自然语言处理,简称:NLP,是指对人们平时日常使用的交流语言进行处理的一项技术。NLP 经过多年的发展,现今可以划分为两部分内容,即:自然语言的理解和自然语言的生成。
本文将以文本分类为目标,介绍自然语言处理相关的基础操作和应用。
(来自https://www.shiyanlou.com/courses/1208)
做一个中文文本分类任务,首先要做的是文本的预处理,对文本进行分词和去停用词操作,来把字符串分割成词与词组合而成的字符串集合并去掉其中的一些非关键词汇(像是:的、地、得等)。再就是对预处理过后的文本进行特征提取。最后将提取到的特征送进分类器进行训练。
术语解释:
-
分词:词是 NLP 中能够独立活动的有意义的语言成分。即使某个中文单字也有活动的意义,但其实这些单字也是词,属于单字成词。
-
词性标注:给每个词语的词性进行标注,比如 跑/动词、美丽的/形容词等等。
-
命名实体识别:从文本中识别出具有特定类别的实体。像是识别文本中的日期,地名等等。
-
词义消歧:多义词判断最合理的词义。
-
句法分析:解析句子中各个成分的依赖关系。
-
指代消解:消除和解释代词「这个,他,你」等的指代问题。
1.Python字符串操作
变量名.count("A"):返回子串A在字符串中出现的次数
.strip()方法可以去除字符串首尾的指定符号。无指定时,默认去除空格符 ' ' 和换行符 '\n'
只去除字符串开头的某个字符串使用 .lstrip() 方法
同样,可以使用.rstrip() 方法来单独去除末尾的字符
字符串拼接:直接用“+”,需要将字符串用特定的符号拼接起来的字符的时候,可以用 .join() 方法来进行拼接。
seq = ['2018', '10', '31'] seq = '-'.join(seq) # 用 '-' 拼接
比较大小:直接用运算符,也可用 operator
.upper() 和 .lower()转换英文字符大小写
为了查找到某段字符串当中某个子串的位置信息,有两种方法。一种是.index ,一种是 .find。 两种方法都可实现这个功能,不同的是 index 如果未找到的话,会报错,而 find 未找到的则会返回 -1 值。
注意第一个位置是0
有的时候,需要把一个字符串按照某个字符切分开处理。比如‘今天天气很好,我们出去玩’,要把两句话以 ','切开成两句话。split()函数可以完成这个操作,函数返回一个由切分好的字符串组成的列表。
翻转字符串:
seq = '12345' seq = seq[::-1]
in 关键字可以用在任何容器对象上,判断一个子对象是否存在于容器当中,并不局限于判断字符串是否存在某子串,还可以用在其他容器对象例如 list,tuple,set 等类型。可配合if 进行后续操作。
.replace(a,b)替换操作,把a替换成b
当遇到需要判断字符串是否以某段字符开头的时候。比如想要判断‘abcdefg’是否以 'a'开头。可以用 .startswish() 方法。同样的方法,我们可以用 .endswith() 来确定字符串是否以某段字符串结尾。
.isdigit() 判断字符串是否由纯数字组成。
2.正则表达式
例子:找出 '2018/01/01', '01/01/2019', '01.2017.01' 这几种不同日期表达中的年份。
规则:连续4个字符 都是 0-9的数字
import re pattern = re.compile(r'[0-9]{4}') times = ('2018/01/01', '01/01/2019', '01.2017.01') for time in times: match = pattern.search(time) if match: print('年份有:', match.group())
输出为:

re 模块的更多使用:
下面我们通过几个例子来体会一下 re 模块对于正则表达式的其他用法。
.findall():
这个方法可以找到符合正则表达式的所有匹配结果。这里我们使用了 \d 规则的正则表达式,这个正则表达式可以替我们识别数字。

同样的方法,我们编写一个 \D 正则表达式,这个可以匹配一个非数字字符。

.match() 方法与 .search() 方法类似,只匹配一次,并且只从字符串的开头开始匹配。同样,match 结果也是存在 group() 当中。

3.中英文分词方法及实现
之前介绍了正则表达式和词的切分,现在介绍中英文分词方法。英文分词比较容易,因为英文词与词之间有空格,但是中文需要按照语义进行切分。
3.1 英文分词
直接按照空格进行分词

按空格指定切分次数:
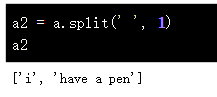
按照关键词进行切分
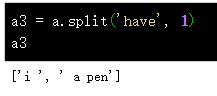
如果需要切分的句子中混入一些其他符号,需要编写函数将其去除,如下:
1 def tokenize_english_text(text): 2 # 首先,我们按照标点来分句 3 # 先建立一个空集用来,用来将分好的词添加到里面作为函数的返回值 4 tokenized_text = [] 5 # 一个text中可能不止一个内容,我们对每个文本单独处理并存放在各自的分词结果中。 6 for data in text: 7 # 建立一个空集来存储每一个文本自己的分词结果,每对data一次操作我们都归零这个集合 8 tokenized_data = [] 9 # 以 '.'分割整个句子,对分割后的每一小快s: 10 for s in data.split('.'): 11 # 将's'以 '?'分割,分割后的每一小快s2: 12 for s1 in s.split('?'): 13 # 同样的道理分割s2, 14 for s2 in s1.split('!'): 15 # 同理 16 for s3 in s2.split(','): 17 # 将s3以空格分割,然后将结果添加到tokenized_data当中 18 tokenized_data.extend( 19 s4 for s4 in s3.split(' ') if s4 != '') 20 # 括号内的部分拆开理解 21 # for s4 in s3.split(' '): 22 # if s4!='': 这一步是去除空字符''。注意与' ' 的区别。 23 # 将每个tokenized_data分别添加到tokenized_text当中 24 tokenized_text.append(tokenized_data) 25 return tokenized_text
注意的是 必须判断是否为空字符,再将其加入列表。运行结果如下:

3.2 中文分词
中文分词这个概念自提出以来,经过多年的发展,主要可以分为三个方法:机械分词方法,统计分词方法,以及两种结合起来的分词。
机械分词方法又叫做基于规则的分词方法,这种分词方法按照一定的规则将待处理的字符串与一个词表词典中的词进行逐一匹配,若在词典中找到某个字符串,则切分,否则不切分。机械分词方法按照匹配规则的方式,又可以分为:正向最大匹配法,逆向最大匹配法和双向匹配法三种。
以下展示的是正向最大匹配法,其计算步骤如下:
- 导入分词词典
dic,待分词文本text,创建空集words。 - 遍历分词词典,找到最长词的长度,
max_len_word。 - 将待分词文本从左向右取
max_len=max_len_word个字符作为待匹配字符串word。 - 将
word与词典dic匹配 - 若匹配失败,则
max_len = max_len - 1,然后 - 重复 3 - 4 步骤
- 匹配成功,将
word添加进words当中。 - 去掉待分词文本前
max_len个字符 - 重置
max_len值为max_len_word - 重复 3 - 8 步骤
- 返回列表
words

以下是一个实例:
1 text = "我在实验楼学习呢" 2 dic = ("我","正在","在","实验楼","学习","呢") 3 words = [] 4 #得到最大词长 5 max_len = 0 6 for key in dic: 7 if len(key)>max_len: 8 max_len = len(key) 9 10 # 判断text的长度是否大于0,如果大于0则进行下面的循环 11 while len(text) > 0: 12 # 初始化想要取的字符串长度 13 # 按照最长词长度初始化 14 word_len = max_len 15 # 对每个字符串可能会有(max_len_word)次循环 16 for i in range(0, max_len): 17 # 令word 等于text的前word_len个字符 18 word = text[0:word_len] 19 # 为了便于观察过程,我们打印一下当前分割结果 20 print('用', word, '进行匹配') 21 # 判断word是否在词典dic当中 22 # 如果不在词典当中 23 if word not in dic: 24 #则以word_len - 1 25 word_len -= 1 26 # 清空word 27 word = [] 28 # 如果word 在词典当中 29 else: 30 # 更新text串起始位置 31 text = text[word_len:] 32 # 为了方便观察过程,我们打印一下当前结果 33 print('{} 匹配成功,添加进words当中'.format(word)) 34 # 把匹配成功的word添加进上面创建好的words当中 35 words.append(word) 36 # 清空word 37 word = [] 38 break 39 40 print(words)
运行结果为

上述方法虽然简单易行,但是非常依赖于原始词典的构成,所以不具有普适性。接下来介绍一个更为成熟的方法——基于统计规则的分词方法。
简单的来说,就是通过分析字与字之间在一起的频率,判断它们是不是一个词。
基于统计的分词,一般情况下有两个步骤:
- 建立统计语言模型。
- 对句子进行单词划分,然后对划分结果进行概率计算,获得概率最大的分词方式。这里就需要用到统计学习算法,如隐马可夫,条件随机场等。
使用的工具:结巴分词
import jieba
cut_all:False表示显示精确模式分词结果,True表示全模式

以下是搜索引擎模式,与全模式匹配结果相同。全模式和搜索引擎模式,jieba 会把全部可能组成的词都打印出来。在一般的任务当中,我们使用默认的精确模式就行了,在模糊匹配时,则需要用到全模式或者搜索引擎模式。
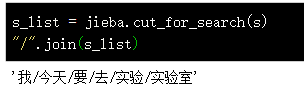
修改词典:
1. 使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
“今天天气不错”,如果直接使用jieba,会分解成为:今天天气和不错两个词,所以需要调整。
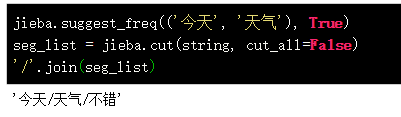
也可以从词典直接删除该词语:

还有一种情况,就是有一些字,他们的组词频率很低,比如“台”和“中”,“台中”出现的概率低于这两个字单独成词的概率,所以此时可以添加词典,强制调高词频。
1 jieba.add_word('台中') 2 seg_list = jieba.cut(string, cut_all=False) 3 '/'.join(seg_list)
以下是一个利用jieba做的简单过滤器,在实际应用中很常见,因为像“的”,“得”,“地”这样的助词需要被过滤掉。
方法是建立一个停用词列表,如果分的词不在列表中,就保留。
1 stopwords = ["的","地","得"] 2 new_list = [] 3 s_list = jieba.cut(s,cut_all=False) 4 for word in s_list: 5 if word not in stopwords: 6 new_list.append(word)
4.特征提取
特征提取是将文本应用于分词前的重要步骤。做文本分类等问题的时,需要从大量语料中提取特征,并将这些文本特征变换为数值特征。一般而言,特征提取有下面的两种经典方法。
4.1 词袋模型
词袋模型是最原始的一类特征集,忽略掉了文本的语法和语序,用一组无序的单词序列来表达一段文字或者一个文档。可以这样理解,把整个文档集的所有出现的词都丢进袋子里面,然后无序的排出来(去掉重复的)。对每一个文档,按照词语出现的次数来表示文档。
4.2 TF-IDF 模型
这种模型主要是用词汇的统计特征来作为特征集。TF-IDF 由两部分组成:TF(Term frequency,词频),IDF(Inverse document frequency,逆文档频率)两部分组成。
4.3 Python实现
在Python中可以使用sklearn来实现上述两种模型。这里要用到 CountVectorizer() 类以及TfidfVectorizer() 类。
下面介绍这两个类:


1 #词袋 2 from sklearn.feature_extraction.text import CountVectorizer 3 #调整参数 4 vectorizer = CountVectorizer(min_df=1, ngram_range=(1, 1)) 5 corpus = ['This is the first document.', 6 'This is the second second document.', 7 'And the third one.', 8 'Is this the first document?'] 9 a = vectorizer.fit_transform(corpus) 10 vectorizer.get_feature_names() 11 a.toarray()
特征名词:
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']

1 #TF-IDF 2 from sklearn.feature_extraction.text import TfidfVectorizer 3 vectorizer = TfidfVectorizer( 4 min_df=1, norm='l2', smooth_idf=True, use_idf=True, ngram_range=(1, 1)) 5 b = vectorizer.fit_transform(corpus) 6 vectorizer.get_feature_names() 7 b.toarray()

5.实战
邮件样本分类器项目,二分类。分析工具:SVM(支持向量机),步骤:预处理、特征提取、分类
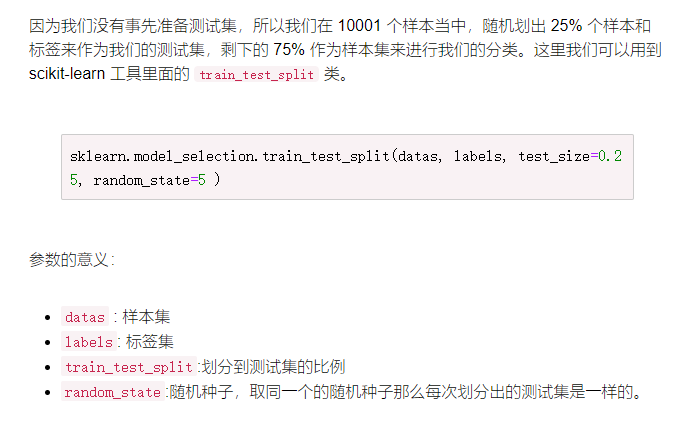
from sklearn.model_selection import train_test_split train_d, test_d, train_l, test_l = train_test_split( datas, labels, test_size=0.25, random_state=5)
实例代码如下:
1 #加载数据集,包括正常邮件、垃圾邮件、停用词 2 from urllib import request 3 request.urlretrieve('http://labfile.oss.aliyuncs.com/courses/1208/ham_data.txt','ham_data.txt') 4 request.urlretrieve('http://labfile.oss.aliyuncs.com/courses/1208/spam_data.txt','spam_data.txt') 5 request.urlretrieve('http://labfile.oss.aliyuncs.com/courses/1208/stop_word.txt','stop_word.txt') 6 7 #数据集处理 8 import numpy as np 9 from sklearn.model_selection import train_test_split 10 path1 = 'ham_data.txt' # 正常邮件存放地址 11 path2 = 'spam_data.txt' # 垃圾邮件地址 12 h = open(path1, encoding='utf-8') 13 h_data = h.readlines() 14 s = open(path2, encoding='utf-8') 15 s_data = s.readlines() 16 #生成标签 17 h_labels = np.ones(len(h_data)).tolist() #正常邮件标签为1 18 s_labels = np.zeros(len(s_data)).tolist() #垃圾邮件标签为0 19 #整合数据集和标签 20 datas = h_data + s_data # 将正常样本和垃圾样本整合到datas当中 21 labels = h_labels + s_labels 22 #分类,随机划出 25% 个样本和标签来作为我们的测试集,剩下的 75% 作为样本集来进行我们的分类。 23 train_d, test_d, train_l, test_l = train_test_split( 24 datas, labels, test_size=0.25, random_state=5) 25 26 import jieba 27 #分词 28 def tokenize_words(corpus): 29 tokenized_words = jieba.cut(corpus) 30 tokenized_words = [token.strip() for token in tokenized_words]#去掉词的空格 31 return tokenized_words 32 33 #去除停用词 34 def remove_stopwords(corpus): # 函数输入为样本集 35 sw = open('stop_word.txt', encoding='utf-8') # stopwords 停词表 36 sw_list = [l.strip() for l in sw] # 去掉文本中的回车符,然后存放到 sw_list 当中 37 # 调用前面定义好的分词函数返回到 tokenized_data 当中 38 tokenized_data = tokenize_words(corpus) 39 # 过滤停用词,对每个在 tokenized_data 中的词 data 进行判断,如果 data 不在 sw_list 则添加到 filtered_data 当中 40 filtered_data = [data for data in tokenized_data if data not in sw_list] 41 # 用''将 filtered_data 串起来赋值给 filtered_datas 42 filtered_datas = ''.join(filtered_data) 43 return filtered_datas # 返回去停用词之后的 datas 44 45 from tqdm import tqdm_notebook #显示进度 46 #预处理数据集 47 def preprocessing_datas(datas): 48 preprocessed_datas = [] 49 # 对 datas 当中的每一个 data 进行去停用词操作,并添加到上面刚刚建立的 preprocessed_datas 当中 50 for data in tqdm_notebook(datas): 51 data = remove_stopwords(data) 52 preprocessed_datas.append(data) 53 return preprocessed_datas # 返回去停用词之后的新的样本集 54 55 pred_train_d = preprocessing_datas(train_d)#预处理样本集 56 pred_test_d = preprocessing_datas(test_d)#预处理测试集 57 ''' 58 据此,得到了分词过后并且去除停用词 59 的样本集 pred_train_d 和 测试集 pred_test_d 60 ''' 61 62 #特征提取,用 TF-IDF 模型 63 from sklearn.feature_extraction.text import TfidfVectorizer 64 from sklearn.linear_model import SGDClassifier 65 from sklearn import metrics 66 #设置 TF-IDF 模型训练器 vectorizer 67 vectorizer = TfidfVectorizer( 68 min_df=1, norm='l2', smooth_idf=True, use_idf=True, ngram_range=(1, 1)) 69 #进行特征词提取,.get_feature_names()得到特征词列表 70 tfidf_train_features = vectorizer.fit_transform(pred_train_d) 71 ''' 72 用训练集训练好特征后的 vectorizer 来提取测试集的特征.。 73 注意这里不能用 vectorizer.fit_transform() 要用 vectorizer.transform(), 74 否则,将会对测试集单独训练 TF-IDF 模型,而不是在训练集的词数量基础上做训练。 75 这样词总量跟训练集不一样多,排序也不一样,将会导致维数不同,最终无法完成测试。 76 ''' 77 tfidf_test_features = vectorizer.transform(pred_test_d) 78 79 #调用 SGDClassifier() 类来训练 SVM 分类器 80 svm = SGDClassifier(loss='hinge') 81 #SGDClassifier 是一个多个分类器的组合,当参数 loss='hinge' 时是一个支持向量机分类器 82 svm.fit(tfidf_train_features, train_l)#训练 83 predictions = svm.predict(tfidf_test_features)#测试 84 85 #用 scikit-learn 库中的 accuracy_score 函数来计算一下分类器的准确率 86 accuracy_score = np.round(metrics.accuracy_score(test_l, predictions), 2) 87 #np.round(X,2) 的作用是 X 四舍五入后保留小数点后2位数字 88 89 print(accuracy_score)#打印训练结果——预测准确率 90 91 #抽样测试 92 print('邮件类型:', test_l[21]) 93 print('预测邮件类型:', predictions[21]) 94 print('文本:', test_d[21])