1.缓冲区:
作用:将程序和网络解耦
分为输入缓冲区, 输出缓冲区
每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。
一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,
也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。
这些I/O缓冲区特性可整理如下:
1.I/O缓冲区在每个TCP套接字中单独存在;
2.I/O缓冲区在创建套接字时自动生成;
3.即使关闭套接字也会继续传送输出缓冲区中遗留的数据;
4.关闭套接字将丢失输入缓冲区中的数据。
输入输出缓冲区的默认大小一般都是 8K,可以通过 getsockopt() 函数获取: 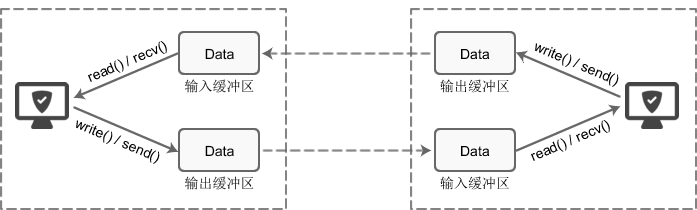
import subprocess
cmd = input('请输入指令>>>')
res = subprocess.Popen(
cmd, #字符串指令:'dir','ipconfig',等等
shell=True, #使用shell,就相当于使用cmd窗口
stderr=subprocess.PIPE, #标准错误输出,凡是输入错误指令,错误指令输出的报错信息就会被它拿到
stdout=subprocess.PIPE, #标准输出,正确指令的输出结果被它拿到
)
print(res.stdout.read().decode('gbk'))
print(res.stderr.read().decode('gbk'))
注意:
如果是windows,那么res.stdout.read()读出的就是GBK编码的,在接收端需要用GBK解码且只能从管道里读一次结果,PIPE称为管道。
2.粘包
两种粘包现象
1 连续的小包可能会被优化算法给组合到一起进行发送
2 第一层次如果发送的数据大小为2000B,接收端一次性接受大小为1024B,
这就导致剩下的内容会被下一次recv接收到,导致混乱

解决方案一.
由于双方不知道对方发送数据的长度,导致接收的时候,可能接收不全,或者多接收另外一次
发送的信息内容,所以在发送真是数据之前,要先发送数据的长度,接收端根据长度来接收后面
的真实数据,但是双方有一个交互确认的过程,但这个方案需要优化,因为还要接受长度消息
方案代码
server端:
import socket
import subprocess
server = socket.socket()
ip_port = ('127.0.0.1',8001)
server.bind(ip_port)
server.listen()
conn,addr = server.accept()
while 1:
from_client_cmd = conn.recv(1024)
print(from_client_cmd.decode('utf-8'))
#接收到客户端发送来的系统指令,我服务端通过subprocess模块到服务端自己的系统里面执行这条指令
sub_obj = subprocess.Popen(
from_client_cmd.decode('utf-8'),
shell=True,
stdout=subprocess.PIPE, #正确结果的存放位置
stderr=subprocess.PIPE #错误结果的存放位置
)
#从管道里面拿出结果,通过subprocess.Popen的实例化对象.stdout.read()方法来获取管道中的结果
std_msg = sub_obj.stdout.read()
#为了解决黏包现象,我们统计了一下消息的长度,先将消息的长度发送给客户端,客户端通过这个长度来接收后面我们要发送的真实数据
std_msg_len = len(std_msg)
# std_bytes_len = bytes(str(len(std_msg)),encoding='utf-8')
#首先将数据长度的数据类型转换为bytes类型
std_bytes_len = str(len(std_msg)).encode('utf-8')
print('指令的执行结果长度>>>>',len(std_msg))
conn.send(std_bytes_len)
status = conn.recv(1024)
if status.decode('utf-8') == 'ok':
conn.send(std_msg)
else:
pass
client端:
import socket
client = socket.socket()
client.connect(('127.0.0.1',8001))
while 1:
cmd = input('请输入指令:')
client.send(cmd.encode('utf-8'))
server_res_len = client.recv(1024).decode('utf-8')
print('来自服务端的消息长度',server_res_len)
client.send(b'ok')
server_cmd_result = client.recv(int(server_res_len))
print(server_cmd_result.decode('gbk'))
解决方案二.(优化过的版本)
使用struct模块处理数据长度,再将发送的数据长度和内容整合在一起发送
struct模块封装的int类型为4个字节,所以可以直接在接收时先定下长度.
打包:struct.pack('i',长度)
解包:struct.unpack('i',字节流)
server服务端:
import socket import subprocess import struct server = socket.socket() ip_port = ('127.0.0.1',8001) server.bind(ip_port) server.listen() conn,addr = server.accept() while 1: from_client_cmd = conn.recv(1024) print(from_client_cmd.decode('utf-8')) #接收到客户端发送来的系统指令,我服务端通过subprocess模块到服务端自己的系统里面执行这条指令 sub_obj = subprocess.Popen( from_client_cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, #正确结果的存放位置 stderr=subprocess.PIPE #错误结果的存放位置 ) #从管道里面拿出结果,通过subprocess.Popen的实例化对象.stdout.read()方法来获取管道中的结果 std_msg = sub_obj.stdout.read() #为了解决黏包现象,我们统计了一下消息的长度,先将消息的长度发送给客户端,客户端通过这个长度来接收后面我们要发送的真实数据 std_msg_len = len(std_msg) print('指令的执行结果长度>>>>',len(std_msg)) msg_lenint_struct = struct.pack('i',std_msg_len) conn.send(msg_lenint_struct+std_msg)
client客户端
import socket
import struct
client = socket.socket()
client.connect(('127.0.0.1',8001))
while 1:
cmd = input('请输入指令:')
#发送指令
client.send(cmd.encode('utf-8'))
#接收数据长度,首先接收4个字节长度的数据,因为这个4个字节是长度
server_res_len = client.recv(4)
msg_len = struct.unpack('i',server_res_len)[0]
print('来自服务端的消息长度',msg_len)
#通过解包出来的长度,来接收后面的真实数据
server_cmd_result = client.recv(msg_len)
print(server_cmd_result.decode('gbk'))
3.打印进度条(两种方法)
1.
import sys
import time
for i in range(50):
sys.stdout.write('>')
sys.stdout.flush()
time.sleep(0.2)
2.
import time
for i in range(20):
print('\r' + i*'*',end='')
time.sleep(0.2)
(总共接收到的大小和总文件大小的比值:
all_size_len表示当前总共接受的多长的数据,是累计的
file_size表示文件的总大小
per_cent = round(all_size_len/file_size,2) #将比值做成两位数的小数
#通过\r来实现同一行打印,每次打印都回到行首打印
print('\r'+ '%s%%'%(str(int(per_cent*100))) + '*'*(int(per_cent*100)),end='')
#由于float类型的数据没法通过%s来进行字符串格式化,所以我在这里通过int来转换了一下,并用str转换了一下,后面再拼接上*,这个*的数量根据现在计算出来的比值来确定,
就能够出来%3***这样的效果。自行使用上面的sys.stdout来实现一下这个直接print的效果。)