1、前言
前一段时间修改了一个项目的功能,项目基于webmagic编写的爬虫。于是开始一些学习。现在整理整理(该项目基本笔者的csdn博客的爬取为例),算是从小白到入门吧。之前使用httpclient和jsoup玩过一点点,但是感觉好麻烦。而webmagic无需配置,直接就可以二次开发,比较简单,容易上手。
2、webmagic的编写思路
主要流程分三步走:
- 设置抓取数据的链接,以及解析数据。这个主要使用的接口为PageProcessor,实现其基本方法即可。
- 处理抓取的数据的结果,持久化还是直接打印输出等等。这个主要使用的接口为Pipeline,获取结果集,即可自定义处理。
- 爬虫的入口及启动
3、项目依赖(基于maven)
<!-- webmagic -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
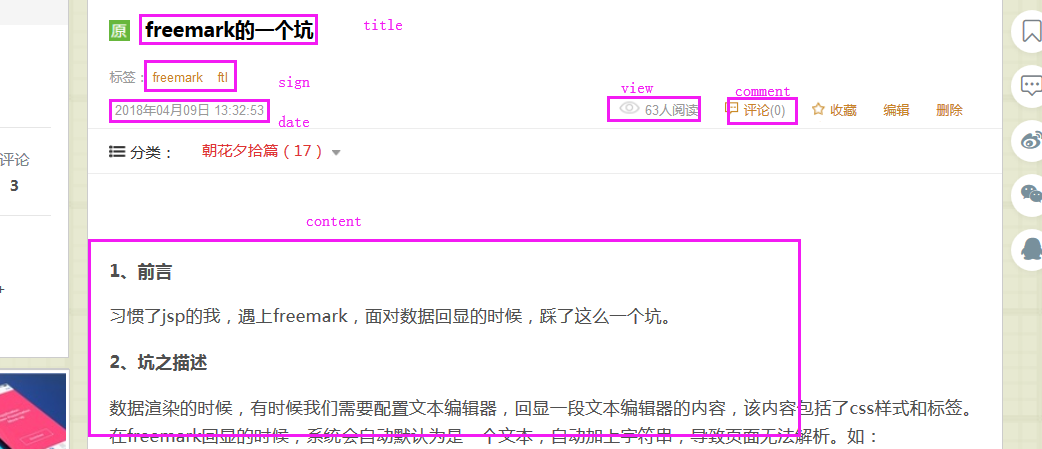
4、抓取目标
5、项目搭建之实现PageProcessor
/**
* <p>@Description: 爬取csdn博客中的数据</p>
* @author simonking
* @date 2018年4月19日 下午2:09:35
*/
public class CsdnBlogPageProcessor implements PageProcessor{
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
public Site getSite() {
return site;
}
// process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
public void process(Page page) {
// 定义如何抽取页面信息,并保存下来
if (!page.getUrl().regex("(https://blog\\.csdn\\.net/static_coder/article/details/\\d+)").match()) {
// 从页面发现后续的url地址来抓取
// 获取当前页面所有的列表的链接
page.addTargetRequests(page.getHtml().xpath("//div[@id='article_list']").links()
.regex("(https://blog\\.csdn\\.net/static_coder/article/details/\\d+)").all());
//抓取分页数据 --https://blog.csdn.net/static_coder/article/list/2
page.addTargetRequests(page.getHtml().xpath("//div[@id='papelist']").links()
.regex("(https://blog\\.csdn\\.net/static_coder/article/list/\\d+)").all());
}else {
page.putField("title", page.getHtml().xpath("//h1/span[@class='link_title']/a/text()"));
page.putField("sign", page.getHtml()
.xpath("//div[@class='article_l']/span[@class='link_categories']/a/text()").all());
page.putField("date", page.getHtml()
.xpath("//div[@class='article_r']/span[@class='link_postdate']/text()"));
page.putField("view", page.getHtml()
.xpath("//div[@class='article_r']/span[@class='link_view']/text()")
.toString().replaceAll("\\D+", ""));
page.putField("comment", page.getHtml()
.xpath("//div[@class='article_r']/span[@class='link_comments']/text()")
.toString().replaceAll("\\D+", ""));
page.putField("content", page.getHtml()
.xpath("//div[@class='details']/div[@id='article_content']/html()"));
page.putField("splitline", "-----------------分割线-------------------");
}
}
}6、项目搭建之实现Pipeline
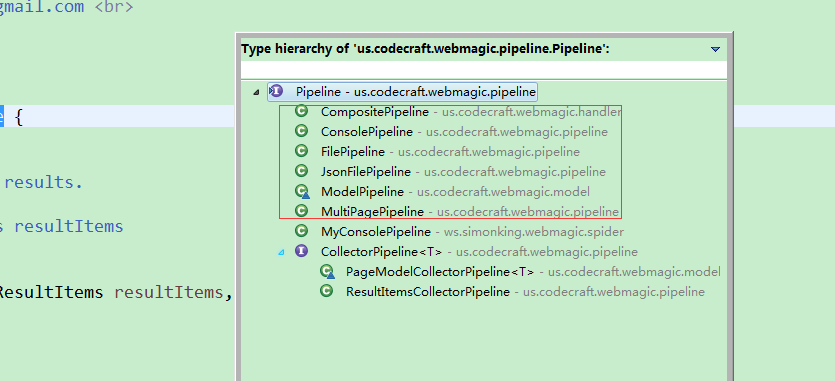
该框架提供了默认的处理结果(ConsolePipeline):就是把获取的数据打印在控制台。
通过Pipeline不同的实现类,可以完成不同结果集处理,该框架默认实现了好几种,如图:
我们来实现自己的结果集:
/**
* <p>@Description: 自定义数据处理</p>
* @author simonking
* @date 2018年4月20日 上午9:16:07
*/
public class MyConsolePipeline implements Pipeline {
public void process(ResultItems resultItems, Task task) {
System.out.println("获取到的请求链接: " + resultItems.getRequest().getUrl());
Map<String, Object> resultMap = resultItems.getAll();
for (Map.Entry<String, Object> entry : resultMap.entrySet()) {
System.out.println(entry.getKey() + ":\t" + entry.getValue());
}
}
}6、项目搭建之实现爬虫启动
public class SpiderTest {
public static void main(String[] args) {
long startTime = new Date().getTime();
System.out.println("------------spider start >>> -----------");
Spider.create(new CsdnBlogPageProcessor())
//https://blog.csdn.net/static_coder"开始抓
.addUrl("https://blog.csdn.net/static_coder")
//开启5个线程抓取
.thread(5)
//爬取数据的处理位置(如果设置默认打印在控制台)
.addPipeline(new MyConsolePipeline())
//启动爬虫
.run();
System.out.println("----------------spider end -------------");
long endTime = new Date().getTime();
System.out.println("耗时:" + (endTime - startTime));
}
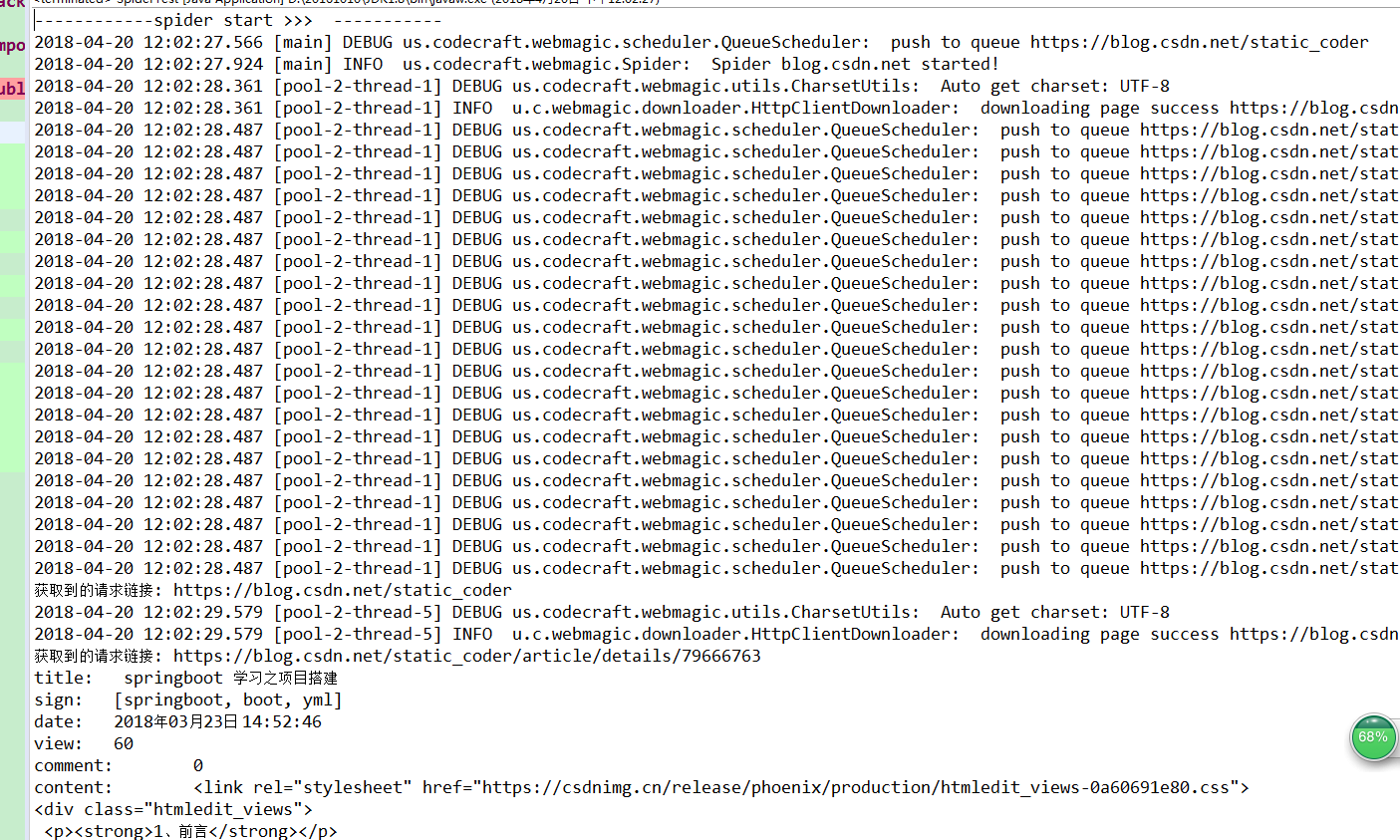
}7、测试效果
本测试中添加了日志,所以打印出来的信息比较多。
8、注意事项
webmagic默认采用log4j的方式记录日志的,详细的日志配置,只需要单独配置log4j.properties文件即可。如果要配置logback.xml,则需要已引入logback相关的依赖。日志记录可能会不生效。原因是和webmagic默认的日志系统冲突,在其依赖中排除即可正常使用。
9、参考文档
官方文档:
http://webmagic.io/
http://webmagic.io/docs/zh/
技术博客:
https://blog.csdn.net/qq598535550/article/details/51287630