版权声明:转载请注明出处 https://blog.csdn.net/nanhuaibeian/article/details/85572918
1. 编码方式属性
| GB2312 | UTF-8 | Unicode |
|---|---|---|
| GB2312编码专门用来解决中文编码的,是双字节的,并且不论中英文都是双字节的;包含全部中文字符;总的来说GB2312编码方式的编码是以中国国情而创造的,在国际上的兼容性不好。 | UTF-8 编码是Unicode的一种实现方式,因为对于大多数语言,只需要一个字节就能够编码,如果都采用Unicode会极大浪费,于是出现了可变长编码UTF-8。它对英文使用8位(即一个字节),中文使用24位(三个字节)来编码。另外,如果是外国人访问你的GB2312网页,需要下载中文语言包支持。访问UTF-8编码的网页则不出现这问题。可以直接访问。这也是为什么大多数的网页是使用UTF-8编码而不是GB2312。 | 目前几乎收纳了全世界大部分的字符。所有的字符都有唯一的编号,这就解决了解码的冲突!但是,unicode把大家都归纳进来,却没有为编码的二进制传输和二进制解码做出规定。 |
#Python 2.7 默认UTF8
'你好' ->'\xe4\xbd\xa0\xe5\xa5\xbd'
'你好'.decode('utf8') -> 转换为Unicode u'\u4f60\u597d'
#Python 3.6 默认Unicode
'你好'.encode('utf8') -> 转换为UTF8 编码
2. 转码函数
| decode | encode |
|---|---|
| decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312’),表示将gbk编码的字符串str1转换成unicode编码。 | encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘gb2312’),表示将unicode编码的字符串str2转换成gbk编码。 |
3. 乱码原因
源网页编码和爬取下来后的编码转换不一致。如源网页为gbk编码的字节流,而我们抓取下后程序直接使用utf-8进行编码并输出到存储文件中,这必然会引起乱码,即当源网页编码和抓取下来后程序直接使用处理编码一致时,则不会出现乱码,此时再进行统一的字符编码也就不会出现乱码了。
4. test.content 和 test.text的区别
对requests获取的原始数据,有两种获取形式,一个是test.content一个是test.text。
二者的区别在于content返回的是byte型数据,而text返回的是Unicode数据,
也就是说text对原始数据进行的特殊的编码,而这个编码方式是基于对原始数据的猜测(响应头)。
text返回的是unicode 型的数据,一般是在网页的header中定义的编码形式。
content返回的是bytes,二级制型的数据。
但是对于某些网站的中文用text可能会导致返回乱码,所以最好是使用content然后自己进行重新编码,而且如果你想要提取图片、文件,也要用到content。
#.content打印的是原始编码
import requests
url = 'http://www.pocketuni.net/'
response = requests.get(url)
response.encoding = 'utf-8'
print (response.content)
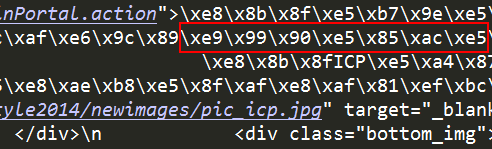
#使用.test打印数据
import requests
url = 'http://www.pocketuni.net/'
response = requests.get(url)
response.encoding = 'utf-8'
print(response.content.decode('utf-8'))
#实际上response.text和response.content.decode('utf-8')效果相同
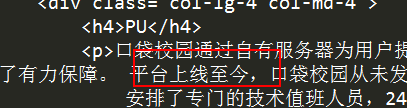
5. 寻找到目标网页的编码格式
- 查看网页源代码
- 检查元素,查看Response Headers