版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/baidu_36669549/article/details/85595807
得到的数据是10年的飞机月流量,大致的变化趋势是这样的
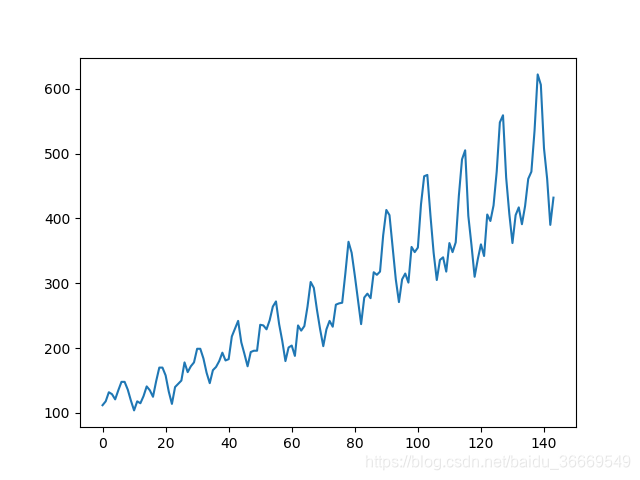
简单的将前几年的数据作为训练集后几年的数据作为测试集
将数据归一化到0~1之间,70%作为训练集,其余作为测试集
训练过程
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.autograd import Variable
data_csv = pd.read_csv('F:/tracker_programe/lstm_test/data.csv',usecols=[1])
# plt.plot(data_csv)
# plt.show()
#数据预处理
data_csv = data_csv.dropna() #去掉na数据
dataset = data_csv.values
dataset = dataset.astype('float32')
max_value = np.max(dataset)
min_value = np.min(dataset)
scalar = max_value-min_value
dataset = list(map(lambda x: x/scalar, dataset)) #将数据标准化到0~1之间
def create_dataset(dataset,look_back=2):
dataX, dataY=[], []
for i in range(len(dataset)-look_back):
a=dataset[i:(i+look_back)]
dataX.append(a)
dataY.append(dataset[i+look_back])
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(dataset)
#划分训练集和测试集,70%作为训练集
train_size = int(len(data_X) * 0.7)
test_size = len(data_X)-train_size
train_X = data_X[:train_size]
train_Y = data_Y[:train_size]
test_X = data_X[train_size:]
test_Y = data_Y[train_size:]
train_X = train_X.reshape(-1,1,2)
train_Y = train_Y.reshape(-1,1,1)
test_X = test_X.reshape(-1,1,2)
train_x = torch.from_numpy(train_X)
train_y = torch.from_numpy(train_Y)
test_x = torch.from_numpy(test_X)
class lstm_reg(nn.Module):
def __init__(self,input_size,hidden_size, output_size=1,num_layers=2):
super(lstm_reg,self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers)
self.reg = nn.Linear(hidden_size,output_size)
def forward(self,x):
x, _ = self.rnn(x)
s,b,h = x.shape
x = x.view(s*b, h)
x = self.reg(x)
x = x.view(s,b,-1)
return x
net = lstm_reg(2,4)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(),lr=1e-2)
for e in range(10000):
var_x = Variable(train_x)
var_y = Variable(train_y)
out = net(var_x)
loss = criterion(out, var_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e+1)%100 == 0:
print('Epoch: {}, Loss:{:.5f}'.format(e+1, loss.data[0]))
torch.save(net.state_dict(), 'net_params.pkl')测试过程
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.autograd import Variable
data_csv = pd.read_csv('F:/tracker_programe/lstm_test/data.csv',usecols=[1])
# plt.plot(data_csv)
# plt.show()
#数据预处理
data_csv = data_csv.dropna() #去掉na数据
dataset = data_csv.values
dataset = dataset.astype('float32')
max_value = np.max(dataset)
min_value = np.min(dataset)
scalar = max_value-min_value
dataset = list(map(lambda x: x/scalar, dataset)) #将数据标准化到0~1之间
def create_dataset(dataset,look_back=2):
dataX, dataY=[], []
for i in range(len(dataset)-look_back):
a=dataset[i:(i+look_back)]
dataX.append(a)
dataY.append(dataset[i+look_back])
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(dataset)
#划分训练集和测试集,70%作为训练集
train_size = int(len(data_X) * 0.7)
test_size = len(data_X)-train_size
train_X = data_X[:train_size]
train_Y = data_Y[:train_size]
test_X = data_X[train_size:]
test_Y = data_Y[train_size:]
train_X = train_X.reshape(-1,1,2)
train_Y = train_Y.reshape(-1,1,1)
test_X = test_X.reshape(-1,1,2)
train_x = torch.from_numpy(train_X)
train_y = torch.from_numpy(train_Y)
test_x = torch.from_numpy(test_X)
class lstm_reg(nn.Module):
def __init__(self,input_size,hidden_size, output_size=1,num_layers=2):
super(lstm_reg,self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers)
self.reg = nn.Linear(hidden_size,output_size)
def forward(self,x):
x, _ = self.rnn(x)
s,b,h = x.shape
x = x.view(s*b, h)
x = self.reg(x)
x = x.view(s,b,-1)
return x
net = lstm_reg(2,4)
net.load_state_dict(torch.load('net_params.pkl'))
data_X = data_X.reshape(-1, 1, 2)
data_X = torch.from_numpy(data_X)
var_data = Variable(data_X)
pred_test = net(var_data) # 测试集的预测结果
pred_test = pred_test.view(-1).data.numpy()
plt.plot(pred_test, 'r', label='prediction')
plt.plot(dataset, 'b', label='real')
plt.legend(loc='best')
plt.show()参考: