bytes and bytearray
1 bytes和bytearray的介绍
bytes和bytearray是 python3中引入了两个新类型bytes是不可变的字节序列bytearray是可变的字节数组
内存中的数据都是二进制的0和1,并且我们按照字节的方式逻辑上将这些0和1分成一个一个的字节(字节仍然是二进制的0和1),一个字节占 8 位,当一个字节中的高位是 0, 就按照 ASCII解码; 如果一个字节的高位是1, 就不会按照 ASCII编码表解码。此时如果不指定编码的方式(解码的方式),计算机就不知道如何把这些数字翻译成正确的字符,由于我们的计算机使用的是中文,那么计算机就会默认将两两字节组合起来去解码,但是如果这些数当初不是按照两两字节组合的中字符集编码的,那么解码之后就是乱码。
2 字符串与bytes
- 字符串是字符组成的有序序列,字符可以使用编码来理解
- bytes是字节组成的有序的不可变序列
- bytearray是字节组成的有序的可变序列
3 编码与解码
字符串 --> bytes(二进制) 编码 encode
bytes(二进制) --> 字符串 解码 decode
3.1 我们先来思考一个例子:
num = "1" 和 num = 1 在计算机中是怎样的,我们使用文本方式打开后又是什么样子?
字符串 num = "1" 以文本方式显示(也就是人类可读)

此时的1就是我们人类可见的字符串 1
字符串 num = "1" 以二进制方式显示(也就是计算机可读)

31 就是 ASCII编码表中对应的字符串1对应的 16 进制数字
数字 num = 1 以二进制方式显示(也就是计算机可读)

此时的1就是实际在计算机中存在的 16 进制数字1
数字 num = 1 以文本方式显示(也就是人类可读)

SOH 就是 ASCII编码表中 16 进制数字对应的字符串
通过上面的例子我们可以得出以下结论:
计算机只认得二进制数字,二进制的世界里是一个个字节,文本的世界里是一个个字符。
字符串要存储在计算机里面:
查表去 --> 转换为对应的是二进制数字(也可以理解为16进制数字) --> 存储
要将二计算进中存贮的二进制数字以人类可读方式查看(比如通过文本编辑器):
查表去 --> 转换为二进制数字(也可以理解为16进制数字)对应的字符 --> 显示3.2 encode & decode
字符串按照不同的字符集编码encode返回字节序列bytes
encode(encoding='utf-8', errors='strict') -> bytes
--------------------------------------------------------------------------------------
In [9]: '中国'.encode(encoding='utf-8', errors='strict')
Out[9]: b'\xe4\xb8\xad\xe5\x9b\xbd'字节序列按照不同的字符集解码decode返回字符串
bytes.decode(encoding="utf-8", errors="strict") -> str
bytearray.decode(encoding="utf-8", errors="strict") -> str
--------------------------------------------------------------------------------------
In [12]: b'\xe4\xb8\xad\xe5\x9b\xbd'.decode(encoding="utf-8", errors="strict")
Out[12]: '中国'编码和解码的演示
字节的世界里没有编码,字符串的世界里才有编码
# 编码的过程:我们将字符串“中国”编码为二进制的bytes
In [1]: "中国".encode() # 默认编码使用的是 utf-8 字符集
Out[1]: b'\xe4\xb8\xad\xe5\x9b\xbd' # 返回的结果中前面有一个'b',说明这不是一个简单的字符串,而是一个bytes(字节)
# 解码的过程:我们将二进制的bytes解码为字符串
In [2]: "中国".encode().decode()
Out[2]: '中国'如果编码和解码的时候使用的不是同一个字符集,那么就会转换失败(使用文本剪辑器打开的时候就是乱码)
In [3]: "中国".encode().decode(encoding='gbk')
--------------------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-3-5784dfe3e469> in <module>
----> 1 "中国".encode().decode(encoding='gbk')
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 2: illegal multibyte sequence 我们编码和解码使用相同的字符集,就是成功的
In [4]: "中国".encode(encoding='gbk').decode(encoding='gbk')
Out[4]: '中国'此时我们再来看看使用utf-8和gbk两种字符集对字符串"中国"进行编码后的结果有什么不同
In [6]: "中国".encode(encoding='utf-8')
Out[6]: b'\xe4\xb8\xad\xe5\x9b\xbd' # utf-8字符集三个字节对应一个汉字
In [7]: "中国".encode(encoding='gbk') # gbk 字符集两个字节对应一个汉字
Out[7]: b'\xd6\xd0\xb9\xfa'4 ASCII 码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
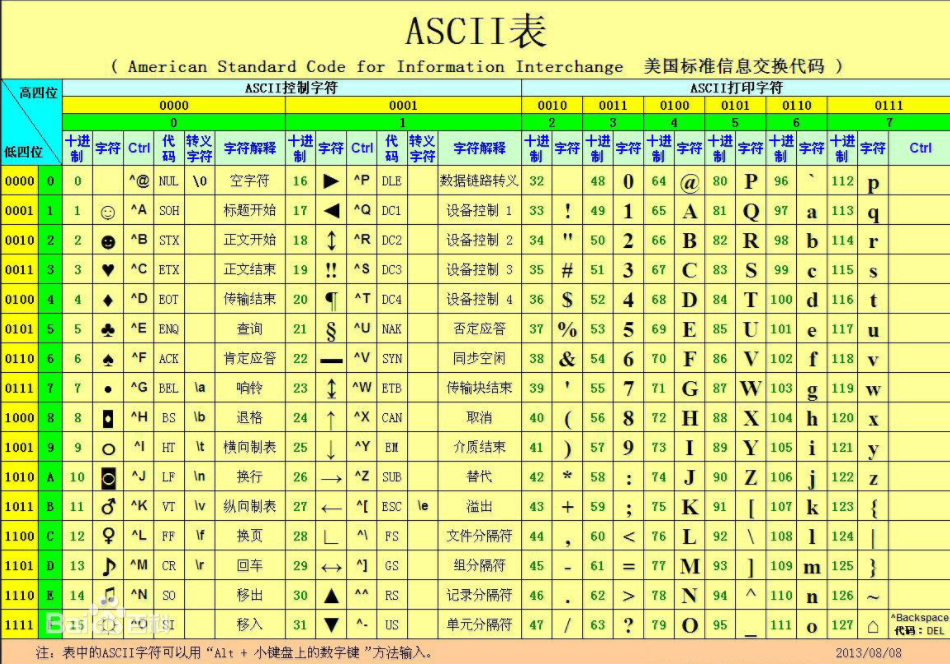
5 bytes
5.1 bytes定义
bytes() # 空bytes
bytes(int) # 指定字节的bytes,被 0 填充
bytes(iterable_of_ints) -> bytes # [0,255] 的int组成的可迭代对象
bytes(string, encoding[, errors]) -> bytes # 等价与 string,encode()
bytes(bytes_or_buffer) -> immutable copy of bytes_or_buffer # 从一个字节序列或者buffer复制出一个新的不可变的bytes对象
使用 b 前缀定义
只允许基于ASCII使用字符形式 b'scm7'
使用16进制表示 b'\x73\x63\x6d\x37'bytes()
In [13]: s = bytes()
In [14]: s
Out[14]: b''
In [17]: s = bytes(0)
In [18]: s
Out[18]: b''bytes(int)
In [15]: s = bytes(5)
In [16]: s
Out[16]: b'\x00\x00\x00\x00\x00' # 由于无法显示ASCII中16进制对应的字符,只能用16进制数字直接显示
# bytes类型是不可变的
In [19]: s = bytes(5)
In [20]: s
Out[20]: b'\x00\x00\x00\x00\x00' # 注意前面有 'b',说明这是一个bytes,而不是普通的字符串
In [21]: s[1] = 10
--------------------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-21-d8b471273ca8> in <module>
----> 1 s[1] = 10
TypeError: 'bytes' object does not support item assignmentbytes类型是可以解码的
In [22]: s.decode()
Out[22]: '\x00\x00\x00\x00\x00' # 注意,前面的 'b' 不见了。说明已经转为字符串类型了(5个字符0)bytes(iterable_of_ints)
返回bytes, [0,255] 的int组成的可迭代对象
In [23]: s = bytes(range(65,68)) # 65,66,67
In [24]: s
Out[24]: b'ABC'
In [25]: s = bytes(range(5)) # 0 1 2 3 4
In [26]: s
Out[26]: b'\x00\x01\x02\x03\x04' # 由于无法显示ASCII中16进制对应的字符,只能用16进制数字直接显示使用 b 前缀定义
In [27]: s = b'abc'
In [28]: s
Out[28]: b'abc'string.encode()
In [30]: x = 'abc'.encode() # 效果和 b'abc' 是相同的
In [31]: x
Out[31]: b'abc'bytes(string,encoding[,errors])
In [32]: bytes('abc','gbk')
Out[32]: b'abc'bytes(bytes_or_buffer)
从一个字节序列或者buffer复制出一个新的不可变的bytes对象
In [33]: s1 = b'xxx'
In [34]: s1
Out[34]: b'xxx'
In [35]: s2 = bytes(s1) # 内存拷贝
In [36]: s2
Out[36]: b'xxx'检验一下对前面的理解
下面的结果是什么?
s3 = b'\x41\x42\x43'
s3.decode()5.2 bytes操作
bytes和str类型类似,都是不可变类型,所以方法很多都一样。只不过bytes的方法,输入是bytes,输出是bytes
replace() 字节的替换
b'abcdef'.replace(b'f',b'k')
b'abc'.find(b'b')
--------------------------------------------------------------------------------------
>>> b'abcdef'.replace(b'f',b'k')
'abcdek'find() 字节的查找
找到返回索引值,否则返回 -1
b'abc'.find(b'b')
--------------------------------------------------------------------------------------
>>> b'abc'.find(b'a')
0
>>> b'abc'.find(b'b')
1
>>> b'abc'.find(b'c')
2
>>> b'abc'.find(b'd')
-1 # 找不到返回 -1bytes.fromhex(string) 返回的是bytes,string是16进制字符串表示法
类方法,从16进制字符串构建bytes
string必须是2个字符的16进制的形式,'6162 6a 6b',空格将被忽略
bytes.fromhex('6162 09 41 42 43')
--------------------------------------------------------------------------------------
In [41]: bytes.fromhex('6162 09 41 42 43')
Out[41]: b'ab\tABC'
# 其实这里我们可以想到,一个大的数字可以转变为多个字节(bytes序列)
# 同时多个字节也可以用来描述一个较大的数字hex() 和 bytes.fromhex(string)是相反的,返回的是字符串
返回16进制表示法表示的字符串,相当于 直接取出来了内存中的数据,并显示
'abc'.encode().hex()
--------------------------------------------------------------------------------------
print('abc'.encode().hex()) -> 616263
In [60]: bytes.fromhex('616163')
Out[60]: b'aac'
In [61]: b'abc'.hex()
Out[61]: '616263'索引
返回该字节对应的数,int类型
b'abcdef'[2]
--------------------------------------------------------------------------------------
In [62]: b'abcdef'[2] # ASCII 表中 c 对应的十进制数就是 99
Out[62]: 99
In [63]: str(b'abcdef'[2])
Out[63]: '99'6 bytearray
6.1 bytearray定义
bytearray() # 空bytearray
bytearray(int) # 指定字节的bytearray,被 0 填充
bytearray(iterable_of_ints) -> bytearray # [0, 255]的int组成的可嗲带对象
bytearray(string, encoding [,errors]) -> bytearray # 近似string.encode(),不过返回可变对象
bytearray(bytes_or_buffer) # 从一个字节序列或这buffer复制出一个新的可变的bytearray对象注意:
b前缀定义的类型是bytes类型,是不可变的
bytearray前缀定义的类型是bytearray类型,是可变的
6.2 bytearray操作
bytearray 的操作方法和byte类型的操作方法相同
replace() 替换
bytearray(b'abcedf').replace(b'f',b'k')
--------------------------------------------------------------------------------------
In [64]: bytearray(b'abcedf').replace(b'f',b'k')
Out[64]: bytearray(b'abcedk')bytearray.fromhex(string)
类方法,string必须是2个字符的16进制的形式,'6162 6a 6b',空格将被忽略
bytearray.fromhex('6162 09 41 4231')
--------------------------------------------------------------------------------------
In [69]: bytearray.fromhex('6162 09 41 4231')
Out[69]: bytearray(b'ab\tAB1')hex()
返回十六进制表示的字符串
bytearray('abc'.encode()).hex()
--------------------------------------------------------------------------------------
print(bytearray('abc'.encode()).hex()) -> 616263索引
返回该字节对应的数,int类型
bytearray(b'abcdef')[2]
--------------------------------------------------------------------------------------
In [70]: bytearray(b'abcdef')[2]
Out[70]: 99 # ASCII 表中 c 对应的十进制数就是 99
append()
b.append(item)
尾部追加一个元素
In [71]: b = bytearray()
In [72]: b.append(97)
In [73]: b
Out[73]: bytearray(b'a')
In [77]: b.append(98)
In [78]: b
Out[78]: bytearray(b'ab')insert()
在指定的索引位置插入元素
b.insert(index, item)
In [79]: b.insert(1,99) # 在索引为1的位置插入 99 (b'c')
In [80]: b
Out[80]: bytearray(b'acb')extend(iterable_of_ints)
b.extend(iterable_of_ints)
将一个可迭代的整数集合追加到当前bytearray
In [100]: b = bytearray()
In [101]: b
Out[101]: bytearray(b'')
In [102]: b.extend(range(65,67))
In [103]: b
Out[103]: bytearray(b'AB')
In [104]: b.extend(range(97,110))
In [105]: b
Out[105]: bytearray(b'ABabcdefghijklm')pop(index=-1)
从指定的缩影上移除元素,默认是从尾部移除
# 默认是移除末尾的元素
In [106]: b
Out[106]: bytearray(b'ABabcdefghijklm')
In [107]: b.pop()
Out[107]: 109
In [108]: b
Out[108]: bytearray(b'ABabcdefghijkl') # 最后的m不见了
# 移除指定索引的元素
In [110]: b
Out[110]: bytearray(b'ABabcdefghijkl')
In [118]: b'ABabcdefghijkl'.hex()
Out[118]: '41426162636465666768696a6b6c'
In [111]: b.pop(-2)
Out[111]: 107
In [112]: b
Out[112]: bytearray(b'ABabcdefghijl') # k(\x6b == 107)没有了
In [113]: b.pop(0)
Out[113]: 65
In [114]: b
Out[114]: bytearray(b'Babcdefghijl') # A(\x61 == 65)没有了remove(velue)
找到第一个value,并移除,找不到直接报异常 ValueErrror
b.remove(66)注意:
上述方法都需要使用int类型,数值在[0,255]
reverse()
反转bytearray,注意此操作是就地修改
In [120]: b
Out[120]: bytearray(b'Babcdefghijl')
In [121]:
In [121]: b.reverse()
In [122]: b
Out[122]: bytearray(b'ljihgfedcbaB')clear()
清空bytearray
In [126]: b
Out[126]: bytearray(b'ljihgfedcbaB')
In [127]: b.clear()
In [128]: b
Out[128]: bytearray(b'')7. int 和 bytes 互转
int.from_bytes(bytes, byteorder)
将一个字节数组表示成整数
In [131]: i = int.from_bytes(b'abc','big') # big 指定是大头字节序,也就是 ---> 这样的方向
In [132]: i
Out[132]: 6382179 # 十进制表示的
In [133]: hex(i)
Out[133]: '0x616263 # 十六进制表示的int.to_bytes(length,byteorder)
byteorder: 字节序
将一个整数表达成一个指定长度的字节数组
i = int.from_bytes(b'abc','big')
print(i,hex(i))
--------------------------------------------------------------------------------------
6382179 0x616263
print(i.to_bytes(3,'big'))
--------------------------------------------------------------------------------------
b'abc'8. 思考题
内存中有一个数字。请问踏实什么类型的?
我不知道,那要看你怎么理解它,你要是把他当作是整形,就是int,
如果当作是字符串,就要去查表解码为字符串,
如果你要是当他是 bytes理解,它就是一个个字节9. 总结
当我们打开一段内存后,看到的是二进制的数字,只有给定了数据类型后我们才知道他们表示的是什么,
离开了数据类型,他们除了是0和1之外什么都不是。
所以,数据一点要有类型。没有类型我们将无法理解。