由于个人经常在空闲时间在b站看些小视频欢乐一下,这次就想到了爬取b站视频的弹幕。
这里就以番剧《我的妹妹不可能那么可爱》第一季为例,抓取这一番剧每一话对应的弹幕。
1. 分析页面
这部番剧的第一季就有15话,所以我们首先需要找到每一话对应的url,然后再去爬取每一话的弹幕。
1.1 找到每一话对应的url
打开番剧的首页,可以看到每一话的信息就展示在图中位置。
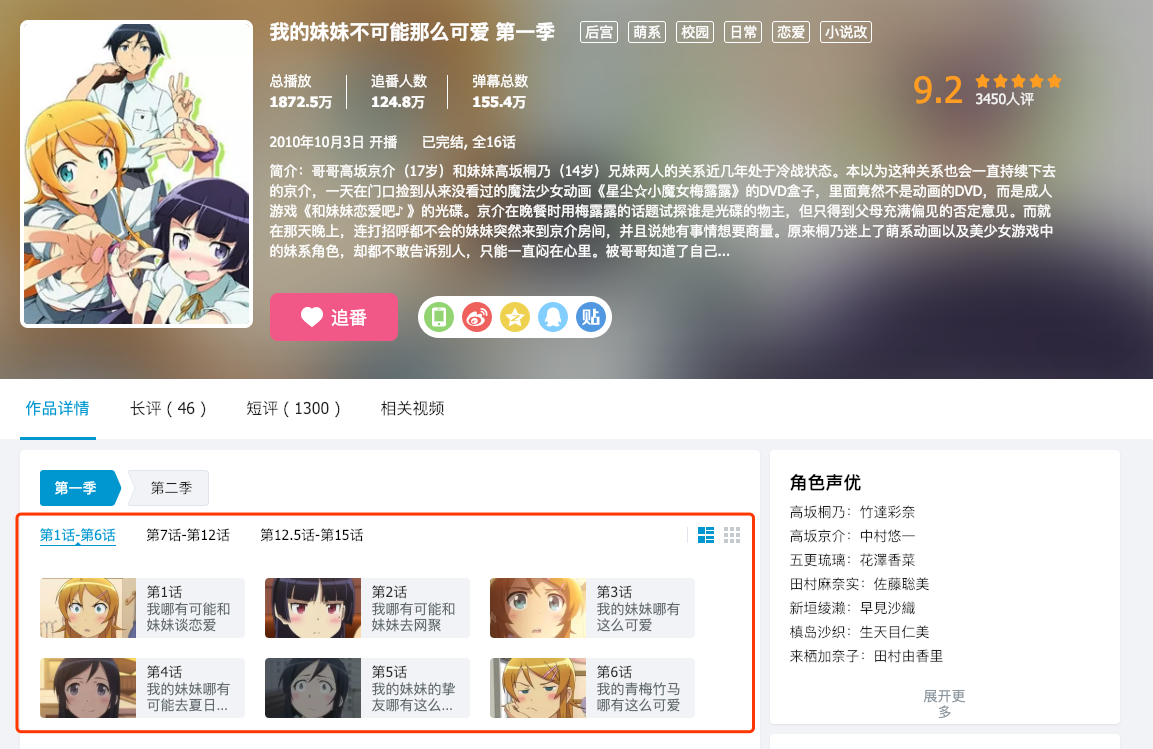
照惯例,我们首先对当前请求网页返回的数据进行查看,发现请求该url返回的只有一点简略的番剧信息,根本没有每一话的信息。
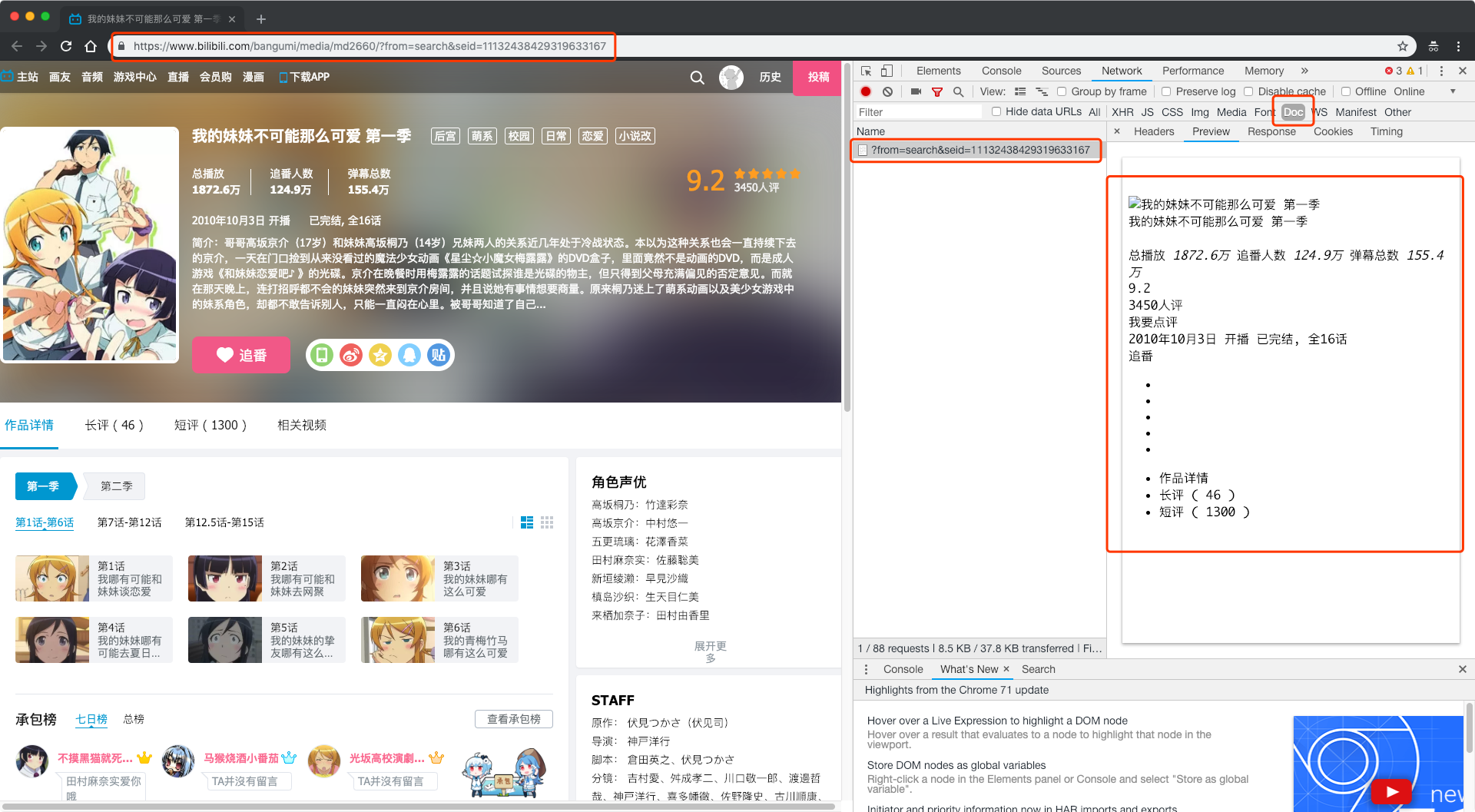
但是我们在浏览器中又确实能够看到每一话的信息,所以推测,这些信息应该是通过AJAX异步加载方式获取到的。接下来我们就查看“XHR”标签内的网络请求。
当前这一网页中XHR标签内的网络请求并不多,最简单的方法就是每一个网络请求都查看一番。但是我们可以发现,这里的每个网络请求看起来都有一定的命名规则,像info/nav/review/recommend这些,似乎都很容易理解。我们发现其中有一个请求命名为'section?season_id=...',那就先看它了。
(对于异步加载的网页,相比于随机命名,规范命名有助于程序员进行高效开发和维护。所以我们从网络请求的命名入手,一定程度上能够提高找到对应数据来源的速度和准确度)
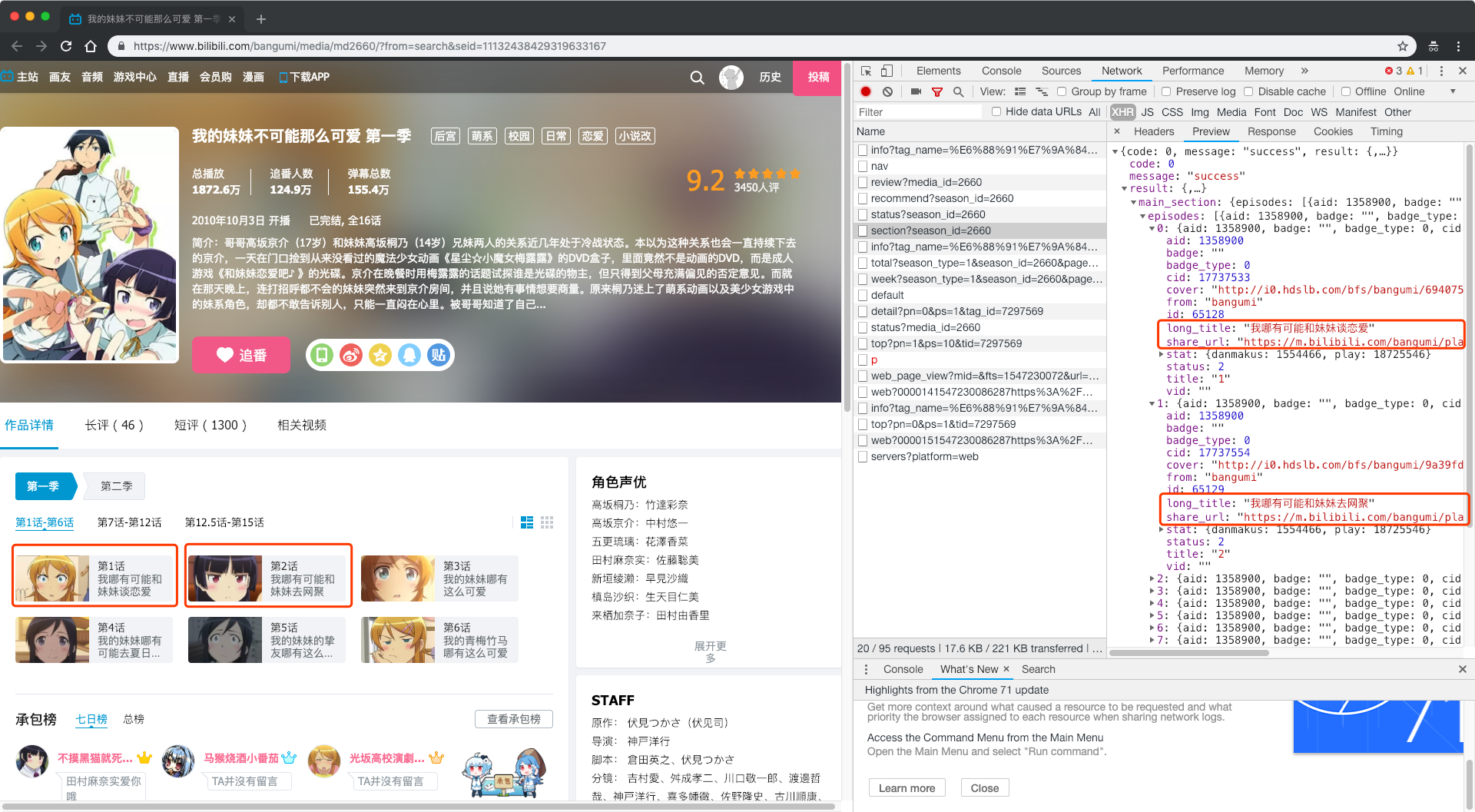
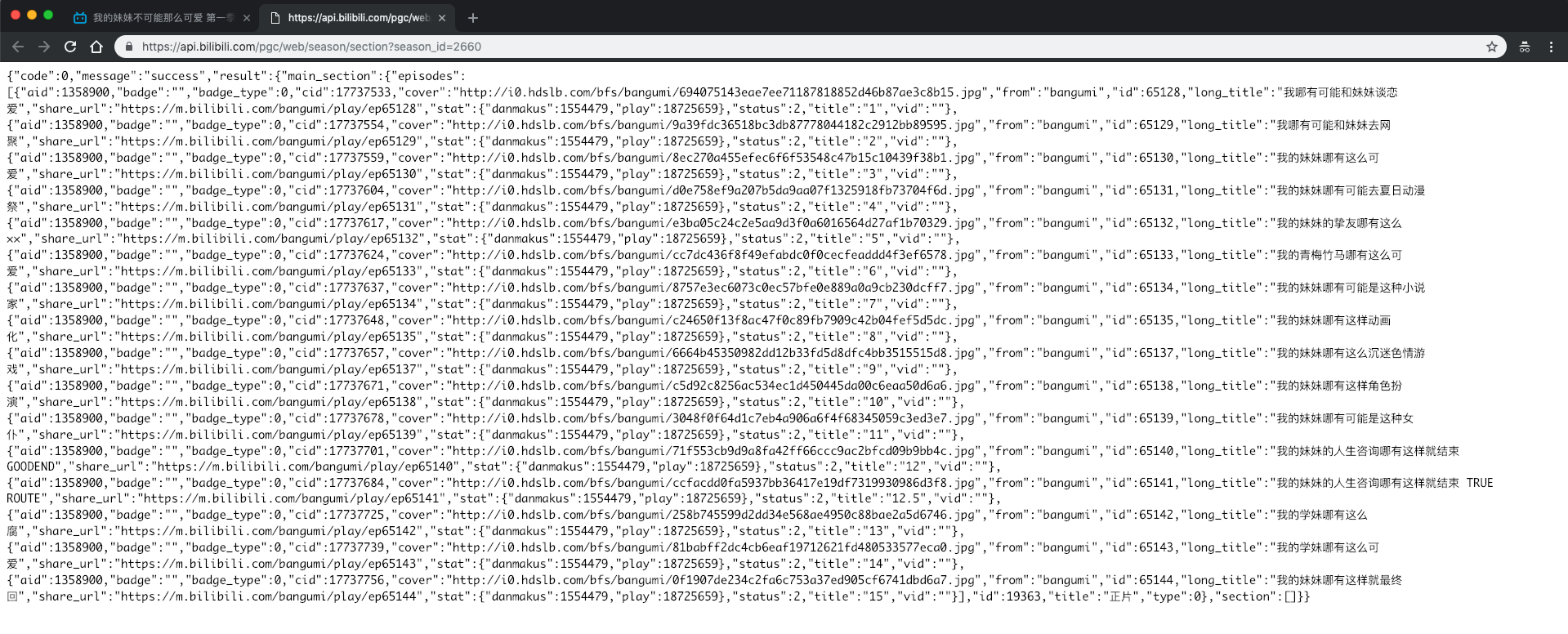
点击Preview一看,这个网络请求返回的是一个json文件,而内容恰好能够对应到这个番剧每一话的信息,打开这个请求的网页也确实发现了每一话的名称、url等信息。
那么我们就已经找到了这部番剧每一话的播放地址url。
1.2 找到当前视频对应的弹幕来源
以第一话为例,我们打开第一话的url。毫无悬念的是,请求当前url的返回信息里并没有弹幕信息。
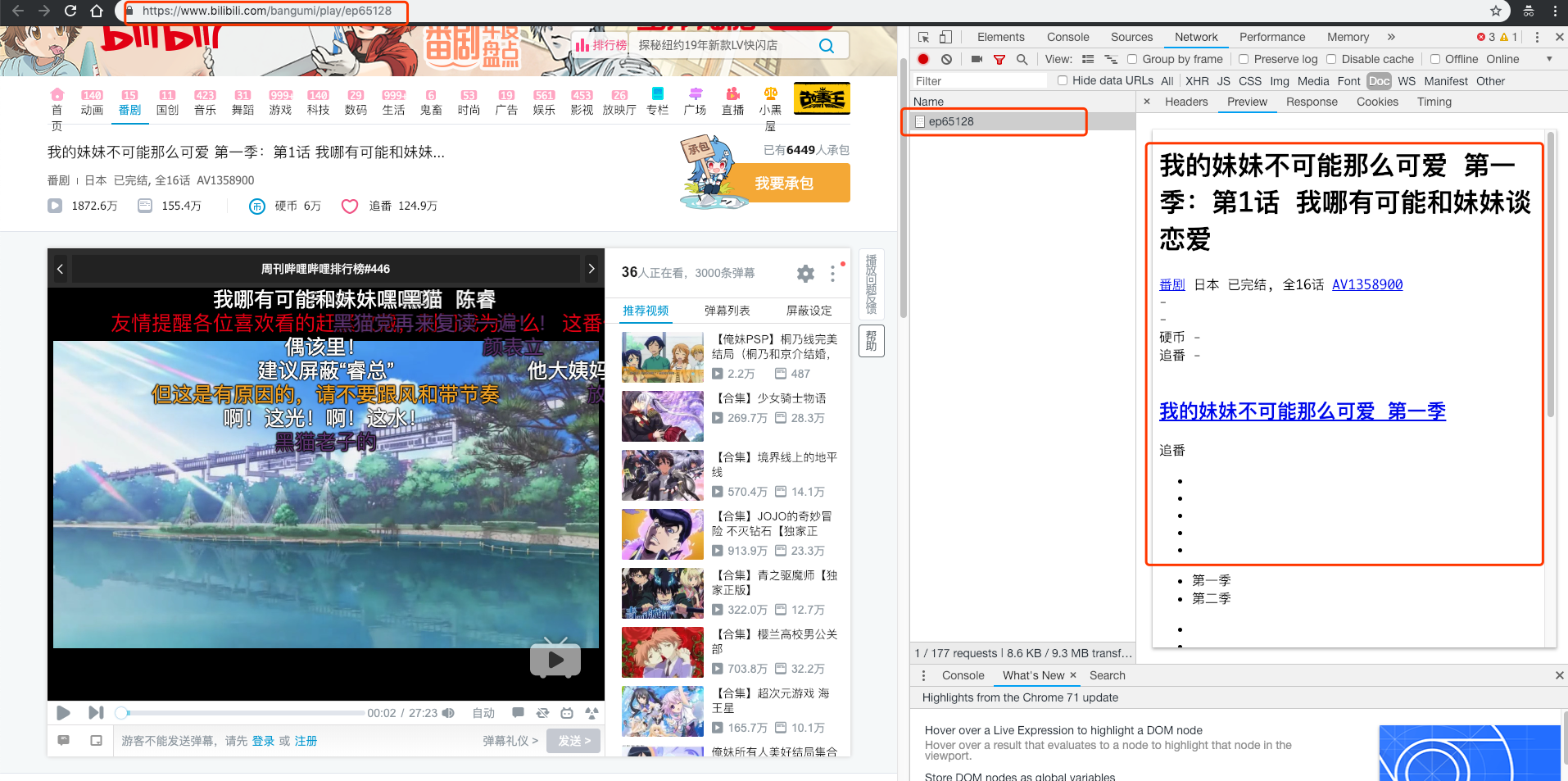
所以我们继续查看"XHR"标签。这时候,问题来了,"XHR"标签内少说也有好几十个网络请求,它们的命名好像也不是很清晰,那我们岂不是要把每个网络请求都查看一遍才能找到弹幕对应的来源。

这里要介绍一个小技巧:不管当前页面有多少个网络请求,不管这些数量繁多的网络请求是为了反爬虫还是为了页面复杂功能的实现,我们只需要记住一个宗旨:程序员是不会舍得把资源过多浪费在无关紧要的地方的。
所以这里我们将各个请求按Size进行倒叙排列,从上往下尝试几次就可以发现,弹幕是来源于这个url的:https://api.bilibili.com/x/v1/dm/list.so?oid=17737533
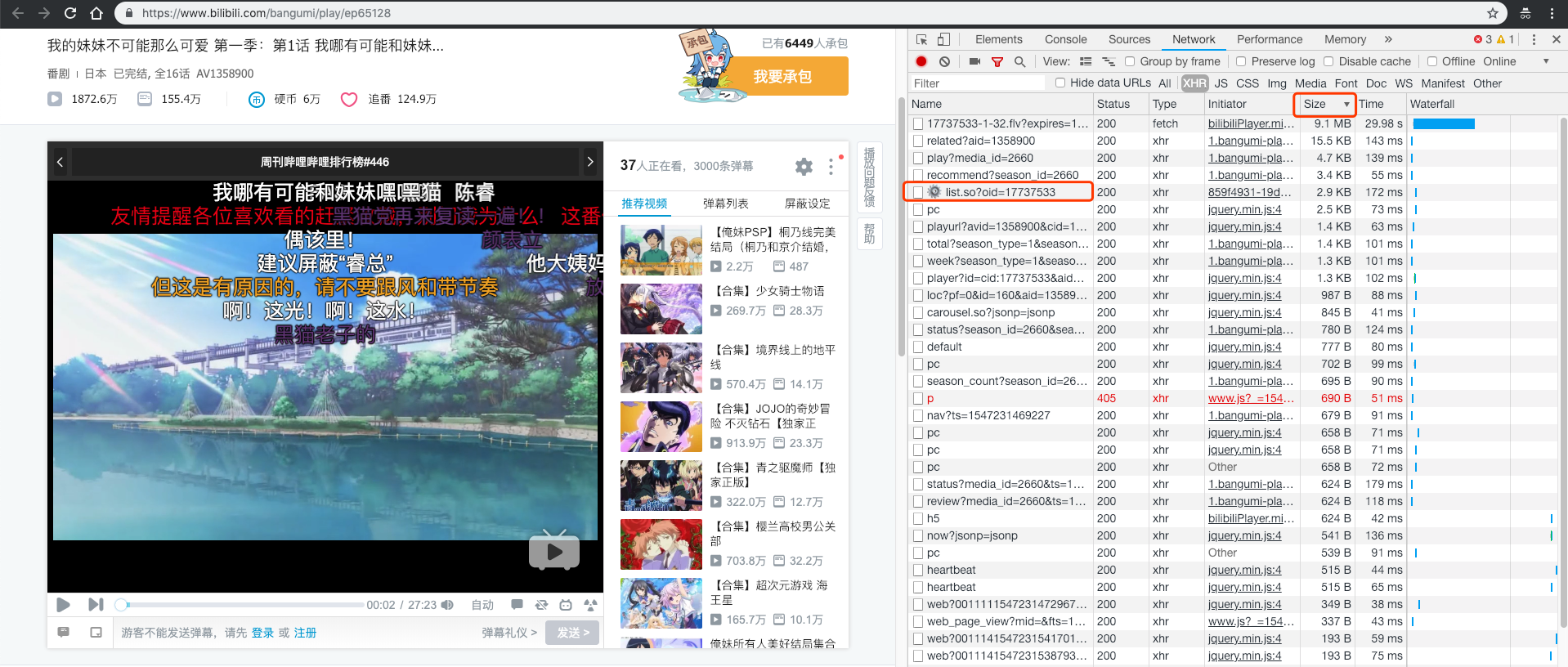
而通过查看这个网络请求的headers信息可以发现,弹幕是通过请求接口获取的,请求参数是17737533,它是这个视频的编号。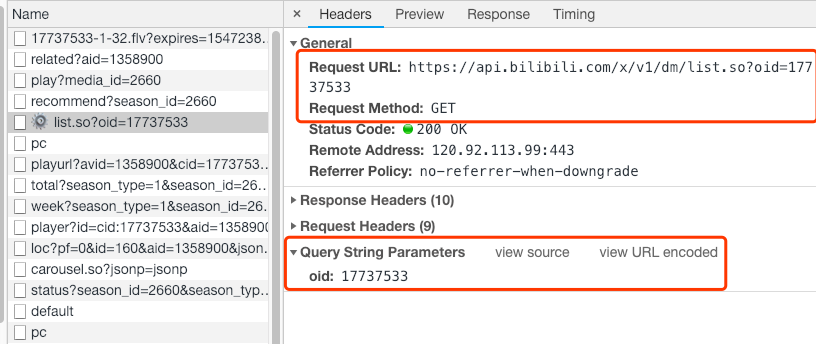
但是,当前视频的url里面明明是ep65128,这两个参数是很明显对不上的。
既然加载弹幕的请求是访问主url后才会继续的,那么通过访问主url就肯定能拿到对应的视频编号,然后加载弹幕的请求才可以通过这个编号进行加载弹幕。
那我们接下来就分析当前页面的源代码,搜索17737533,它属于cid字段。现在我们就找到了每个视频请求弹幕时它所对应的编号。

(回头查看时发现,cid这个参数在1.1中通过'section?season_id=...'也可以获取到)
1.3 抓取流程
1)通过番剧首页获取每一话对应的url和cid编号
'根据1.2,其实cid参数可以从两个地方获取到。这里我们就用简单的方法,直接在'section?season_id=...'中获取。
2)将cid编号放入“https://api.bilibili.com/x/v1/dm/list.so?oid=”后,构建url,保存每一话的弹幕信息。
2. 代码实现
import requests
from bs4 import BeautifulSoup
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
# 通过番剧首页获取每一话对应的cid编号,存入section_sid
def get_cid(index_url):
try:
index_response = requests.get(index_url, headers=header)
index_json = index_response.json() # 返回一个json文件
section_cid = []
for each in index_json['result']['main_section']['episodes']:
section_cid.append({
'title': each['long_title'],
'cid': each['cid'],
'id': each['id'],
'url': each['share_url']
})
except:
print('index pass')
return section_cid
# 通过cid编号获取这一话的所有弹幕信息
def get_danmu(cid):
try:
danmu_response = requests.get('https://api.bilibili.com/x/v1/dm/list.so?oid='+str(cid), headers=header)
danmu_soup = BeautifulSoup(danmu_response.content, 'lxml')
for each in danmu_soup.findAll('d'):
danmu_info = each['p'].split(",")
danmu_detail.append({
'cid': cid, # 弹幕对应视频cid
'danmu': each.get_text(), # 弹幕内容
'time': danmu_info[0], # 弹幕出现时间(秒)
'type': danmu_info[1], # 弹幕模式
'size': danmu_info[2], # 字号
'color': danmu_info[3], # 颜色
'timestamp': danmu_info[4], # 时间戳
'pool': danmu_info[5], # 弹幕池
'sender': danmu_info[6], # 发送者ID
'row': danmu_info[7] # 弹幕rowID,用于“历史弹幕”功能
})
print(cid, 'done')
except:
print(cid, 'pass')
danmu_detail = [] # 所有弹幕存入danmu_detail
section_cid = get_cid(index_url)
[get_danmu(each_section['cid']) for each_section in section_cid]