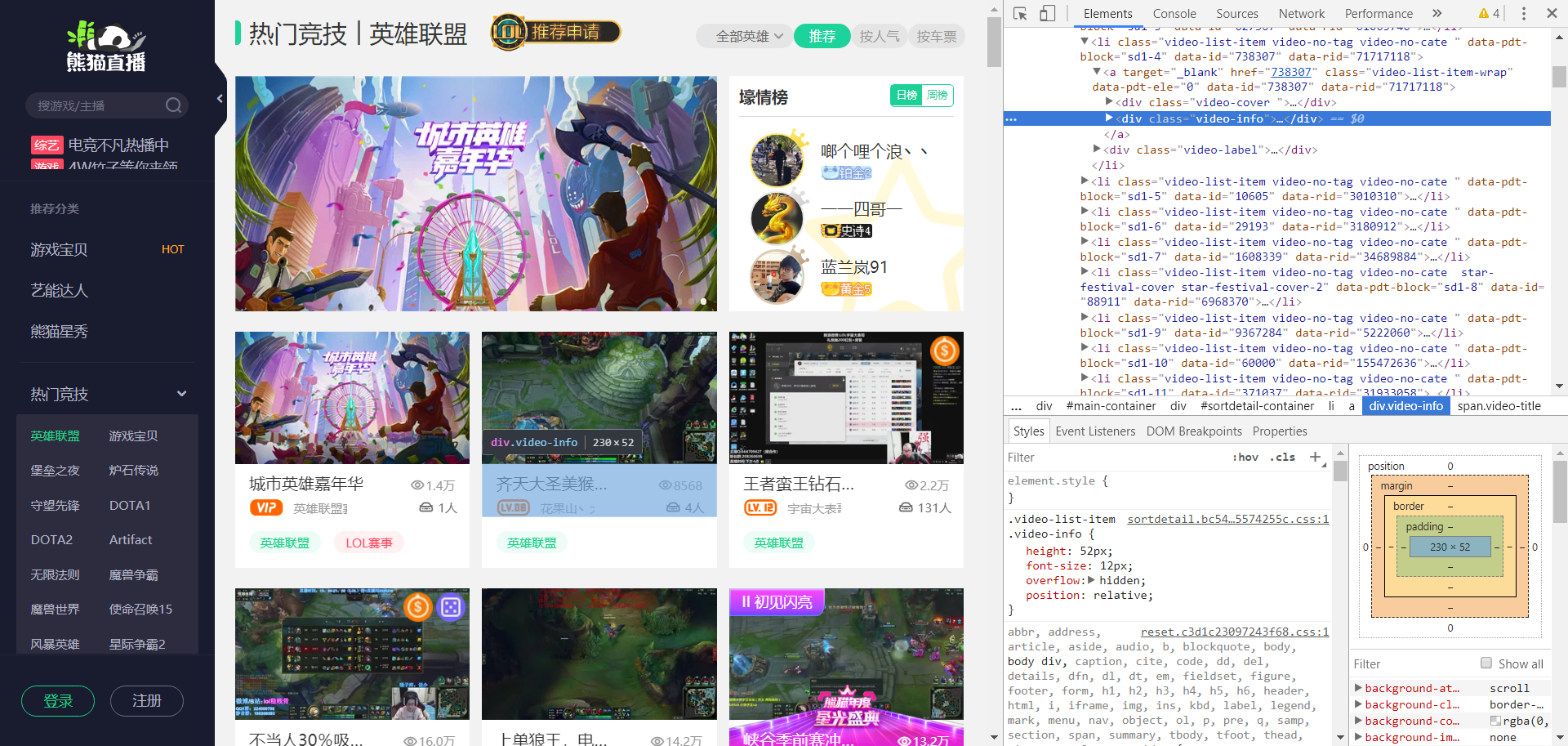
所以我们可以总结:
主播名字:</i>([\s\S]*?)</span>
实时人气:<i class="ricon ricon-eye"></i>([\s\S]*?)</span>
存储以上两个信息的模块:<div class="video-info">([\s\S]*?)</div>
知道这三句,就已经可以开始爬虫代码编写的工作了:
import re
from urllib import request
class Spider():
url='https://www.panda.tv/cate/lol'
root_pattern='<div class="video-info">([\s\S]*?)</div>'
name_pattern='</i>([\s\S]*?)</span>'
number_pattern='<i class="ricon ricon-eye"></i>([\s\S]*?)</span>'
def __fetch_content(self):
r=request.urlopen(Spider.url) #发出打开url的请求
htmls=r.read() #让获取到的url内容进行可读操作,存储到htmls变量里。
htmls=str(htmls,encoding='utf-8') #将获取到的htmls文本转换编码‘utf-8’,并变成str数据类型。
return htmls
def __analysis(self,htmls):
root_html=re.findall(Spider.root_pattern,htmls) #正则表达式匹配出来root_pattern的内容,存储了所有lol主播的实时信息。
anchors=[]
for html in root_html:
name=re.findall(Spider.name_pattern,html) #把名字匹配出来,注意匹配出来的包含多余空白。
number=re.findall(Spider.number_pattern,html) #把人气匹配出来,从源网页看并没有多余空白。
anchor={'name':name,'number':number} #存储到字典里面,以key:value的形式。
anchors.append(anchor) #将所有含有每个主播实时信息的字典放进去列表。
return anchors
def __refine(self,anchors):
l=lambda anchor:{
'name':anchor['name'][0].strip(), #strip()去掉左右所有空白。
'number':anchor['number'][0] #对数据进行精炼处理,去掉可能会匹配多个结果的可能。
}
return map(l,anchors) #使用匿名函数,简化了代码效率。
def __sort(self,anchors):
anchors=sorted(anchors,key=self.__sort_seed,reverse=True) #对列表内的主播进行排序处理,所以定义一个key排序方式,按人气的高低排序,
reverse=True是倒序处理,让人气从高到低排序。
return anchors
def __sort_seed(self,anchor): #为上面的排序函数进行服务,定义key的排序方式。
r=re.findall('\d*',anchor['number']) #贪婪模式只匹配出来数字。去掉万等其他符号。
number=float(r[0]) #对数据精炼处理,将str类型转换为float类型,方便下面的排序计算。
if '万' in anchor['number']: #有些数据是带着万的,但是在上面被剔除了,需要进一步处理,在数值上乘以一万。
number *=10000
return number #返回的结果作为key的参考,让上面的函数进行排序。
def __show(self,anchors): #处理数据展现的方式
for anchor in anchors:
print(anchor['name']+'-----'+anchor['number'])
def go(self):
htmls=self.__fetch_content() #先找到对应的htmls文本。
anchors=self.__analysis(htmls) #将htmls文本进一步处理。得到一个字典anchors。
anchors=list(self.__refine(anchors)) #将字典anchors进行数据的提炼,去掉空白等多余符号。上个list是确保一直是列表的形式。
anchors=self.__sort(anchors) #将字典anchors内的人气进行排序处理。
self.__show(anchors) #展现出最后的爬虫数据。
spider=Spider()
spider.go()
输出结果我就忽略掉了,避免打广告的嫌疑,感兴趣的同学可以自行运行尝试。