目录
使用HttpClientFactory管理HttpClients
使用各种方法来提高ASP.NET Core WEB API应用程序的生产力。
应用程序生产力
可以执行一些步骤来提高应用程序的生产率:
- 异步设计模式;
- 非规范化数据;
- 全文检索;
- 优化实体框架核心;
- 缓存数据处理结果;
- 提前准备数据。
异步设计模式
异步工作是提高应用程序生产力的第一步。
异步设计模式已经在第1部分中实现了。它需要一些额外的编码,并且通常比同步编码慢一些,因为它需要系统的某些后台活动来提供异步。因此,在没有长I/O 操作的小型应用程序中,异步工作甚至可以降低应用程序性能。
但是在负载很重的应用程序中,异步可以通过更有效地使用资源来提高其生产力和弹性。让我们观察ASP.NET Core中如何处理请求:
每个请求都在从线程池中获取的单个线程中处理。如果同步工作并且发生长 I/O 操作,则线程等待直到操作结束并在操作完成后返回线程池。但在此等待期间,线程被阻止,并且不能被另一个请求使用。因此,对于新请求,如果在线程池中找不到可用线程,则将创建新线程来处理该请求。创建新线程需要花费时间,并且对于每个被阻塞的线程,还有一些被分配给线程的被阻止的内存。在负载很重的应用程序中,大规模线程创建和阻塞内存可能导致资源不足,从而显著的降低应用程序和整个系统的生产率。它甚至可能导致应用程序崩溃。
但是,如果异步工作,就在I/O操作启动后,处理操作的线程返回到线程池并可用于处理另一个请求。
因此,异步设计模式通过更有效地使用资源来提高应用程序可伸缩性,从而使应用程序更快,更具弹性。
数据规范化与SQL查询效率
您可能已经注意到SpeedUpCoreAPIExampleDB数据库结构几乎完全对应于预期的输出结果。这意味着从数据库中获取数据并将其发送给用户不需要任何数据转换,从而提供最快的结果。我们通过对价格表进行非规范化并使用供应商的名称而不是供应商的ID来实现这一目标。
我们目前的数据库结构是:
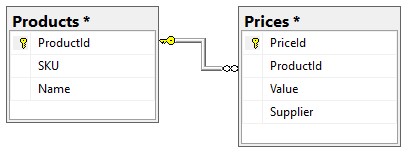
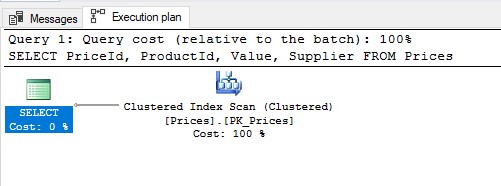
价格表中的所有价格均可通过以下请求获得:
SELECT PriceId, ProductId, Value, Supplier FROM Prices执行计划如下:
完全规范化后,我们的数据库结构如何?
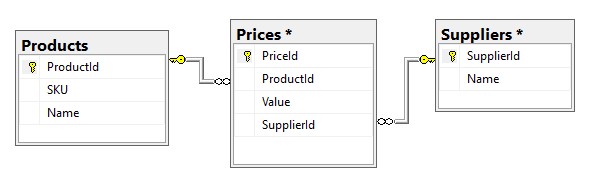
但是在完全规范化的数据库中,价格和供应商表应该在SQL查询中加入,它可能是这样的:
SELECT Prices.PriceId, Prices.ProductId, Prices.Value, Suppliers.Name AS Supplier
FROM Prices INNER JOIN
Suppliers ON Prices.SupplierId = Suppliers.SupplierId有了执行计划:

第一个查询显然要快得多,因为Price表已经针对读取进行了优化。但是,完全标准化的数据模型并不是这样,它可以优化用于存储复杂对象,但不能用于快速读取。因此,使用完全规范化的数据,我们可能会遇到SQL查询效率问题。
请注意,Price表不仅针对读取进行了优化,而且还针对填充数据进行了优化。例如,现在许多价目表都附带Excel文件或.csv文件,可以从Excel、任何MS SQL表或视图和其他来源轻松获取。通常这些文件包含以下列:代码; SKU; 产品; 供应商; 价格; 其中供应商是名称,而不是代码。如果文件中的代码值与Products表中的ProductId相对应,则可以在几秒钟内通过一行T-SQL代码在带有数百万条记录的文件中填充Price表:
EXEC('BULK INSERT Prices FROM ''' + @CsvSourceFileName + ''' WITH ( FORMATFILE = ''' + @FormatFileName + ''')');当然,非规范化具有价格倍增的数据以及在价格和供应商表格中解决数据一致性问题的必要性。但如果目标是生产力,那是值得的。
注意!在第1部分结束时,我们测试了DELETE API。您的数据可能与我们的示例不同。如果是,请从第1部分的脚本重新创建数据库
NCHAR与NVARCHAR
在我们的数据库中,所有字符串字段都具有NCHAR数据类型,这显然不是最佳解决方案。事实是NCHAR是固定长度的数据类型。这意味着,SQL服务器为每个字段保留固定大小的位置(我们已为字段声明),而与字段内容的实际长度无关。例如,Price表中的“Supplier”字段声明为:
[Supplier] NCHAR (50) NOT NULL这就是为什么当我们从价格表中收到价格时,结果如下:
[
{
"PriceId": 7,
"ProductId": 3,
"Value": 160.00,
"Supplier": "Bosch "
},
{
"PriceId": 8,
"ProductId": 3,
"Value": 165.00,
"Supplier": "LG "
},
{
"PriceId": 9,
"ProductId": 3,
"Value": 170.00,
"Supplier": "Garmin "
}
]要删除Suppliers值中的尾随空格,我们必须在PricesService中应用Trim()方法。对于SKU和Name,在ProductsService中是相同的结果。因此,我们在数据库大小和应用程序性能方面都有所损失。
要解决此问题,我们可以将NCHAR字段数据类型更改为NVARCHAR,这是可变长度字符串数据类型。对于NVARCHAR字段,SQL Server仅分配保存字段上下文所需的内存,而不为字段数据添加尾随空格。
我们可以通过T-SQL脚本更改字段数据类型:
USE [SpeedUpCoreAPIExampleDB]
GO
ALTER TABLE [Products]
ALTER COLUMN SKU nvarchar(50) NOT NULL
ALTER TABLE [Products]
ALTER COLUMN [Name] nvarchar(150) NOT NULL
ALTER TABLE [Prices]
ALTER COLUMN Supplier nvarchar(50) NOT NULL但是尾随空格仍然存在,因为SQL服务器没有修改它们以便不丢失数据。所以,我们应该故意修改:
USE [SpeedUpCoreAPIExampleDB]
GO
UPDATE Products SET SKU = RTRIM(SKU), Name = RTRIM(Name)
GO
UPDATE Prices SET Supplier = RTRIM(Supplier)
GO现在我们可以删除ProductsService和PricesService中的所有.Trim()方法,输出结果将没有尾随空格。
使用MSSQL服务器的全文引擎
如果Products表非常的大,则可以通过使用MSSQL服务器的全文搜索引擎的强大功能显着提高SQL查询执行的速度。FTS对MSSQL服务器中的全文搜索只有一个限制——文本只能通过字段的前缀进行搜索。换句话说,如果对SKU列应用全文搜索并尝试查找SKU包含“ab”的记录,则只能找到“abc”,而不能找到“aab”记录。如果此搜索结果适用于应用程序业务逻辑,则可以实现全文搜索。
因此,将在Products表的SKU列中搜索一个sku或其开头部分。为此,在我们的SpeedUpCoreAPIExampleDB数据库中,我们应该创建全文目录:
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE FULLTEXT CATALOG [ProductsFTS] WITH ACCENT_SENSITIVITY = ON
AS DEFAULT
GO然后在ProductsFTS目录中创建FULLTEXT INDEX
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE FULLTEXT INDEX ON [dbo].[Products]
(SKU LANGUAGE 1033)
KEY INDEX PK_Products
ON ProductsFTS
GO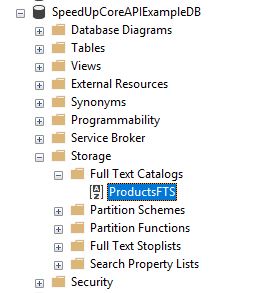

SKU列将包含在全文索引中。索引将自动填充。但是,如果要手动执行此操作,只需右键单击Products表并选择全文索引>启动完全填充。
结果应该是:
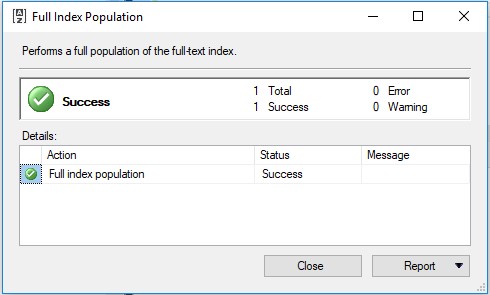
让我们创建一个存储过程来检查全文搜索的工作方式。
存储过程
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE PROCEDURE [dbo].[GetProductsBySKU]
@sku [varchar] (50)
AS
BEGIN
SET NOCOUNT ON;
Select @sku = '"' + @sku + '*"'
-- Insert statements for procedure here
SELECT ProductId, SKU, Name FROM [dbo].Products WHERE CONTAINS(SKU, @sku)
END
GO关于@sku格式的一些解释——让单词前缀的全文搜索,搜索参数应该有结尾*通配符:'“aa *”'。因此,选择@sku ='“'+ @sku +'*”'行只是格式化@sku值。
让我们检查一下程序的工作原理:
USE [SpeedUpCoreAPIExampleDB]
GO
EXEC [dbo].[GetProductsBySKU] 'aa'
GO结果将是:
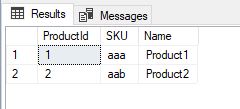
正如预期的那样。
优化存储过程
不要忘记“设置NOCOUNT ON”以防止对处理过的记录进行不必要的计数。
注意,下面的查询:
SELECT ProductId, SKU, [Name] FROM [dbo].Products WHERE CONTAINS(SKU, @sku) 被使用,而不是下面的查询
SELECT * FROM Products WHERE CONTAINS(SKU, @sku)虽然两个查询的结果相同,但第一个查询的结果更快。因为如果使用*通配符而不是列名,SQL Server首先搜索表的所有列名,然后用这些名称替换*通配符。如果明确声明了列名,则省略此额外作业。在没有声明表架构的情况下,在我们的例子中默认架构为[dbo],SQL服务器将在所有模式中搜索一个表。但是,如果明确声明了架构,则SQL Server仅在此架构中更快地搜索表。
预编译和重用存储过程执行计划
使用存储过程的一个重要好处是,在第一次执行之前,存储过程会被编译并创建其执行计划并将其放入缓存中。然后,当下次执行该存储过程时,省略编译动作并从高速缓存中获取就绪执行计划。所有这些使得请求存储过程更快。
让我们确保SQL Server重用存储过程执行计划和预编译代码。为此,首先从所有缓存的执行计划中清空SQL服务器内存——在Microsoft SQL Server Management Studio中创建新的查询:
USE [SpeedUpCoreAPIExampleDB]
GO
--clear cache
DBCC FREEPROCCACHE并通过新查询检查缓存状态:
SELECT cplan.usecounts, cplan.objtype, qtext.text, qplan.query_plan
FROM sys.dm_exec_cached_plans AS cplan
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS qtext
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qplan
ORDER BY cplan.usecounts DESC结果将是:

再次执行存储过程
EXEC [dbo].[GetProductsBySKU] 'aa'然后检查缓存:

我们可以看到缓存了一个过程执行计划。执行该过程并再次检查有关当前缓存计划的信息:

在“usecounts”字段中,我们可以看到该计划被重复使用了多少次。您可以在“usecounts”字段中看到该计划已被重复使用两次,证明执行计划缓存确实适用于我们的存储过程。
使用Entity Framework Core进行全文搜索
全文搜索的最后一个问题是如何将其与Entity Framework Core一起使用。EFC自己生成对数据库的查询,不考虑全文索引。有一些方法可以解决它。最简单的方法是调用已经实现全文搜索的存储过程GetProductsBySKU。
要执行我们的存储过程,我们将使用FromSql方法。此方法在Entity Framework Core中用于执行返回数据集的存储过程和原始SQL查询。
在ProductsRepository.cs中,将FindProductsAsync方法的代码更改为:
public async Task<IEnumerable<Product>> FindProductsAsync(string sku)
{
return await _context.Products.FromSql("[dbo].GetProductsBySKU @sku = {0}", sku).ToListAsync();
}注意,为了加快过程的开始,我们使用其完全限定名[dbo] .GetProductsBySKU,其中包括[dbo]架构。
使用存储过程的一个问题是它的代码不在源代码控制之下。若要解决此问题,您可以使用相同的脚本而不是存储过程调用原始SQL查询。
注意!仅使用参数化原始的SQL查询来利用执行计划重用并防止SQL注入攻击。
但是存储过程仍然更快,因为在调用过程时,我们只将其名称传递给SQL Server,而不是在调用原始SQL查询时传递完整的脚本文本。
让我们检查存储过程和FTS如何在我们的应用程序中工作。启动应用程序并测试/api/products/find/
http://localhost:49858/api/products/find/aa
结果与没有全文搜索的结果相同:
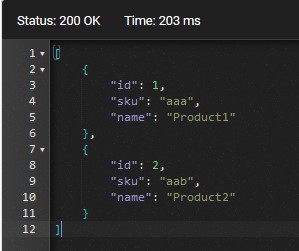
Entity Framework Core性能
由于我们的存储过程返回预期实体类型Product的列表,因此EFC会自动执行跟踪以分析哪些记录已更改为仅更新这些记录。但是在获取产品列表时我们不会更改任何数据。因此,使用AsNoTracking()方法关闭跟踪是合理的,这会禁用EF的额外活动并显着提高其生产率。
没有跟踪的FindProductsAsync方法的最终版本是:
public async Task<IEnumerable<Product>> FindProductsAsync(string sku)
{
return await _context.Products.AsNoTracking().FromSql("[dbo.GetProductsBySKU @sku = {0}", sku).ToListAsync();
}我们还可以在GetAllProductsAsync方法中应用AsNoTracking:
public async Task<IEnumerable<Product>> GetAllProductsAsync()
{
return await _context.Products.AsNoTracking().ToListAsync();
}并在GetProductAsync方法中同样应用AsNoTracking:
public async Task<Product> GetProductAsync(int productId)
{
return await _context.Products.AsNoTracking().Where(p => p.ProductId ==
productId).FirstOrDefaultAsync();
}请注意,使用AsNoTracking() 方法时,EFC不会对已更改的实体执行跟踪,并且如果不附加到_context,您将无法保存GetProductAsync方法找到的实体中的更改。但是EFC仍然执行身份解析,因此我们可以轻松删除GetProductAsync方法找到的产品。这就是为什么我们的DeleteProductAsync方法可以与新版本的GetProductAsync方法一起使用。
价格表上的全文搜索
如果ProductId是NVARCHAR数据类型,我们可以在获取价格时显著提高SQL查询性能,因为我们可以在ProductId列上应用全文搜索。但它的类型是INTEGER,因为它是Products表的ProductId主键的外键,它是具有自动增量标识的整数。
此问题的一种可能解决方案是在Price表中创建一个计算列,该列将包含ProductId字段的NVARCHAR表示,并将此列添加到全文索引。
让我们创建一个名为xProductId的新计算列:
USE [SpeedUpCoreAPIExampleDB]
GO
ALTER TABLE [Prices]
ADD xProductId AS convert(nvarchar(10), ProductId) PERSISTED NOT NULL
GO 我们已将xProductId列标记为PERSISTED,以便将其值物理存储在表中。如果未持久化,则每次访问xProductId列值时都将重新计算它们。这些重新计算也会影响SQL Server的性能。
xProductId字段中的值将是ProductId作为字符串的值:

表的新内容
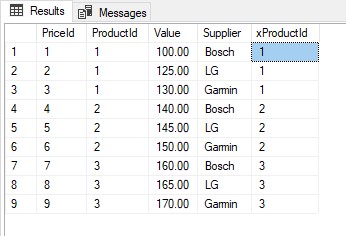
然后在xProductId字段上创建带有FULLTEXT INDEX的新PriceFTS全文目录:
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE FULLTEXT CATALOG [PricesFTS] WITH ACCENT_SENSITIVITY = ON
AS DEFAULT
GO
CREATE FULLTEXT INDEX ON [dbo].[Prices]
(xProductId LANGUAGE 1033)
KEY INDEX PK_Prices
ON PricesFTS
GO最后,创建一个存储过程来测试结果:
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE PROCEDURE [dbo].[GetPricesByProductId]
@productId [int]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @xProductId [NVARCHAR] (10)
Select @xProductId = '"' + CONVERT([nvarchar](10),@productId) + '"'
-- Insert statements for procedure here
SELECT PriceId, ProductId, [Value], Supplier FROM [dbo].Prices WHERE CONTAINS(xProductId, @xProductId)
END
GO在存储过程中,我们声明了@xProductId变量,将@productId转换为NVARCHAR并执行全文搜索。
执行GetPricesByProductId过程:
USE [SpeedUpCoreAPIExampleDB]
GO
DECLARE @return_value int
EXEC @return_value = [dbo].[GetPricesByProductId]
@productId = 1
SELECT 'Return Value' = @return_value
GO但是没有找到任何东西:
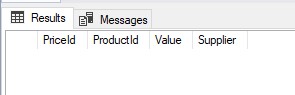
对数值进行全文搜索
在包含数字值的字符串列上进行全文搜索的问题发生在Microsoft SQL Server中,从SQL Server 2012开始,这是因为其新版本的断字符。让我们来看一下全文搜索引擎如何解析xProductId值(“1”,“2”,...)。执行:
SELECT display_term FROM sys.dm_fts_parser (' "1" ', 1033, 0, 0)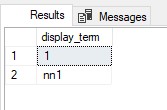
您可以看到,解析器已将值“1”识别为第1行中的字符串和第2行中的数字。此歧义不允许xProductId列值包含在全文索引中。解决此问题的一种可能方法是“将搜索使用的断字符恢复为先前版本”。但是我们已经应用了另一种方法——使用char(例如“x”)启动xProductId列中的每个值,以强制全文解析器将值识别为字符串。让我们确保一下:
SELECT display_term FROM sys.dm_fts_parser (' "x1" ', 1033, 0, 0)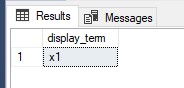
结果不再含糊不清。
更改计算列公式
更改计算列的唯一可能性是删除列,然后使用其他条件重新创建它。
由于为全文搜索启用了ProductId列,我们将无法在首先删除全文索引之前删除该列:
USE [SpeedUpCoreAPIExampleDB]
GO
DROP FULLTEXT INDEX ON [Prices]
GO然后删除列:
USE [SpeedUpCoreAPIExampleDB]
GO
ALTER TABLE [Prices]
DROP COLUMN xProductId
GO然后使用新公式重新创建列:
USE [SpeedUpCoreAPIExampleDB]
GO
ALTER TABLE [Prices]
ADD xProductId AS 'x' + convert(nvarchar(10), ProductId) PERSISTED NOT NULL
GO 检查结果:
USE [SpeedUpCoreAPIExampleDB]
GO
SELECT * FROM [Prices]
GO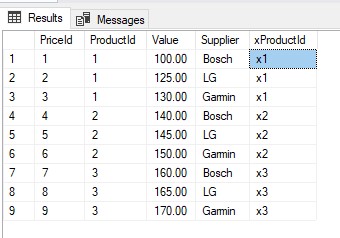
重新创建全文索引:
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE FULLTEXT INDEX ON [dbo].[Prices]
(xProductId LANGUAGE 1033)
KEY INDEX PK_Prices
ON PricesFTS
GO更改我们的GetPricesByProductId存储过程以将“x”添加到搜索模式:
USE [SpeedUpCoreAPIExampleDB]
GO
ALTER PROCEDURE [dbo].[GetPricesByProductId]
@productId [int]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @xProductId [NVARCHAR] (10)
Select @xProductId = '"x' + CONVERT([nvarchar](10),@productId) + '"'
-- Insert statements for procedure here
SELECT PriceId, ProductId, [Value], Supplier FROM [dbo].Prices WHERE CONTAINS(xProductId, @xProductId)
END最后,检查存储过程的工作结果:
USE [SpeedUpCoreAPIExampleDB]
GO
DECLARE @return_value int
EXEC @return_value = [dbo].[GetPricesByProductId]
@productId = 1
SELECT 'Return Value' = @return_value
GO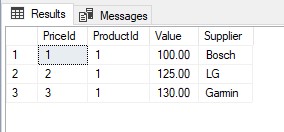
它工作正常。现在让我们更改PriceRepository中的GetPricesAsync方法。换行:
return await _context.Prices.Where(p => p.ProductId == productId).ToListAsync();至:
return await _context.Prices.AsNoTracking().FromSql("[dbo].GetPricesByProductId @productId = {0}", productId).ToListAsync();启动应用程序并检查http://localhost:49858/api/prices/1 结果。结果与没有全文搜索的结果相同:
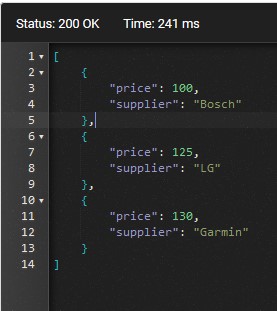
缓存数据处理的结果
再看看上面的图。在我们的例子中,http://localhost:49858/api/prices/1请求的结果可以兑现一段时间。在下一次尝试获取Porduct1的价格时,准备好的价格表将从缓存中获取并发送给用户。如果缓存中仍然没有Id = 1的结果,那么价格将从数据库中获取并放入缓存中。这种方法将减少相对较慢的数据库访问次数,有利于从内存中的高速缓存中快速检索数据。
Redis缓存
对于缓存,将使用Redis缓存服务。Redis缓存的优点是:
- Redis缓存是数据的内存存储,因此它比在磁盘上存储数据的数据库具有更高的性能;
- Redis缓存实现了IDistributedCache接口。这意味着我们可以轻松地将缓存提供程序更改为另一个IDistributedCache,例如MS SQL Server,而无需更改缓存管理逻辑;
- 如果将服务迁移到Azure云,则可以轻松切换到Azure的Redis缓存。
在Windows上安装Redis
可以从https://github.com/MicrosoftArchive/redis/releases下载最新版本的Redis for Windows
目前它是3.2.100
保存并运行Redis-x64-3.2.100.msi
安装非常标准。出于测试目的,您可以默认保留所有选项。安装后,打开任务管理器并检查Redis服务是否正在运行。
此外,请确保该服务自动启动。为此,请打开:Windows>“开始”菜单>“管理工具”>“服务”。

Redis桌面管理器
出于调试目的,使Redis服务器的某些客户端应用程序可以方便地查看缓存值。为此,可以使用Redis Desktop Manager。您可以从https://redisdesktop.com/download下载它
Redis Desktop Manager的安装也非常简单——一切都是默认情况下安装。
打开Redis Desktop Manager,单击Connect to Redis server按钮,然后选择Name:Redis和Address:localhost
然后单击“确定”按钮,您将看到Redis缓存服务器的内容。
Redis NuGet包
将Redis NuGet包添加到我们的应用程序中:
主菜单>工具> NuGet包管理器>管理器NuGet包解决方案
在Browse字段中输入Microsoft.Extensions.Caching.Redis并选择包:

注意!请务必选择正式的Microsoft软件包Microsoft.Extensions.Caching.Redis(但不是Microsoft.Extensions.Caching.Redis.Core)。
在此阶段,您必须安装以下软件包:
在Startup类的ConfigureServices方法中的存储库之前声明AddDistributedRedisCache
//Cache
services.AddDistributedRedisCache(options =>
{
options.InstanceName = Configuration.GetValue<string>("Redis:Name");
options.Configuration = Configuration.GetValue<string>("Redis:Host");
});在配置文件appsettings.json(和appsettings.Development.json)中添加Redis连接设置
"Redis": {
"Name": "Redis",
"Host": "localhost"
}缓存过期控制
对于缓存,可以应用滑动或绝对过期模型。
- 当产品列表非常大,但只有一小部分需求旺盛时,滑动过期对价格有用的。因此,只有这个集合的价格将总会缓存。所有其他价格将自动从缓存中删除,因为它们很少被请求,并且滑动过期模型继续缓存仅在指定时间段内重新请求的项目。这使内存不受不重要数据的影响。这种方法的缺点是,当数据库中的价格发生变化时,我们必须实现一些从缓存中删除项目的机制。
- 绝对过期模型是应用程序中使用的模型。在这种情况下,所有项目将在指定的时间段内平均缓存,然后将自动从缓存中删除。保持高速缓存中实际价格的问题将由其自身解决,尽管可能稍有延迟。
在appsettings.json(和appsettings.Development.json)文件中添加缓存设置部分。
"Caching": {
"PricesExpirationPeriod": 15
}价格将缓存15分钟。
在哪里申请缓存?
由于在应用程序体系结构中,服务对数据存储的方式一无所知,因此缓存的适当位置是负责基础结构层的存储库。对于缓存价格,RedisCache将通过IConfiguration注入到PriceRepository中,IConfiguration提供对缓存设置的访问。
缓存实现
此阶段的PriceRepository类的最后一个版本将是:
using Microsoft.EntityFrameworkCore;
using Microsoft.Extensions.Caching.Distributed;
using Microsoft.Extensions.Configuration;
using Newtonsoft.Json;
using SpeedUpCoreAPIExample.Contexts;
using SpeedUpCoreAPIExample.Interfaces;
using SpeedUpCoreAPIExample.Models;
using System;
using System.Collections.Generic;
using System.Globalization;
using System.Threading.Tasks;
namespace SpeedUpCoreAPIExample.Repositories
{
public class PricesRepository : IPricesRepository
{
private readonly Settings _settings;
private readonly DefaultContext _context;
private readonly IDistributedCache _distributedCache;
public PricesRepository(DefaultContext context, IConfiguration configuration, IDistributedCache distributedCache)
{
_settings = new Settings(configuration);
_context = context;
_distributedCache = distributedCache;
}
public async Task<IEnumerable<Price>> GetPricesAsync(int productId)
{
IEnumerable<Price> prices = null;
string cacheKey = "Prices: " + productId;
var pricesTemp = await _distributedCache.GetStringAsync(cacheKey);
if (pricesTemp != null)
{
//Deserialize
prices = JsonConvert.DeserializeObject<IEnumerable<Price>>(pricesTemp);
}
else
{
prices = await _context.Prices.AsNoTracking().FromSql("[dbo].GetPricesByProductId @productId = {0}", productId).ToListAsync();
//cache prices for PricesExpirationPeriod minutes
DistributedCacheEntryOptions cacheOptions = new DistributedCacheEntryOptions()
.SetAbsoluteExpiration(TimeSpan.FromMinutes(_settings.PricesExpirationPeriod));
await _distributedCache.SetStringAsync(cacheKey, JsonConvert.SerializeObject(prices), cacheOptions);
}
return prices;
}
private class Settings
{
public int PricesExpirationPeriod = 15; //15 minutes by default
public Settings(IConfiguration configuration)
{
int pricesExpirationPeriod;
if (Int32.TryParse(configuration["Caching:PricesExpirationPeriod"], NumberStyles.Any,
NumberFormatInfo.InvariantInfo, out pricesExpirationPeriod))
{
PricesExpirationPeriod = pricesExpirationPeriod;
}
}
}
}
}代码的一些解释:
在DefaultContext类的构造函数中,注入了IConfiguration和IDistributedCache。然后创建了一个新的类设置实例(在类PriceRepository的底部实现)。设置用于在配置的“缓存”部分中得到到“PriceExpirationPeriod”的值。在Settings类中,还检查了PriceExpirationPeriod参数的类型。如果周期不是整数,则使用默认值(15分钟)。
在GetPricessAsync方法中,我们首先尝试从Redis缓存中获取ProductId的价格列表,并将其作为IDistributedCache注入。如果存在值,我们将其反序列化并返回价格列表。如果它不存在,我们从数据库中获取列表并从设置的PriceExpirationPeriod参数缓存它几分钟。
让我们检查一切是如何运作的
在Firefox或Chrome浏览器中,启动Swagger Inspector Extension(先前安装)并调用API http://localhost:49858/api/prices/1
API响应状态:200 OK和Product1的价格列表:
打开Redis桌面管理器,连接到Redis服务器。现在我们可以看到一组RedisPrices和关键价格的缓存值:1

缓存Product1的价格,并在15分钟内再次调用API api/prices/1将从缓存中获取,而不是从数据库中获取。
提前准备数据概念
如果我们有一个庞大的数据库,或者价格只是基本的,并且必须为特定用户另外重新计算,如果我们在用户申请价格并缓存预先计算的价格之前准备价格,响应速度的提高可能会高得多,使用以下请求。
让我们用参数“aa” 分析 api/products/find API结果 http://localhost:49858/api/products/find/aa
我们可以找到两个sku由“aa”组成的位置。在这个阶段,我们不知道用户可以请求哪一个价格。
但是如果参数是“abc”,我们将只获得一个产品作为响应。
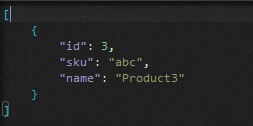
用户最可能的下一步是请求此特定产品的价格。如果我们在此阶段获得产品价格并缓存结果,下一次调用API http://localhost:49858/api/prices/3将从缓存中获取现成价格并节省大量时间和SQL Server活动。
提前准备数据实现
为了实现这个想法,我们在PricesRepository和PricesService中创建了PreparePricessAsync方法。
首先在接口IPricesRepository和IPricesService中声明这些方法。在这两种情况下,该方法都不会返回任何内容。
using SpeedUpCoreAPIExample.Models;
using System.Collections.Generic;
using System.Threading.Tasks;
namespace SpeedUpCoreAPIExample.Repositories
{
public interface IPricesRepository
{
Task<IEnumerable<Price>> GetPricesAsync(int productId);
Task PreparePricesAsync(int productId);
}
}和
using Microsoft.AspNetCore.Mvc;
using System.Threading.Tasks;
namespace SpeedUpCoreAPIExample.Interfaces
{
public interface IPricesService
{
Task<IActionResult> GetPricesAsync(int productId);
Task PreparePricesAsync(int productId);
}
}PriceService的PreparePricessAsync方法只是在try-catch构造中调用PriceRepository的PreparePricessAsync方法。请注意,PreparePricessAsync过程中没有任何异常处理,我们只是完全忽略了可能的错误。这是因为我们不想在这个地方打破程序的流程,因为用户仍然可能永远不会请求此产品的价格,并且错误消息可能是他工作中的不期望的障碍。
public async Task PreparePricesAsync(int productId)
{
IEnumerable<Price> prices = null;
string cacheKey = "Prices: " + productId;
var pricesTemp = await _distributedCache.GetStringAsync(cacheKey);
if (pricesTemp != null)
{
//already cached
return;
}
else
{
prices = await _context.Prices.AsNoTracking().FromSql("[dbo].GetPricesByProductId @productId = {0}", productId).ToListAsync();
//cache prices for PricesExpirationPeriod minutes
DistributedCacheEntryOptions cacheOptions = new DistributedCacheEntryOptions()
.SetAbsoluteExpiration(TimeSpan.FromMinutes(_settings.PricesExpirationPeriod));
await _distributedCache.SetStringAsync(cacheKey, JsonConvert.SerializeObject(prices), cacheOptions);
}
return;
}在PricesService.cs中内容如下
using System;
…
public async Task PreparePricesAsync(int productId)
{
try
{
await _pricesRepository.PreparePricesAsync(productId);
}
catch (Exception ex)
{
}
}让我们检查PreparePricesAsync方法的工作原理。首先将PricisService注入ProductsService中:
private readonly IProductsRepository _productsRepository;
private readonly IPricesService _pricesService;
public ProductsService(IProductsRepository productsRepository, IPricesService pricesService)
{
_productsRepository = productsRepository;
_pricesService = pricesService;
}注意!我们已将PricisService注入到ProductsService中,仅用于测试目的。以这种方式耦合服务并不是一种好的做法,因为如果我们决定实现微服务架构,它将使事情变得困难。在理想的微服务世界中,服务不应该相互依赖。
但是,让我们更进一步,在Product Service类中创建PreparePricessAsync方法。该方法将是Private,因此无需在IProductsRepository接口中声明。
private async Task PreparePricesAsync(int productId)
{
await _pricesService.PreparePricesAsync(productId);
}该方法除了调用PricesService的PreparePricessAsync方法之外什么都不做。
然后,在FindProductsAsync方法中,检查产品列表的搜索结果中是否只有一个项目。如果只有一个,我们将为此单个项目的产品ID调用PricesService 的PreparePricessAsync方法。注意,在我们将产品列表返回给用户之前,我们调用pricesService.PreparePricessAsync方法——原因将在后面解释。
public async Task<IActionResult> FindProductsAsync(string sku)
{
try
{
IEnumerable<Product> products = await _productsRepository.FindProductsAsync(sku);
if (products != null)
{
if (products.Count() == 1)
{
//only one record found - prepare prices beforehand
await PreparePricesAsync(products.FirstOrDefault().ProductId);
};
return new OkObjectResult(products.Select(p => new ProductViewModel()
{
Id = p.ProductId,
Sku = p.Sku,
Name = p.Name
}
));
}
else
{
return new NotFoundResult();
}
}
catch
{
return new ConflictResult();
}
}我们还可以在GetProductAsync方法中添加PreparePricessAsync。
public async Task<IActionResult> GetProductAsync(int productId)
{
try
{
Product product = await _productsRepository.GetProductAsync(productId);
if (product != null)
{
await PreparePricesAsync(productId);
return new OkObjectResult(new ProductViewModel()
{
Id = product.ProductId,
Sku = product.Sku,
Name = product.Name
});
}
else
{
return new NotFoundResult();
}
}
catch
{
return new ConflictResult();
}
}从Redis缓存中删除缓存的值,启动应用程序并调用http://localhost:49858/api/products/find/abc
打开Redis桌面管理器并检查缓存的值。你可以找到“ProductId” :3的价目表
[
{
"PriceId": 7,
"ProductId": 3,
"Value": 160.00,
"Supplier": "Bosch"
},
{
"PriceId": 8,
"ProductId": 3,
"Value": 165.00,
"Supplier": "LG"
},
{
"PriceId": 9,
"ProductId": 3,
"Value": 170.00,
"Supplier": "Garmin"
}
]然后检查/api/products/3 API。从缓存中删除数据并调用http://localhost:49858/api/products/3
检查Redis桌面管理器,您会发现此API还可以正确缓存价格。
但是我们没有获得任何速度上的提升,因为我们同步调用了异步方法GetProductAsync——应用程序工作流等到GetProductAsync准备好价目表。所以,我们的API完成了两个调用的工作。
要解决这个问题,我们应该在一个单独的线程中执行GetProductAsync。在这种情况下,api/products的结果将立即传递给用户。同时,GetProductAsync方法将继续工作,直到它准备价格并缓存结果。
为此,我们必须稍微更改PreparePricesAsync方法的声明_让它返回void。
在ProductsService中:
private async void PreparePricesAsync(int productId)
{
await _pricesService.PreparePricesAsync(productId);
}将System.Threading命名空间添加到ProductsService类中。
using System.Threading现在我们可以为一个线程改变这个方法的调用。
在FindProductsAsync方法中:
…
if (products.Count() == 1)
{
//only one record found - prepare prices beforehand
ThreadPool.QueueUserWorkItem(delegate
{
PreparePricesAsync(products.FirstOrDefault().ProductId);
});
};
…在GetProductAsync方法中:
…
ThreadPool.QueueUserWorkItem(delegate
{
PreparePricesAsync(productId);
});
…一切似乎都好了。从Redis缓存中删除缓存的值,启动应用程序并调用http://localhost:49858/api/products/find/abc
结果状态为Status:200 OK,但缓存仍为空。所以,发生了一些错误,但我们无法看到它,因为我们没有在PriceService中为PreparePricessAsync方法执行错误处理。
让我们在PriceService的PreparePricesAsync方法中的catch语句之后设置一个断点:
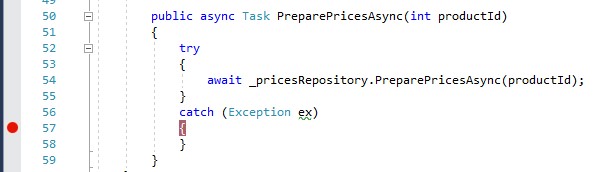
然后再次调用 http://localhost:49858/api/products/find/abc 。
现在我们有一个异常,可以查看详细信息:
System.ObjectDisposedException:'无法访问已释放的对象。此错误的常见原因是处理从依赖项注入解析的上下文,然后尝试在应用程序的其他位置使用相同的上下文实例。如果您在上下文中调用Dispose()或将上下文包装在using语句中,则可能会发生这种情况。如果您正在使用依赖注入,则应该让依赖注入容器负责处理上下文实例。
这意味着,当结果发送给用户时,我们不能再使用通过依赖注入注入的DbContext,因为此时已经释放了DbContext。并且DbContext在我们的依赖注入链中注入的深度并不重要。
让我们检查一下,如果没有依赖注入DbContext,我们是否可以完成这项工作。在PriceRepository.PreparePricessAsync中,我们将动态创建DbContext并在使用构造中使用它。
添加EntityFrameworkCore命名空间
using Microsoft.EntityFrameworkCore像这样获得价格的代码块:
using Microsoft.EntityFrameworkCore
…
public async Task PreparePricessAsync(int productId)
{
…
var optionsBuilder = new DbContextOptionsBuilder<DefaultContext>();
optionsBuilder.UseSqlServer(_settings.DefaultDatabase);
using (var _context = new DefaultContext(optionsBuilder.Options))
{
prices = await _context.Prices.AsNoTracking().FromSql("[dbo].GetPricesByProductId @productId = {0}", productId).ToListAsync();
}
…并在Settings类中添加两行:
public string DefaultDatabase;
…
DefaultDatabase = configuration["ConnectionStrings:DefaultDatabase"];然后启动应用程序并再次尝试http://localhost:49858/api/products/find/abc。
现在没有错误,价格已经在Redis缓存中缓存。如果我们在PricesRepository.PreparePricessAsync方法中设置断点并再次调用API,我们可以看到,程序在结果发送给用户后停止在此断点处。因此,我们实现了我们的目标——预先在后台准备价格,这个过程不会阻碍应用程序的流程。
但这种解决方案并不理想。一些问题是:
- 通过将PricisService注入ProductsService中,我们将服务连接起来,因此如果我们愿意,很难应用微服务架构;
- 我们无法获得DbContext的依赖注入的优势;
- 混合方法,我们使代码不那么统一,因此更加混乱。
对微服务架构的思考
在本文中,我们描述了一个单一应用程序,但是在完成所有生产力改进之后,增加高负载应用程序性能的一种可能方法可能是它的水平扩展。为此,应用程序可能会分为两个微服务,ProductsMicroservice和PriceMicroservice。如果ProductsMicroservice想要提前准备价格,它将调用PriceMicroservice的适当方法。应该通过API访问此方法。
我们将遵循这个想法,但在我们的单一应用程序中实现它。首先,我们将在PriceController中创建API api/prices/prepare,然后通过Http请求从ProductsServive调用此API。这应解决我们对DbContext的依赖注入所带来的所有问题,并将应用程序准备到微服务架构。使用Http请求的另一个好处是,在负载平衡器后面的多租户应用程序中,该请求可能由应用程序的另一个实例处理,因此,我们将获得水平扩展的好处。
首先,让我们将PriceRepository返回到开始测试PreparePricessAsync方法之前的状态:在PriceRepository.PreparePricessAsync方法中,我们删除“using”语句并只留下一行:
public async Task PreparePricessAsync(int productId)
{
…
prices = await _context.Prices.AsNoTracking().FromSql("[dbo].GetPricesByProductId @productId = {0}", productId).ToListAsync();
…并从PricesRepository.Setting类中删除DefaultDatabase变量。
准备为价格创建API
在PriceController中添加方法:
// POST api/prices/prepare/5
[HttpPost("prepare/{id}")]
public async Task<IActionResult> PreparePricessAsync(int id)
{
await _pricesService.PreparePricesAsync(id);
return Ok();
}请注意,调用方法是POST,因为我们不会使用此API获取任何数据。并且API总是返回OK——如果在API执行期间发生某些错误,它将被忽略,因为它在此阶段不重要。
清除Redis缓存,启动我们的应用程序,调用POST http://localhost:49858/api/prices/prepare/3
API工作正常——我们有Status:200 OK并且缓存了Product3的价格表。
因此,我们的目的是从ProductsService.PreparePricessAsync方法的代码中调用此新API。为此,我们必须决定如何获取API的URL。我们将在GetFullyQualifiedApiUrl方法中获取URL。但是,如果我们无法访问当前的Http Context来查找主机和工作协议和端口,我们如何才能在服务类中获取URL?
我们至少有三种可能的用途:
- 将完全限定的API URL放入配置文件中。这是最简单的方法,但如果我们决定将应用程序移动到另一个基础架构,将来会导致一些问题——我们必须关心配置文件中的实际URL;
- 当前的Http Context在Controller级别可用。因此,我们可以确定其中的URL并将其作为参数传递给ProductsService.PreparePricessAsync方法,甚至可以传递Http Context本身。这两个选项都不是很好,因为我们不希望在控制器中实现任何业务逻辑,并且从Service类的角度来看,它变得依赖于Controller,因此服务的测试将更难以建立;
- 使用HttpContextAccessor服务。它提供对应用程序中任何位置的HTTP上下文的访问。它可以通过依赖注入注入。当然,我们选择这种方法作为ASP.NET Core的通用和原生的服务。
为实现这一点,我们在Startup类的ConfigureServices方法中注册HttpContextAccessor:
using Microsoft.AspNetCore.Http;
…
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
services.AddSingleton<IHttpContextAccessor, HttpContextAccessor>();
…服务范围应该是Singleton。
现在我们可以在ProductService中使用HttpContextAccessor。注入HttpContextAccessor而不是PriceServive:
using Microsoft.AspNetCore.Http;
…
public class ProductsService : IProductsService
{
private readonly IProductsRepository _productsRepository;
private readonly IHttpContextAccessor _httpContextAccessor;
private readonly string _apiUrl;
public ProductsService(IProductsRepository productsRepository, IHttpContextAccessor httpContextAccessor)
{
_productsRepository = productsRepository;
_httpContextAccessor = httpContextAccessor;
_apiUrl = GetFullyQualifiedApiUrl("/api/prices/prepare/");
}
…使用以下代码添加方法ProductsService.GetFullyQualifiedApiUrl:
private string GetFullyQualifiedApiUrl(string apiRout)
{
string apiUrl = string.Format("{0}://{1}{2}",
_httpContextAccessor.HttpContext.Request.Scheme,
_httpContextAccessor.HttpContext.Request.Host,
apiRout);
return apiUrl;
}注意,我们在类构造函数中设置_apiUrl变量的值。我们通过删除PricesService的依赖注入并更改ProductService.PreparePricessAsync方法来解耦ProductService和PricesService——调用新API而不是调用PriceServive.PreparePricessAsync方法:
using System.Net.Http;
…
private async void PreparePricesAsync(int productId)
{
using (HttpClient client = new HttpClient())
{
var parameters = new Dictionary<string, string>();
var encodedContent = new FormUrlEncodedContent(parameters);
try
{
var result = await client.PostAsync(_apiUrl + productId, encodedContent).ConfigureAwait(false);
}
catch
{
}
}
}在这个方法中,我们在try-catch中调用API而不进行错误处理。
清除Redis缓存,启动我们的应用程序,调用http://localhost:49858/api/products/find/abc或http://localhost:49858/api/products/3
API工作正常——我们有状态:200 OK和缓存的Product3的价格表。
HttpClients问题
在“Using结构中使用HttpClient并不是最好的解决方案,我们只是将其用作概念验证。有两点我们可以失去生产力:
- 每个HttpClient都有自己的连接池,用于存储和重用连接。但是如果为每个请求创建一个新的HttpClient,新的HttpClient就无法重用以前创建的HttpClients的连接池。因此,它必须浪费时间建立到同一服务器的新连接;
- 在“Using”结构的末尾释放HttpClient后,其连接不会立即释放。相反,它们在TIME_WAIT状态等待一段时间,阻止分配给它们的端口。在负载很重的应用程序中,很多连接会在短时间内创建,但仍然无法重复使用(默认情况下为4分钟)。资源的低效使用会导致生产力的显着降低,甚至导致“套接字耗尽”问题和应用程序崩溃。
此问题的可能解决方案之一是每个服务有一个HttpClient并将服务添加为Singleton。但我们将应用另一种方法——使用HttpClientFactory以适当的方式管理我们的HttpClients。
使用HttpClientFactory管理HttpClients
HttpClientFactory控制HttpClients处理程序的生命周期,使它们可重用,从而防止应用程序无效地使用资源。
自ASP.NET Core 2.1以来,HttpClientFactory已经可用。要将它添加到我们的应用程序,我们应该安装Microsoft.Extensions.Http NuGet包:

通过应用AddHttpClient() 方法在应用程序的Startup.cs文件中注册默认的HttpClientFactory:
…
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
services.AddSingleton<IHttpContextAccessor, HttpContextAccessor>();
services.AddHttpClient();
…在ProductsService类中,通过依赖注入注入HttpClientFactory:
…
private readonly IProductsRepository _productsRepository;
private readonly IHttpContextAccessor _httpContextAccessor;
private readonly IHttpClientFactory _httpClientFactory;
private readonly string _apiUrl;
public ProductsService(IProductsRepository productsRepository, IHttpContextAccessor httpContextAccessor, IHttpClientFactory httpClientFactory)
{
_productsRepository = productsRepository;
_httpContextAccessor = httpContextAccessor;
_httpClientFactory = httpClientFactory;
_apiUrl = GetFullyQualifiedApiUrl("/api/prices/prepare/");
}
…更正PreparePricesAsync方法——删除“Using”构造并通过注入的HttpClientFactory的.CreateClient()方法创建HttpClient:
…
private async void PreparePricesAsync(int productId)
{
var parameters = new Dictionary<string, string>();
var encodedContent = new FormUrlEncodedContent(parameters);
try
{
HttpClient client = _httpClientFactory.CreateClient();
var result = await client.PostAsync(_apiUrl + productId, encodedContent).ConfigureAwait(false);
}
catch
{
}
}
….CreateClient()方法通过从池中取一个并将其传递给新创建的HttpClient来重用HttpClientHandlers。
最后一个阶段通过,我们的应用程序提前准备价格,并以有效和弹性的方式遵循.NET Core范例。
原文地址:https://www.codeproject.com/Articles/1261345/Speed-up-ASP-NET-Core-WEB-API-application-Part-2