1、由小到大写出以下时间复杂度的序列:

答案: (3)(6)(4)(1)(2)(5)
2、计算运行下列程序段后s的值:
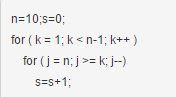
解析:(n+3)*(n-2)/2
答案: 52
3、双端队列可以在队列的两端进行插入和删除操作,既可在队尾进行插入/删除,又可在队头进行插入/删除。现有11个不同的元素顺序输入到双端队列,那么可以得到多少种不同的排列?
解析:第一个元素从左或右入队没有区别,以后每个元素都有从左和从右两种入队方式,即有2^{x-1}种方法。
答案: 1024
4、顺序栈是用一段连续的空间存储内容,本质是顺序表。链式栈则是采用单链表的方式存储。下列关于这两种存储方式的说法正确的是:
A、 顺序栈的压栈和出栈操作只需常数时间。
B、 链式栈的压栈和出栈操作只需常数时间。
C、 顺序栈需要指定一个具体的长度
D、 链式栈需要一个结构性开销
5、按照课程中介绍的机械的递归转换,将下列递归过程改写为非递归过程后,程序中需要设置____个语句标号。

解析:
根据课程介绍的方法,需要设置t+2个语句标号,其中t为递归调用本函数的语句个数。本题中,test函数调用自身2次(t=2),故需要4个语句标号。
答案: 4
6、若字符串s ="DataMining",则其子串的数目为 (字串数目应该重复计算)
解析:空串和自身各1个,长为1的10个,长为2的9个,…,长为9的2个。 2+10+9+8+7+6+5+4+3+2=56
答案: 56
7、在字符{A, C, G, T}组成的DNA序列中,A —— T和C —— G是互补对。
判断一个DNA序列中是否存在互补回文串(例如,ATCATGAT的补串是TAGTACTA,与原串形成互补回文串;即要求整个原串的补串是原串的逆序);
下面DNA序列中存在互补回文串的是:(多选)
A、 CTGATCAG
B、 AATTAATT
C、 GTACGTAC
D、 AGCTAGCT
8、使用KMP算法求出模式p=”aabcaabbaa”的优化后的next数组。注意:只列出数字。比如:0 0 0 0 0 0 0 0 0 0
与答案有偏差,不造哪错了。
答案: -1 -1 1 0 -1 -1 1 3 -1 -1

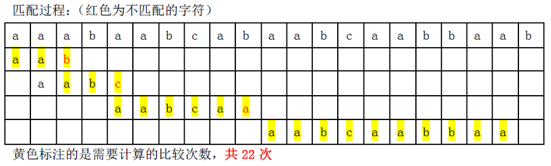
9、利用上题p=”aabcaabbaa”优化后的Next数组,对t=”aaabaabcabaabcaabbaab”进行匹配。有多少次字符比较?(注意:每一次p中的字符与t中的字符的一次比较计做一次)
a a b c a a b b a a
-1 -1 1 0 -1 -1 1 3 -1 -1
移动位数 = 失配字符所在位置(下标从0开始) - 失配字符对应的next 值
= 已匹配的字符数 -模式串"前缀"和"后缀"的最长的共有元素的长度
答案: 22
10、一个有4层结点的完全二叉树。按前序遍历周游给结点从1开始编号,则第21号结点的父结点是多少号?(注释:根的层数为0,第四层的节点是完全铺满的)
解析:画出该完全二叉树即可得到答案。(不难)
答案: 19
11、假设一棵二叉树中,度为2的结点有20个,度为1的结点有10个,度为0的结点有多少个?
解析:边数=总度数=结点数-1,即答案是度为2的结点个数+1
n0 = n2 +1 = 20 + 1 = 21个
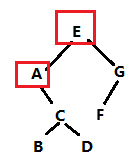
12、某二叉树中序序列为A,B,C,D,E,F,G, 前序序列为E,A,C,B,D,G,F, 则后序序列是?
解析:根据中序序列和前序序列构建出这棵二叉树。
答案: BDCAFGE
13、对于键值序列{38,64,52,26,73,40,48,55,15,12},用筛选法建最小值堆,共交换元素多少次?
解析:73和12进行交换,26和15进行交换,52和40进行交换,64和12进行交换,38和12进行交换,38和15进行交换,38和26进行交换,一共7次。
答案: 7

14、以数据集{4,5,6,7,10,12,18}为结点权值所构造的哈夫曼树,其带权路径长度为?
解析:根据哈夫曼树的构建算法构建该哈夫曼树。
(4+5)*4 + (10+6+7)*3 + (18 + 12)*2 = 165
15、一个深度为h的满k叉树,最多有多少个结点?(独根树深度为0)
解析:k0 + k1 + k2 + ...... + kh = (k^(h+1) - 1)/(k - 1)
16、从空二叉树开始,严格按照二叉搜索树的插入算法(不进行旋转平衡),逐个插入关键码{15, 82, 10, 4, 55, 89, 29, 45, 54, 35, 25}构造出一颗二叉搜索树,对该二叉搜索树按照后序遍历得到的序列为(每两个元素之间用一个空格隔开)
解析:依次插入所有元素之后,得到这棵二叉搜索树,对其进行前序遍历即可得到答案。
答案: 4 10 25 35 54 45 29 55 89 82 15

17、对二叉排序树(即BST,也称“二叉搜索树”)进行什么 --遍历,可以得到该二叉树所有结点构成的排序序列?
A、 前序 B、 后序 C、 按层次 D、 中序

18、2-3树是一种特殊的树,它满足两个条件:
(1)每个内部结点有两个或三个子结点;(2)所有的叶结点到根的路径长度相同;
如果一棵2-3树有10个叶结点,那么它可能有_________个非叶结点。 (多选)
A、 8 B、 7 C、 5
深度一定是3(4层)
倒数第二层若是5个结点,倒数第三层(第二层)有2个结点,加上根结点,一共5+2+1=8个非叶子结点。
倒数第二层若是4个结点,倒数第三层(第二层)有2个结点,一共4+2+1=7个非叶子结点。

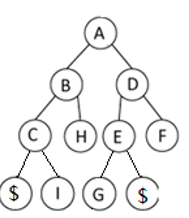
19、对于以下等价类,采用“加权合并规则”(也 称“重量权衡合并规则”),进行并查运算,给出最后父结点索引序列。
1-2 5-1 1-6 0-3 7-4 6-9 5-3 0-8 4–8
注意:当合并大小相同的两棵树的时候,将第二棵树的根指向第一棵树的根;根结点的索引是它本身;
1-2 5-1 1-6 0-3 7-4 6-9 5-3 0-8 4-8
每次节点合并后的父节点索引如下:
[0, 1, 1, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 1, 3, 4, 1, 6, 7, 8, 9]
[0, 1, 1, 3, 4, 1, 1, 7, 8, 9]
[0, 1, 1, 0, 4, 1, 1, 7, 8, 9]
[0, 1, 1, 0, 7, 1, 1, 7, 8, 9]
[0, 1, 1, 0, 7, 1, 1, 7, 8, 1]
[1, 1, 1, 0, 7, 1, 1, 7, 8, 1]
[1, 1, 1, 0, 7, 1, 1, 7, 1, 1]
[1, 1, 1, 0, 7, 1, 1, 1, 1, 1]
答案: 1 1 1 0 7 1 1 1 1 1
20、根据伪满二叉树的前序序列,求ltag-rlink的二叉树前序遍历
比如:给出伪满二叉树的前序序列如下:
A' B' D G' / H C' E' F I /
则可以求出ltag-rlink的二叉树前序遍历为
0A5 0B3 1D-1 1G4 1H-1 0C-1 0E8 1F-1 1I-1
(注:各个结点按照“ltag结点名rlink”的方式给出,结点之间用一个空格分隔)
现给出伪满二叉树的前序序列如下:
A' B' C' / I H D' E' G / F
则所求出ltag-rlink的二叉树前序遍历为
将二叉树转换成森林
根据“若有左子节点,ltag为0,否则为1,若有右兄节点,rlink为对应节点序号,否则为-1”的规则,由此图可以得到ltag-rlink的二叉树前序遍历:0A5 0B4 1C3 1I-1 1H-1 0D8 0E-1 1G-1 1F-1
参考:树的顺序存储结构
答案: 0A5 0B4 1C3 1I-1 1H-1 0D8 0E-1 1G-1 1F-1

21、用相邻矩阵A表示图,判定任意两个顶点Vi和Vj之间是否有长度为m的路径相连,则只要检查_________的第 i 行第 j 列的元素是否为零即可。(不懂)
解析:
22、请使用Kruskal算法求出下图的最小生成树,依次写出每次被选择的合法的合并代价最小的边的编号,用一个空格分隔(如果同时存在多条边满足要求,选择编号最小的)。顶点a到顶点b(a<b)之间的边编号为ab,例如图中权值为1的边编号为45。
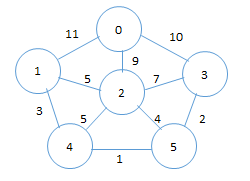
答案: 45 35 14 25 02

23、求图的中心点。设V是有向图G的一个顶点, V的偏心度定义为:如果v是有向图G中具有最小偏心度的顶点,则称顶点v是G的中心点。请从以下代码语句中选择正确的5条,填入空白处。按空白的标号顺序依次列出代码语句的标号,用一个空格分隔。如A F D H C(2018年大题)


答案: A D E M K
24、有一组待排序的记录,其排序码为{18,5,20,30,9,27,6,14,45,22},而采用直接选择排序的比较次数是 45
解析:直接选择排序
9 + 8 + 7 + 6 + 5 + 4 + 3 + 2 + 1 = 45
25、有一严格升序的整型数组A,元素个数为n。现将其前k(0≤k≤n)个元素整体移动到数组后面,得到数组B,使B数组的前n-k个元素恰好是A数组的后n-k个元素,B数组的后k个元素恰好是A数组的前k个元素,且前后两部分的内部升序仍保持不变。请设计一个算法在B数组中查找某个给定元素value。算法设计在函数searchValue中,函数头可采用searchValue(int B[ ], int value)。那么你设计的高效算法的时间复杂度是 O(log n)
26、将序列(p, h, n, d, y, a, f, q, x, m, c, e)中的关键码按字母升序重新排序,初始步长为4的shell排序一趟扫描的结果为
p, h, n, d, y, a, f, q, x, m, c, e
p, h, n, d, x, a, f, q, y, m, c, e
p, h, n, d, x, a, f, q, y, m, c, e
p, a, n, d, x, h, f, q, y, m, c, e
p, a, n, d, x, h, f, q, y, m, c, e
p, a, f, d, x, h, c, q, y, m, n, e
p, a, c, d, x, h, f, q, y, m, n, e
p, a, c, d, x, h, f, e, y, m, n, q
答案: p a c d x h f e y m n q
27、将序列(p, h, n, d, y, a, f, q, x, m, c, e)中的关键码按字母升序重新排序,以第一个元素为轴值的快速排序一趟扫描的结果为
p, h, n, d, y, a, f, q, x, m, c, e
最右边的e填充p的位置
e, h, n, d, y, a, f, q, x, m, c, _
从左边开始看,将e,h,n,d分别与p比较,小于p,不动。将y与p比较,y>p,y填充最右边的元素
e, h, n, d, _ , a, f, q, x, m, c,y
从右边开始看
c与p比较,c<p
e, h, n, d, c , a, f, q, x, m, _,y
e, h, n, d, c , a, f, _, x, m, q,y
e, h, n, d, c , a, f, m, x, _ , q,y
e, h, n, d, c , a, f, m,p, x , q,y
答案: e h n d c a f m p x q y
28、序列(p, h, n, d, y, a, f, q, x, m, c, e)中的关键码按字母升序重新排序,自底向上的二路归并排序第一趟扫描的结果为
p, h n, d y, a f, q x, m c, e
h, p d, n a, y f, q m, x c, e
答案: h p d n a y f q m x c e
29、以下排序算法中,不需要比较待排序记录关键码的算法是:
A、 基数排序 Radix Sorting
B、 冒泡排序 Bubble Sorting
C、 堆排序 Heap Sorting
D、 直接插入排序 Straight Insertion Sorting
解析:
30、下面的排序算法哪些是稳定的。 (多选)
A、 插入排序
B、 归并排序
C、 shell排序
D、 选择排序
E、 桶式排序
F、 基数排序
G、 堆排序
H、 快速排序
I、 冒泡排序
解析:
情绪不稳定,快(快速)些(希尔)选(选择)一堆(堆排序)好友来搞基。
31、对于排序算法特性的叙述正确的是() (多选)
A、冒泡排序不需要访问那些已排好序的记录
B、shell排序过程中,当对确定规模的这些小序列进行插入排序时,要访问序列中的所有记录
C、选择排序需要访问那些已排好序的记录
D、快速排序过程中,递归树上根据深度划分的每个层次都要访问序列中的所有记录
E、归并排序过程中,递归树上每个层次的归并操作不需要访问序列中的所有记录
F、基数排序过程中,按照每个排序码进行的桶式排序不需要访问序列中的所有记录
以下排序算法不需要访问已排好序的记录:冒泡排序,改进的冒泡排序,选择排序。
以下算法在排序过程中算法每次都要访问序列中的所有记录:Shell排序,快速排序,归并排序,基数排序。
(基佬快吸龟)
32、排序算法大都是基于数组实现的,大部分的算法也能用链表来实现,但有些特殊的算法不适合线性链表存储,不适合(使算法复杂度增大)链式存储的算法有()
A、 直接选择排序
B、 插入排序
C、 堆排序
D、 shell排序
解析:
堆的本质是一棵用数组表示的完全二叉树。
33、已知数组A如下: 37 90 79 66 76 80 27 42采用低位优先法的基数排序进行升序排序的第一轮之后的排序结果为?
先按个位排:90 80 42 66 76 37 27 79
答案: 90 80 42 66 76 37 27 79

34、计 划对磁带中的16条数据:{18, 43, 38, 16, 4, 28, 7, 99, 19, 54, 42, 6, 74, 17, 63, 3}进行排序。若排序过程中使用大小为3的堆,则对上述数据采用置换选择算法,所得最长的顺串为
答案: 4 7 16 19 28 42 54 74 99
35、假定有k个关键码互为同义词,即hash函数结果相同,若采用闭散列的线性探测法把这k个关键字存入散列表中,至少要进行()次探测? k*(k+1)/2
解析:1 + 2 + 3 + ...... + k
36、分块检索中,若索引表和各块内均用顺序查找,则有900个元素的线性表分成 30 块最好
设线性表中共有 n 个数据元素,将表分成 b 块,每块有s个记录。
顺序查找
37、一个散列表的散列函数是h(key)=key%19,共有20个槽,用闭散列的线性探查方法。从空表开始,依次进行如下插入删除操作,问这些操作的平均检索长度是:(提示:散列表中不能插入两个相同的关键码)
Add 26
Add 25
Add 24
Add 195
Del 26
Add 176
Add 45
解析:The return values of hashing function is in turn 7,6,5,5,7,5,7, the lengths of retrieval is in turn 1, 1, 1, 4, 1, 5, 3, the sum of them is 16. At the end, the hash table looks like this (start from position 5): 24, 25, 176, 195, 45.the answer is 16/7
ASL = (1+1+1+4+1+5+4)* 1/7
答案:16/7

38、有一个散列表,共有N个槽,采用双散列探查的闭散列方法解决冲突。经过一系列插入操作,当前散列表中有M个元素,负载因子a为0.1,即M/N=a=0.1。假设M,N都非常大,并且双散列探查方法近使得每一次探查的位置,可以近似为均匀分布(即等概率地探查每个槽)。
当前对于某个关键码,近似估算不成功检索的平均检索长度()请保留2位小数
1/(1-0.1) = 1/0.9 = 1.11
答案: 1.11

39、在一棵m阶的B+树中,若在某结点中插入一个新关键码而引起该结点分裂,则此结点中原有的关键码个数为 m
解析: 一个节点最多有m个关键码
40、数组a在C语言中的定义为“int a[25][15][10]”。假设a[0][0][0]的地址为4000,则a[5][9][4]的地址为____。
解释:4000 + 4 * ((5 * 15 + 9) * 10 + 4)
答案: 7376

41、广义表E((a,(a,b),((a,b),c)))。则E的深度为____。
解析:广义表。
E((a,(a,b),((a,b),c)))
答案: 4

42、现有有序空闲块600,1000,1200,500,2000,800,500,以及请求序列500,600,1000,1500,500,500,500,800。使用最优适配,则有几个请求会被满足?
解析:所有请求都被满足
答案: 8

43、AVL树中任何节点的两个子树的高度最大差别为____,AVL树查找时间为O(____),树的结构____(会/不会)改变
A、 1 logN 不会
B、 0 logN 会
所谓AVL树就是其中所有节点的平衡因子不超过1也不小于-1
