密度聚类
K-Means算法、K-Means++ 算法和Mean Shift 算法都是基于距离的聚类算法,基于距离的聚类算法的聚类结果都是球状的簇
当数据集中的聚类结果是非球状结构是,基于距离的聚类效果并不好
基于密度的聚类算法能够很好的处理非球状结构的数据,与基于距离的聚类算法不同的是,基于密度的聚类算法可以发现任意形状的簇类。
在基于密度的聚类算法中,通过在数据集中寻找别低密度区域分离的高密度区域,将分离出来的高密度区域作为一个独立的类别。
密度聚类算法假设聚类结构能通过样本分布的紧密程度确定。通常情形下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果。
DBSCAN是一种典型的基于密度的聚类算法。,它基于一组“邻域参数(ε,MinPts)来刻画样本分布的紧密程度。
给定数据集
,定义下面几个概念:
1)ε邻域:对
,其ε邻域包含数据集D中与
的距离不大于ε的样本,即
2) 核心对象:若
的ε邻域至少包含MinPts个样本,即
,则
是一个核心对象
3)边界对象:若
的ε邻域内的样本个数少于MinPts,但是
落在其他核心对象的ε邻域内,则
为边界对象
4)噪音对象:既不是核心对象也不是边界对象的样本点称作噪音对象
5)密度直达:若
位于
的ε邻域中,且
是核心对象,则称
由
密度直达。
6)密度可达:对
,若存在样本序列
,其中
7)密度相连:对
,若存在
使得
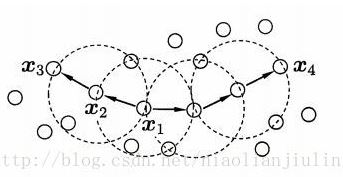
MinPts=3:虚线显示出ε邻域,
是核心对象,
基于这些概念,DBSCAN将簇定义为:由密度可达关系导出的最大的密度相连样本集合。
形式化的说,给定邻域参数(ε,MinPts),簇C时满足下列性质的非空样本集:
1)连接性:
2)最大性:
现在问题来了,如何从数据集D中找到满足以上2个条件的聚类簇呢?
实际上,若
为核心对象,由
密度可达的所有样本组成的集合记作:
则 就是满足连接性与最大性的簇。
于是,DBSCAN算法先任选数据集中的一个核心对象为”种子“(seed),再由此出发确定相应的聚类簇。

算法的1-7行,先根据给定邻域参数(ε,MinPts)找出所有的核心对象;
在第10-24行中,以任一核心对象为出发点,找出由其密度可达的样本生成的聚类簇,知道所有的核心对象都被访问过为止。
层次聚类
层次聚类试图在不同层次对数据集进行划分,从而形成树形的聚类结构。
数据集的划分可采用”自底向上“的聚合策略,也可采用”自顶向下“的分拆策略。
AGNES是一种采用自底向上的聚合策略的层次聚类算法。它先将数据集中的每个样本看作一个初始聚类簇,然后在算法运行每一步中找出距离最近的两个聚类簇进行合并,该过程不断重复,直至达到预设聚类簇个数。
这里的关键是如何计算聚类簇之间的距离
实际上每个簇是一个样本集合,因此只需要采用关于集合的某种距离即可。例如给定聚类簇 与 ,可以通过下面的式子来计算距离:
1)最小距离:
2)最大距离:
3)平均距离:
显然,最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定,而平均距离则有两个簇的所有样本共同决定。
当聚类簇距离分别由
计算时,AGNES算法被相应的称作”单链接“、”全连接“和”均链接“

在第1-9行,算法先对仅含一个样本的初始聚类簇和相应的距离矩阵进行初始化;
11-23行AGNES不断的合并距离最近的聚类簇,并对合并得到的聚类簇的距离矩阵进行更新;
上述过程不断重复,知道达到预设的聚类簇数。