一、概述
Avro是一种远程过程调用和数据序列化框架,是在Apache的Hadoop项目之内开发的。它使用JSON来定义数据类
型和通讯协议,使用压缩二进制格式来序列化数据。它主要用于Hadoop,它可以为持久化数据提供一种序列化格
式,并为Hadoop节点间及从客户端程序到Hadoop服务的通讯提供一种电报格式。
二、序列化和反序列化
概述
数据序列化就是将对象或者数据结构转化成特定的格式,使其可在网络中传输,或者可存储在内存或者文件中。反
序列化则是相反的操作,将对象从序列化数据中还原出来。
数据序列化的重点在于数据的交换和传输 。
衡量标准
- 序列化之后的数据大小
因为序列化的数据要通过网络进行传输或者是存储在内存或者文件中,所以数据量越小,则存储或者传输所
用的时间就越少 - 序列化以及反序列化的耗时及占用的CPU
- 是否能够跨语言或者平台
因为现在的企业开发中,一个项目往往会使用到不同的语言来进行架构和实现。那么在异构的网络系统中,
网络双方可能使用的是不同的语言或者是不同的操作系统,例如一端使用的是Java而另一端使用的C++;或者
一端使用的是Windows系统而另一端使用的是Linux系统,那么这个时候就要求序列化的数据能够在不同的语
言以及不同的平台之间进行解析传输
Java原生序列化/反序列化机制的问题
- Java的原生序列化不能做到对象结构的服用,就导致序列化多个对象的时候数据量较大
- Java的原生序列化在使用的时候,是按照Java指定的格式将对象进行解析,解析为字节码格式,那么此时其他
的语言在接收到这个对象的时候,是无法解析或者解析较为困难。即Java的原生序列化机制是没有做到跨语言
或者跨平台传递使用
三、常见序列化框架
Protobuf
Protobuf是Google公司提供的序列化/反序列化框架,特点如下:
- 平台无关、语言无关。
- 二进制、数据自描述。
- 提供了完整详细的操作API。
- 高性能,比xml要快20-100倍
- 尺寸小,比xml要小3-10倍,高可扩展性
- 数据自描述、前后兼容
Thrift
Thrift是Facebook公司提供的序列化/反序列化的框架,2007年贡献给了Apache。特点如下:
- 支持非常多的语言绑定
- thrift文件生成目标代码,简单易用、
- 消息定义文件支持注释
- 数据结构与传输表现的分离,支持多种消息格式
- 包含完整的客户端/服务端堆栈,可快速实现RPC
- 支持同步和异步通信
三、Avro的特点
- 丰富的数据结构类型,8种基本数据类型以及6种复杂类型
- 快速可压缩的二进制形式
- 提供容器文件用于持久化数据
- 远程过程调用RPC框架
- 简单的动态语言结合功能,Avro 和动态语言结合后,读写数据文件和使用 RPC协议都不需要生成代码,而代
码生成作为一种可选的优化只值得在静态类型语言中实现。而代码生成作为一种可选的优化只值得在静态类
型语言中实现。
通过avro,每次进行序列化,根据模式(schema)文件来序列化,可以提高性能。
Avro是依赖于模式(schema),模式文件是用json格式来表示的。如果是想利用avro实现序列化或rpc通信,需要
遵守schema的格式要求。基于模式的好处是使得序列化快速而又轻巧
四、Avro的格式说明
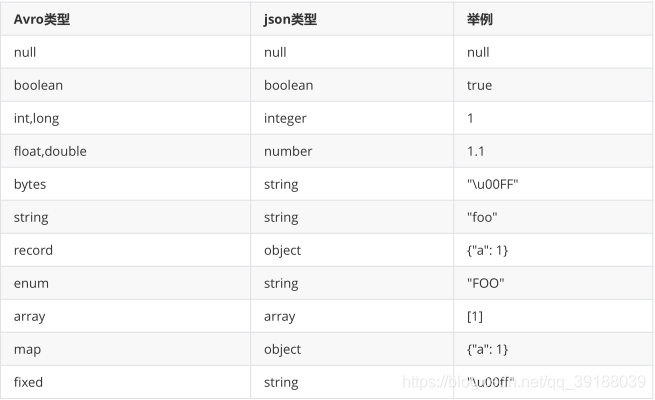
简单类型
Avro定义了8种简单数据类型,下表是其简单说明:
| Avro类型 | 说明 |
|---|---|
| null | 没有值 |
| boolean | 一个二级制布尔值 |
| int | 32位有符号整数 |
| long | 64位有符号整数 |
| float | 32位单精度浮点数 |
| double | 64位双精度浮点数 |
| bytes | 8位无符号字节序列 |
| string | 字符序列 |
复杂格式
Avro定义了六种复杂数据类型,每一种复杂数据类型都具有独特的属性,下表就每一种复杂数据类型进行说明。
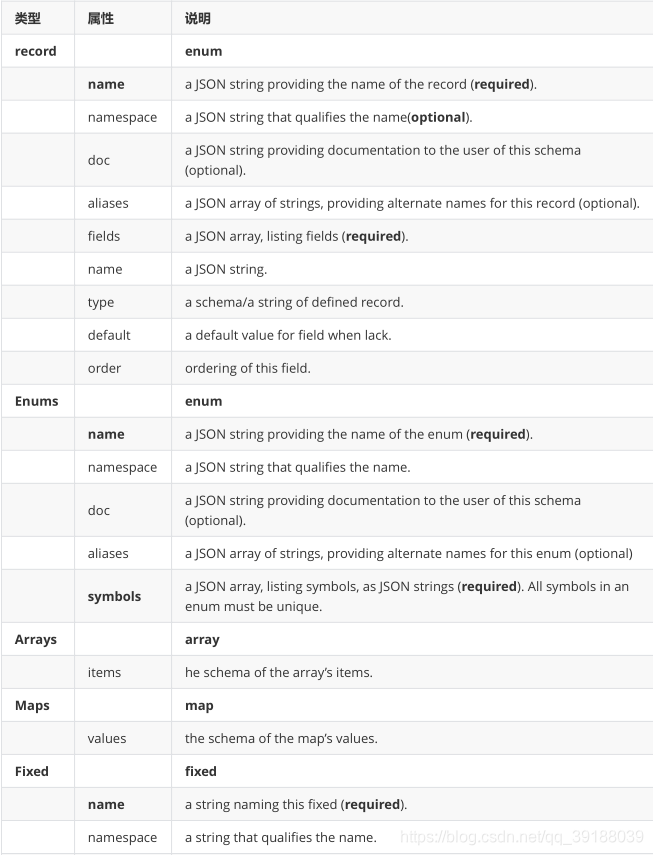

每一种复杂数据类型都含有各自的一些属性,其中部分属性是必需的,部分是可选的。
这里需要说明Record类型中field属性的默认值,当Record Schema实例数据中某个field属性没有提供实例数据
时,则由默认值提供,具体值见下表。Union的field默认值由Union定义中的第一个Schema决定。
五、Avro的序列化与反序列化
- 创建Maven工程,导入Avro的依赖
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-ipc</artifactId>
<version>1.7.5</version>
</dependency>
完整的pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.test.avro</groupId>
<artifactId>Avro</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>Avro</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<compiler-plugin.version>2.3.2</compiler-plugin.version>
<avro.version>1.7.5</avro.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.4</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-ipc</artifactId>
<version>1.7.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${compiler-plugin.version}</version>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.7.5</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
<configuration>
<!-- 表示Avro的模式文件的存储位置 -->
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<!-- 表示利用模式文件生成的类存放的位置 -->
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 在指定的目录下编辑一个avsc文件。例如:
{
"namespace":"avro.pojo",
"type":"record",
"name":"Person",
"fields":
[
{"name":"username", "type":"string"},
{"name":"age", "type":"int"},
{"name":"no", "type":"string"}
]
}
- 选中pom.xml文件,右键,选择Run as,点击Maven generate-sources
- 序列化操作
@Test
public void write() throws Exception{
User u1=new User("Ken Tompson",194375);
User u2=new User("丹尼斯·里奇",194170);
DatumWriter<User> dw=new SpecificDatumWriter<>(User.class);
DataFileWriter<User> dfw=new DataFileWriter<>(dw);
// 创建底层的文件输出通道
// schema - 序列化类的模式
// path - 文件路径
dfw.create(u1.getSchema(),new File("1.txt"));
// 把对象数据写到文件中
dfw.append(u1);
dfw.append(u2);
dfw.close();
}
- 反序列化操作
@Test
public void read() throws Exception{
DatumReader<User> dr=
new SpecificDatumReader<>(User.class);
DataFileReader<User> dfr=
new DataFileReader<>(new File("1.txt"),dr);
//--通过迭代器,迭代出对象数据
while(dfr.hasNext()){
System.out.println(dfr.next());
}
}
六、RPC
概述
RPC 的全称是 Remote Procedure Call(远程过程调用) 是一种进程间通信方式。它允许程序调用另一个地址空
间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。 即程序员无论
是调用本地的还是远程的,本质上编写的调用代码基本相同。
起源
布鲁斯·纳尔逊1974年毕业于哈维·穆德学院,1976年在斯坦福大学获得计算机科学硕士学位,1982年在卡内基梅
隆大学获得计算机科学博士学位。在追求博士学位时,他开发了远程过程调用(RPC)的概念。他和他的合作者安
德鲁·伯雷尔因在RPC方面的工作而获得了1994年ACM软件系统奖。1996他加入思科系统担任首席科学官。
特点
- 简单:RPC 概念的语义十分清晰和简单,这样建立分布式计算就更容易。
- 高效:过程调用看起来十分简单而且高效。
- 通用:在单机计算中过程往往是不同算法部分间最重要的通信机制。 通俗一点说,就是一般程序员对于本地
的过程调用很熟悉,那么我们在通过网络做远程通信时,通过RPC 把远程调用做得和本地调用完全类似,那
么就更容易被接受,使用起来也就毫无障碍。
RPC架构
模块
- 用户(User)
- 用户存根(User-Stub)
- RPC通信包(称为RPCRuntime)
- 服务器存根(Server-Stub)
- 服务器(Server)
关系图
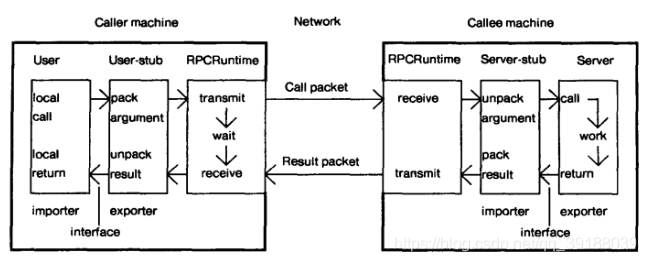
过程
- 服务消费方(User)调用以本地调用方式调用服务
- User-stub(存根)接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体,并交给
RPCRuntime模块 - RPCRuntime找到服务地址,并将消息发送到服务端
- 服务端的RPCRuntime收到消息后,传给Server-stub
- Server-stub根据解码结果调用本地的服务
- 本地服务执行并将结果返回给Server-stub
- server stub将返回结果打包成消息并发送至消费方
- client stub接收到消息,并进行解码
- 服务消费方得到最终结果
RPC调用细节
- 接口方式的调用
RPC设计的目的在于可以让调用者可以像以本地调用方式一样调用远程服务。具体实现的方式是调用接口的方
式来调用。在java中,底层通过Java动态代理方式生成接口的代理类,代理类中封装了与远程服务通信的细
节。这些细节包括:
客户端的请求消息:
- 接口名称
- 方法名
- 参数类型以及相应的参数值
- requestID,标识唯一请求id
服务器端的返回消息:
- 返回值
- requestID
- 序列化
- 通信
一般RPC通信都是基于NIO进行通信
RPC框架的特点
- 基于RPC的进程通信方式
- 有自定义的一套序列化和反序列的机制
- 客户端通过代理机制调用远程方法
- 服务端通过回调机制执行方法及返回结果
Avro的RPC - 创建客户端的Maven工程,导入Avro的依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.test.avro</groupId>
<artifactId>Avroclient</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>Avroclient</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<compiler-plugin.version>2.3.2</compiler-plugin.version>
<avro.version>1.7.5</avro.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.4</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-ipc</artifactId>
<version>1.7.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${compiler-plugin.version}</version>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.7.5</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
<configuration>
<!-- 表示Avro的模式文件的存储位置 -->
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<!-- 表示利用模式文件生成的类存放的位置 -->
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 在指定的目录下编辑一个avdl文件。例如:
@namespace("rpc.service")
protocol AddService{
int add(int i,int y);
}
如果想要传递的是一个对象,则约束如下:
@namespace("rpc.service")
protocol TransferService{
import schema "User.avsc";
void parseUser(avro.domain.User user);
}
如果想要传递一个map,并且map里包含一个对象的代码:
@namespace("rpc.service")
protocol MapService{
import schema "User.avsc";
void parseUserMap(map<avro.domain.User> userMap);
}
- 实现客户端
public class Start {
public static void main(String[] args) throws Exception {
NettyTransceiver client=new NettyTransceiver(
new InetSocketAddress("127.0.0.1",8888));
//--因为接口不能直接使用,avro底层是通过jdk动态代理生成接口的代理对象
AddService proxy=
SpecificRequestor.getClient(AddService.class, client);
int result=proxy.add(2, 3);
System.out.println("客户端收到结果:"+result);
}
}
- 服务器端实现接口
public class AddServiceImpl implements AddService{
@Override
public int add(int a, int b) throws AvroRemoteException {
return a+b;
}
}
- 实现服务器端
public class Start {
public static void main(String[] args) {
System.out.println("服务端启动");
NettyServer server=new NettyServer(
new SpecificResponder(AddService.class,
new AddServiceImpl()),
new InetSocketAddress(8888));
}
}