实现生产者发送消息,消费者接收消息的demo
在你的项目中加入
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
注意:如果你是使用的 spring initialzar 加入的spring cloud stream模块,如果项目中没有这个依赖,也需要加入上面这个依赖。
根据规划,我们需要两个服务,消息消费者和消息生产者,所以需要构建两个模块。
对于消息消费者模块,在配置文件中写入如下配置:
# 消息队列相关
spring.rabbitmq.username=guest
spring.rabbitmq.virtual-host=/
spring.rabbitmq.password=guest
spring.rabbitmq.host=172.17.0.3
spring.rabbitmq.port=5672
# cloud stream 相关
spring.cloud.stream.bindings.input.destination=teststream
spring.cloud.stream.bindings.input.group=stream_receiver
然后实现消息的接收,代码如下:
@EnableBinding(value = {Sink.class, Source.class})
public class StreamReceiver{
@Value("${spring.profiles.active:0}")
private String active;
Logger logger = LoggerFactory.getLogger(StreamReceiver.class);
@StreamListener(Sink.INPUT)
public void messageReceive(@Payload ProjectDto dto, @Headers Map headers) {
logger.info("实例{}", active);
logger.info("项目名:{},项目id:{}",dto.getInfo(), dto.getPrjId());
}
}
这里 绑定的是具有消息通道的接口,cloud Stream默认提供 Sink/Source/Process 三个不同的接口,其中 Sink提供input接口,Source提供output接口。 表示监听这个通道。至于 是序列化中的内容,现在就这样用着就好了。ProjectDto 是一个数据传输对象,也就是简单的pojo。
public class ProjectDto implements Serializable {
private int prjId ;
private String info;
public String getInfo() {
return info;
}
public int getPrjId() {
return prjId;
}
public void setInfo(String info) {
this.info = info;
}
public void setPrjId(int prjId) {
this.prjId = prjId;
}
}
然后来写生产者,pom.xml跟消费者是相同的,配置文件中加入:
# 消息队列相关
spring.rabbitmq.virtual-host=/
spring.rabbitmq.host=172.17.0.3
spring.rabbitmq.port=5672
spring.rabbitmq.password=guest
spring.rabbitmq.username=guest
# springcloud stream
## rabbitmq exchange
spring.cloud.stream.bindings.output.destination=teststream
## rabbitmq queue 在测试消费组的时候去掉这里的group
spring.cloud.stream.bindings.output.group=stream_receiver
我这里为了方便测试,将消息生产者写成了 web 模式,提供rest接口,所以需要引入依赖包:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/io.springfox/springfox-swagger2 -->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.2.2</version>
</dependency>
然后修改自动生成的主程序:
@EnableAutoConfiguration
@Configuration
@ServletComponentScan
@ComponentScan({"com.xinzu.stream1"})
public class Stream1Application {
public static void main(String[] args) {
SpringApplication.run(Stream1Application.class, args);
}
}
并定义消息发送的服务:
@Service
@EnableBinding(Source.class)
public class SendService {
@Autowired
private Source source;
public void sendMessage(String ans, int pojid){
try {
ProjectDto dto = new ProjectDto();
dto.setInfo(ans);
dto.setPrjId(pojid);
// Consts.setProjectId();
source.output().send(MessageBuilder.withPayload(dto).build());
}catch (Exception e){
e.printStackTrace();
}
}
}
如果你是采用的idea作为ide,可以source会说没有bean,而被标红,但是实际上编译是没有任何问题的,这里你可以降低idea标红的级别,从而增强编程体验。
写一个控制器来调用该服务:
@Api(value = "测试", tags = {"测试"})
@RestController
public class TestStreamSender{
@Autowired
private SendService service;
@RequestMapping(value = "/teststream", method = RequestMethod.POST)
@ResponseBody
public Integer testStream(@RequestParam("val") final String val,
@RequestParam("pojid") final Integer projid){
try {
for (int j=0;j<4;j++){
for (int i=projid;i<projid+50;i++){
String ans = val;
int number = (int) (( Math.random()*1000)%1000);
ans = ans + number;
service.sendMessage(ans,i);
Thread.sleep(500);
}
}
}catch (Exception e){
return 0;
}
return 1;
}
}
最后再给出swagger的配置:
@Configuration
@EnableSwagger2
public class Swagger2 {
@Bean
public Docket createRestApi() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.basePackage("com.xinzu.stream1"))
.paths(PathSelectors.any())
.build();
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("springcloudsender")
.description("springcloudsender api")
.termsOfServiceUrl("http://www.chaojilaji.com/")
.contact("chaojilaji")
.version("1.0")
.build();
}
}
然后分别打开生产者和消费者的一个实例,检验执行结果
开启生产者服务效果:

开启消费者服务效果:

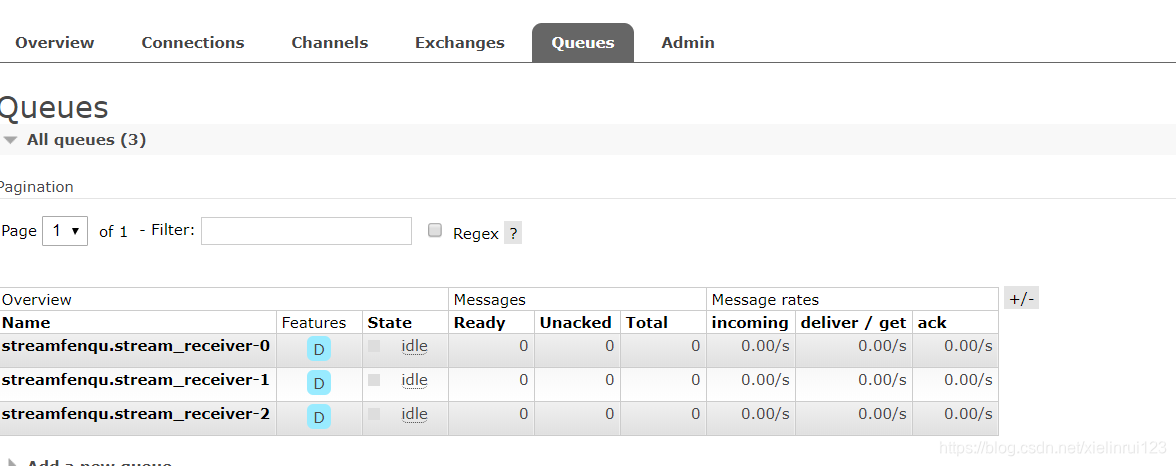
生成的queue:
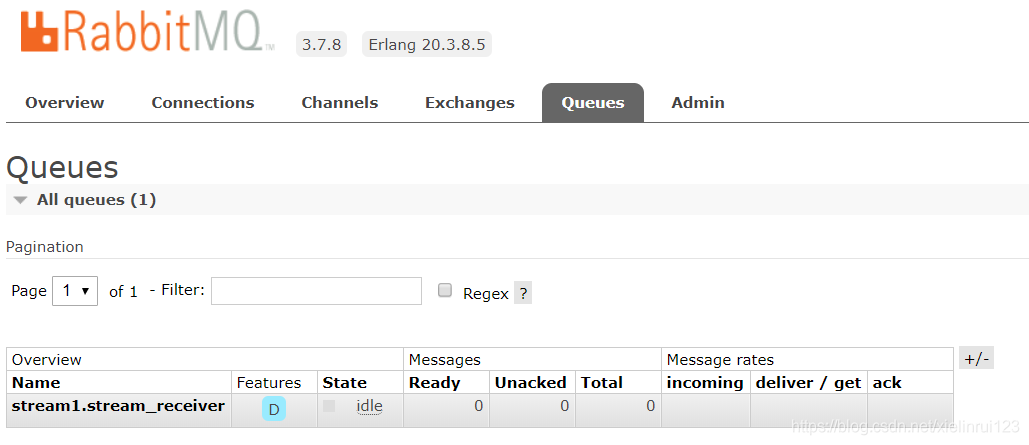
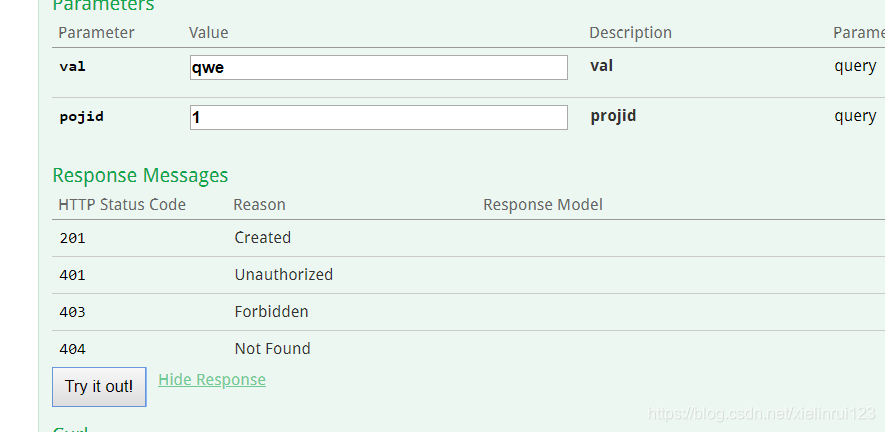
在swagger ui上面进行测试:
结果:
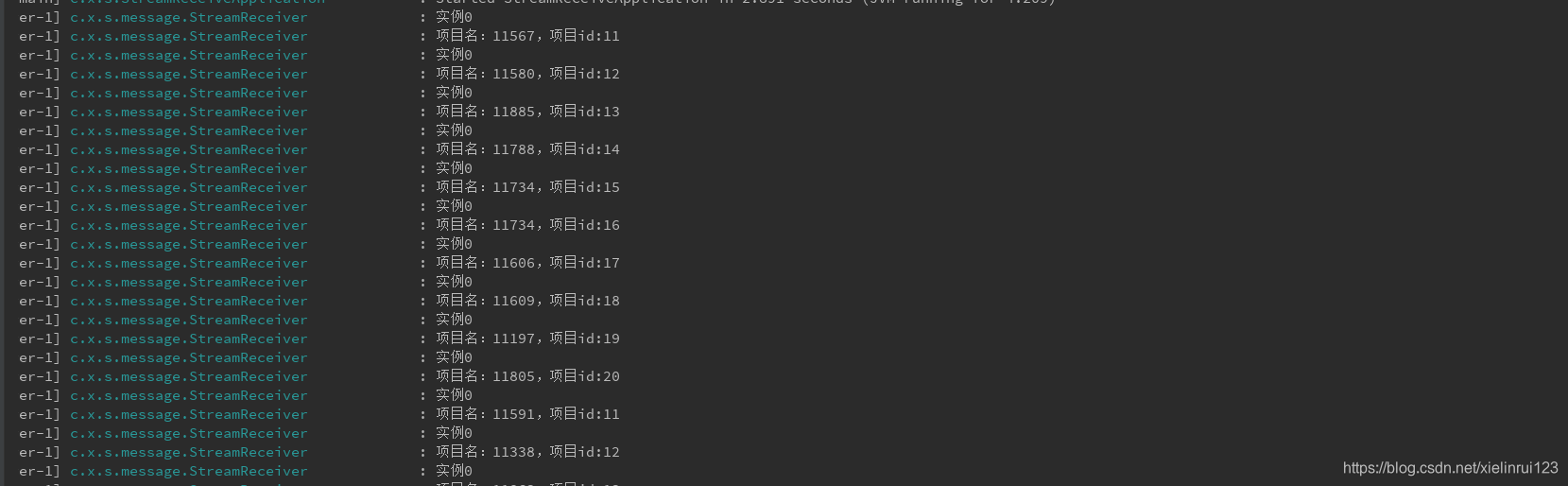
一个简单的消息发送和接收就写好了
对消息序列化和反序列化
其实上面的代码中已经使用到了消息的序列化和反序列化,只不过没有进行仔细说明,首先定义一个pojo并实现序列化
public class ProjectDto implements Serializable {
private int prjId ;
private String info;
public String getInfo() {
return info;
}
public int getPrjId() {
return prjId;
}
public void setInfo(String info) {
this.info = info;
}
public void setPrjId(int prjId) {
this.prjId = prjId;
}
}
然后,在消费者接收消息时,用 来修饰上述pojo就可以了
@StreamListener(Sink.INPUT)
public void messageReceive(@Payload ProjectDto dto, @Headers Map headers) {
logger.info("实例{}", active);
logger.info("项目名:{},项目id:{}",dto.getInfo(), dto.getPrjId());
}
实现消息的序列化和反序列化是消息分区的基础
验证消费组
启动多个消费者实例,并分成两个组。如下
在主配置文件中写入:
spring.profiles.active=1
spring.profiles.active=2
spring.profiles.active=3
spring.profiles.active=4
spring.profiles.active=5
spring.profiles.active=6
然后创建6个不同的配置文件,注意命名不能发生变化:
在前三个个配置文件中均写入以下内容:
# 消息队列相关
spring.rabbitmq.username=guest
spring.rabbitmq.virtual-host=/
spring.rabbitmq.password=guest
spring.rabbitmq.host=172.17.0.3
spring.rabbitmq.port=5672
# cloud stream 相关
spring.cloud.stream.bindings.input.destination=stream
spring.cloud.stream.bindings.input.group=stream_receiver_1
## 消费组
spring.profiles.active=
在后三个配置文件中写入
# 消息队列相关
spring.rabbitmq.username=guest
spring.rabbitmq.virtual-host=/
spring.rabbitmq.password=guest
spring.rabbitmq.host=172.17.0.3
spring.rabbitmq.port=5672
# cloud stream 相关
spring.cloud.stream.bindings.input.destination=stream
spring.cloud.stream.bindings.input.group=stream_receiver_2
##
spring.profiles.active=
然后进入到主配置文件,即
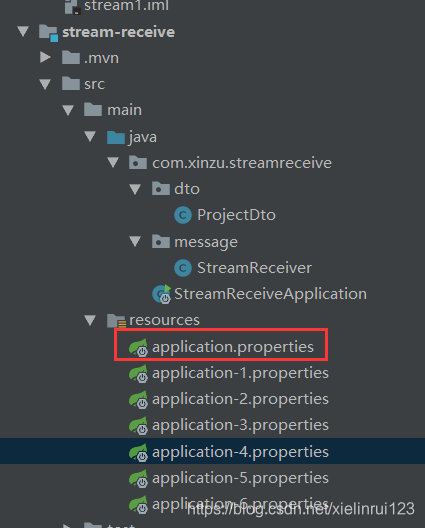
通过一个个的去掉注释,打开6个实例
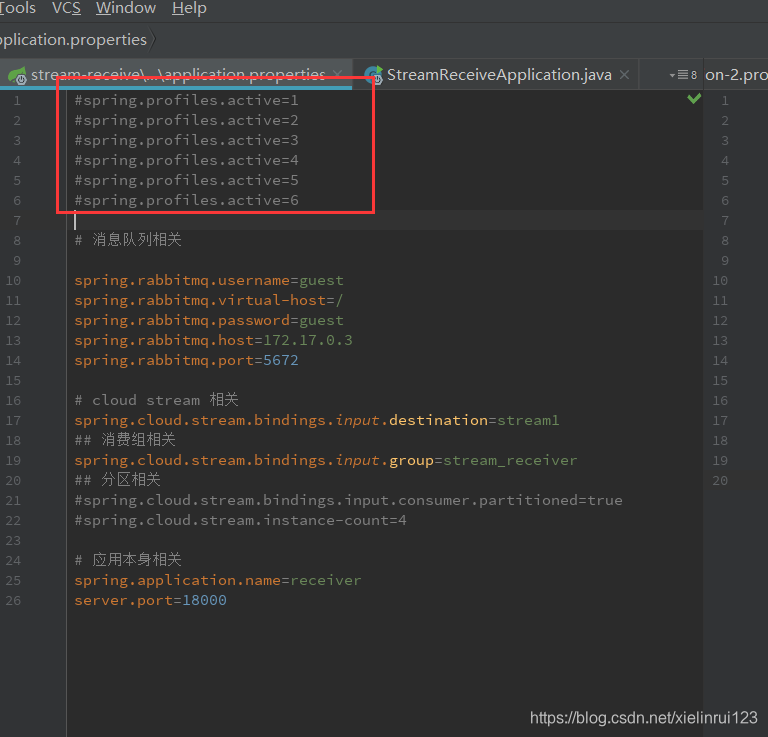
在idea中如果需要打开多个实例,需要在edit服务里面去掉勾选以单例模式运行的选项即可
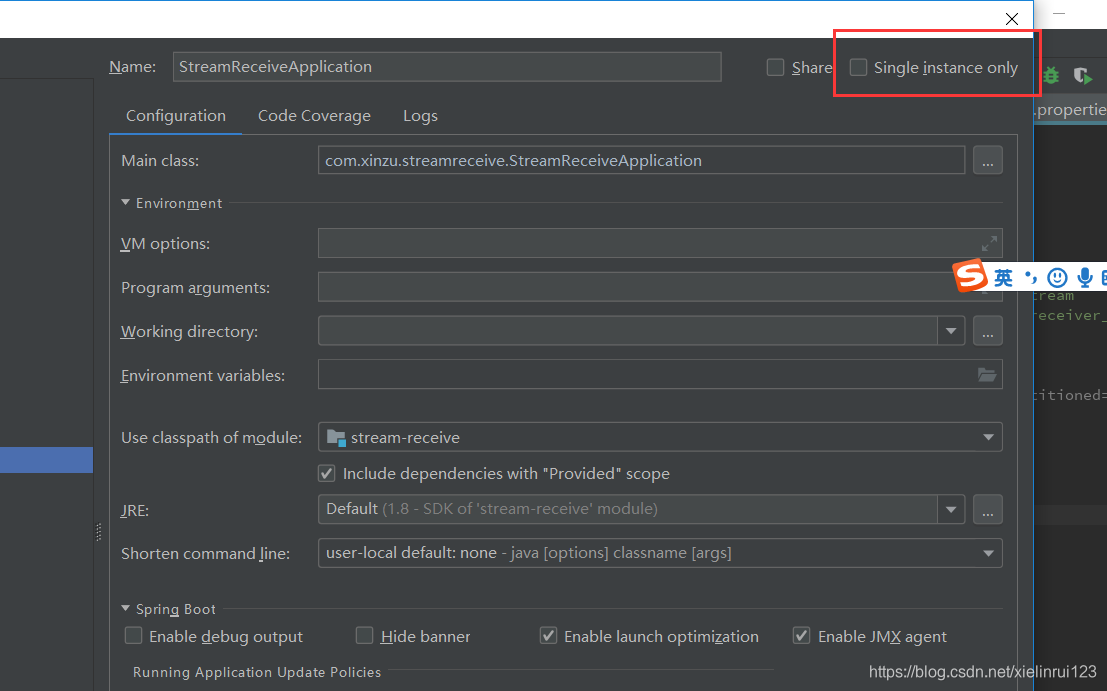
下面是6个消费者开启日志
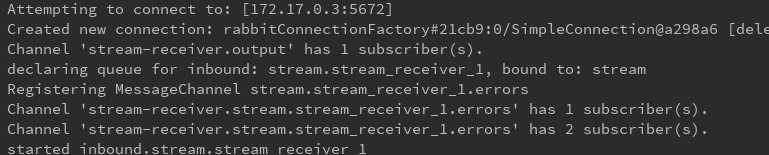
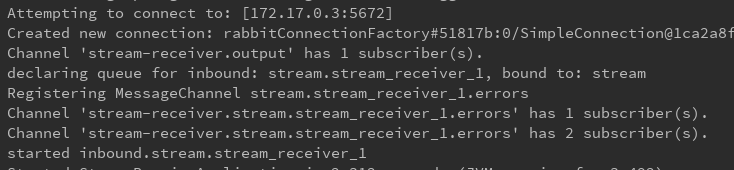
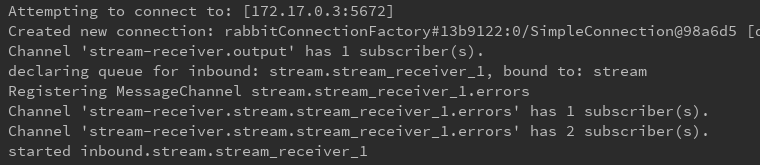
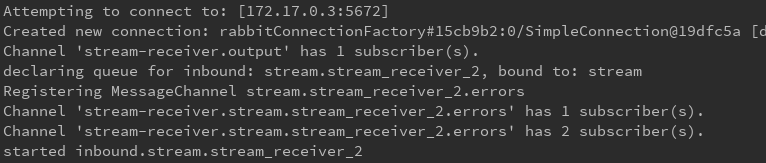
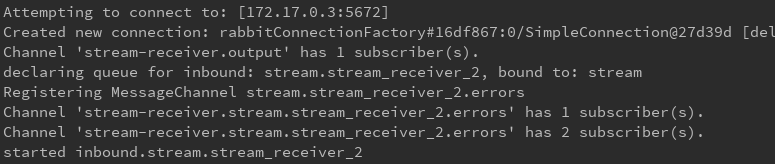
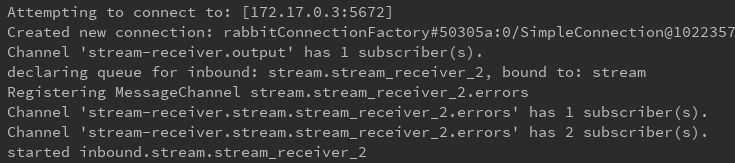
来看看rabbitmq中的效果:
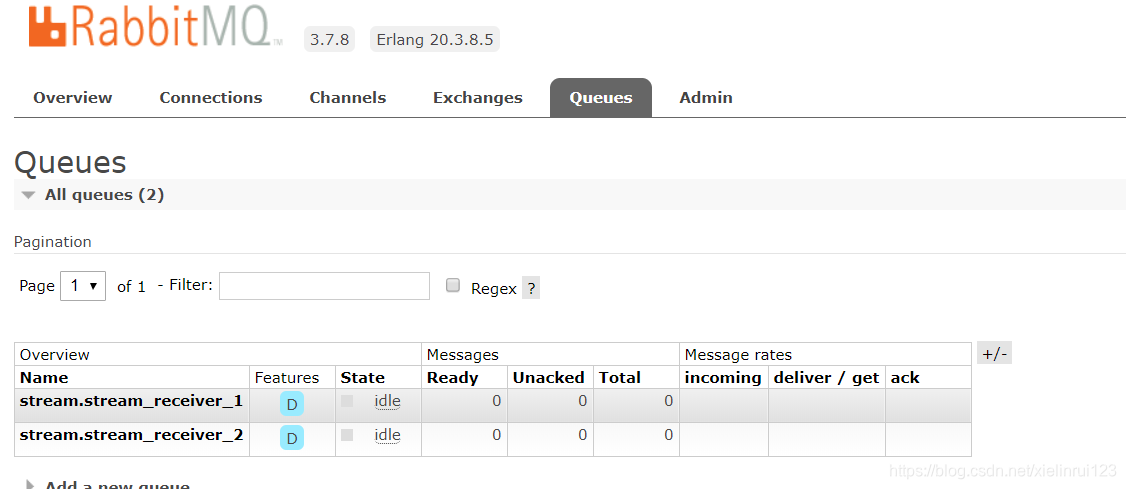
两个不同的 组生成了两个不同的队列,所以我们可以猜到,cloud stream实现消费者组就是通过生成不同的消息队列来实现的。然后由此我们知道,应该修改生产者的组,不把生产者定义到任何组,只要把消息发送到 stream这个交换机就可以了,所以实现消费者组的功能,修改生产者,只需要将它的组设置成不和任何一个消费者组一样就行,这里我直接去掉。
## rabbitmq queue 在测试消费组的时候去掉这里的group
#spring.cloud.stream.bindings.output.group=stream_receiver
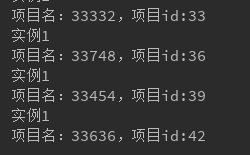
打开生产者,验证消费者组内每个消息都只有一个实例被消费,且全部实例消费的消息与消息总集合相等
stream_receiver_1:
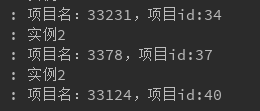
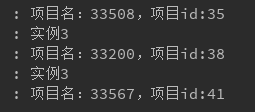
stream_receiver_2:
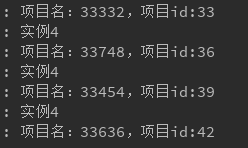
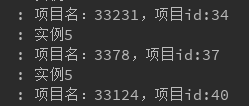
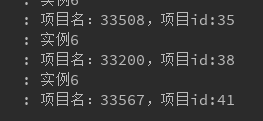
上述验证都十分正确,但是有个奇怪的现象,两个不同的分组,项目分布完全一致,这里估计还需进行仔细研究。
验证分区
分区最重要的功能就是处于一个组里面的项目根据关键字进行连续分配。这种场景是在统计需求或者耗时项目需求中需要实现的场景。
修改消费者配置文件
# 消息队列相关
spring.rabbitmq.username=guest
spring.rabbitmq.virtual-host=/
spring.rabbitmq.password=guest
spring.rabbitmq.host=172.17.0.3
spring.rabbitmq.port=5672
# cloud stream 相关
spring.cloud.stream.bindings.input.destination=streamfenqu
spring.cloud.stream.bindings.input.group=stream_receiver
##
spring.profiles.active=
##
spring.cloud.stream.bindings.input.consumer.partitioned=true
spring.cloud.stream.instance-count=3
# 这个是分区实例的编号,实例编号不能重复
spring.cloud.stream.instance-index=
我这里配置了三个分区实例,所以index应该是 0/1/2
然后修改生产者的配置文件
spring.cloud.stream.bindings.output.destination=streamfenqu
## rabbitmq queue 在测试消费组的时候去掉这里的group
#spring.cloud.stream.bindings.output.group=stream_receiver
## 分区
spring.cloud.stream.bindings.output.producer.partition-key-expression=payload.prjId
spring.cloud.stream.bindings.output.producer.partition-count=3
在生产者这里定义 partition-key-expression 为 payload.prjId。如果你还记得序列化那里,我们用来修饰 ProjectDto的注释是
,那么恭喜你,这里的 payload.prjId 就是指代的 ProjectDto.prjId。不过这里唯一的不便捷性就是针对该生产者发出的消息,所有的分区都会采用该 特征作为分区的基础,需要研究其扩展性。然后分别打开三个消费者实例(和消费者那里一样,一个一个的注释打开)和一个生产者。并进行验证:
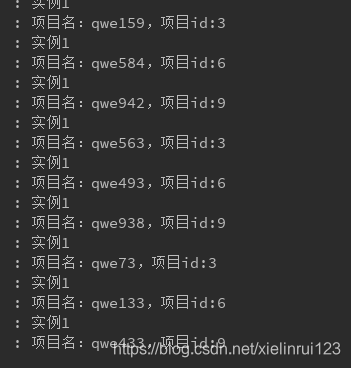
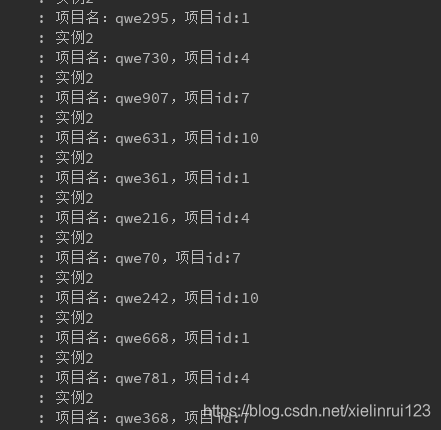
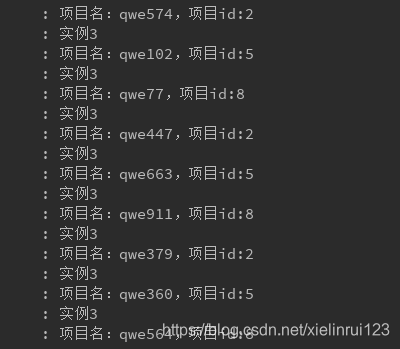
可见,分区验证完成。
进一步工作:
分区与消费者组同时工作是否能完成
分区是否能够设置超时时间,减少引入新增消息变量作为运行一致性的风险
研究组内负载均衡机制,解释上面出现的两组项目分布完全一样的合理性(估计是按顺序放的)