为什么要引入 Alluxio
- 通过监控发现计算节点的物理内存有富余,不需要增加额外机器成本
- 机器网卡较为空闲,瓶颈主要存在于磁盘IO
- HDFS所在磁盘存在多种不同类型负载,数据读取速度不稳定
- 热数据读取加速
- 存储计算分离,在计算节点提高数据本地性
- 统一命名空间,虚拟数据湖
读取数据的效率取决于哪些因素
数据读取时间 = 解压时间 + IO 时间
IO的优化一般由如下几个方面:
- 根据业务场景使用压缩率更高的算法,在IO和CPU直接做平衡,例如使用 ZSTD
- 更少的数据读取,例如在分析场景使用列式存储
- 提高IO速度,硬件方面可以从 RAM,SSD,OPTANE 等硬件加速,网卡则可以使用双万兆网卡
- 提高数据读取的本地性,减少网络IO
- 分布式计算中使用RDMA技术,大幅减少额外开销
- etc.
计算&存储分离
混合部署
一般来说,为了获取更好的数据本地性,我们会将 datanode 与 nodemanager 混合部署,这就意味着相同的一块硬盘需要同时承担 hdfs读写 / spark中间数据(shuffle)读写等负载,任务运行时间在一定程度上是不可控的,同时也会影响计算效率。
分离部署
缺点:
- 不存在数据本地性,所有分析数据需要从远程获取
优点:
- 计算/存储节点不需要强耦合(不会仅仅因为存储空间不足而扩容计算节点)
- 考虑到云服务商能力的不断增强,甚至可以考虑业务高峰动态扩容
- spark on k8s 等趋势,可以快速部署
可以发现,分离部署的性能瓶颈主要存在于没有数据本地性,所有的数据都要从远程存储读取。这种场景下可以尝试将 Alluxio 与 计算节点混合部署,同时将远程存储挂载在Alluxio上。热数据第一次从远程读取后,可以在本地进行备份(RAM/SSD/HDD),下一次读取将可以从 local 或者 local remote 直接读取。再配合LRU或LFU等策略,不断的将热数据置换到上层存储,冷数据则逐渐不再计算节点存储。
测试
环境
- alluxio 1.8.1
- spark 2.4.0
- cdh 5.15
- spark-sql-perf
nodemanager / alluxio / datanode 混合部署,alluxio 每个节点分配10G内存,单副本缓存,hdfs 使用3副本。
理论性能提升
在没有其余任务干扰的情况下,HDFS 数据本地性应是 Alluxio 的3倍左右,Alluxio 没有命中本地数据的读取速度是 HDFS 的 2.5 倍左右
| … | hdfs | alluxio |
|---|---|---|
| 副本数 | 3 | 1 |
| 数据峰值读取速度 | 100 MB/S * 3 | 800 MB/S (纯网络读取) |
Scan
对 24G parquet.snappy 数据进行单字段 filter
Alluxio 数据本地性 5%,HDFS 数据本地性 16.5%
| … | hdfs | alluxio |
|---|---|---|
| 1 | 12s | 15s |
| 2 | 5s | 2s |
| 3 | 5s | 2s |
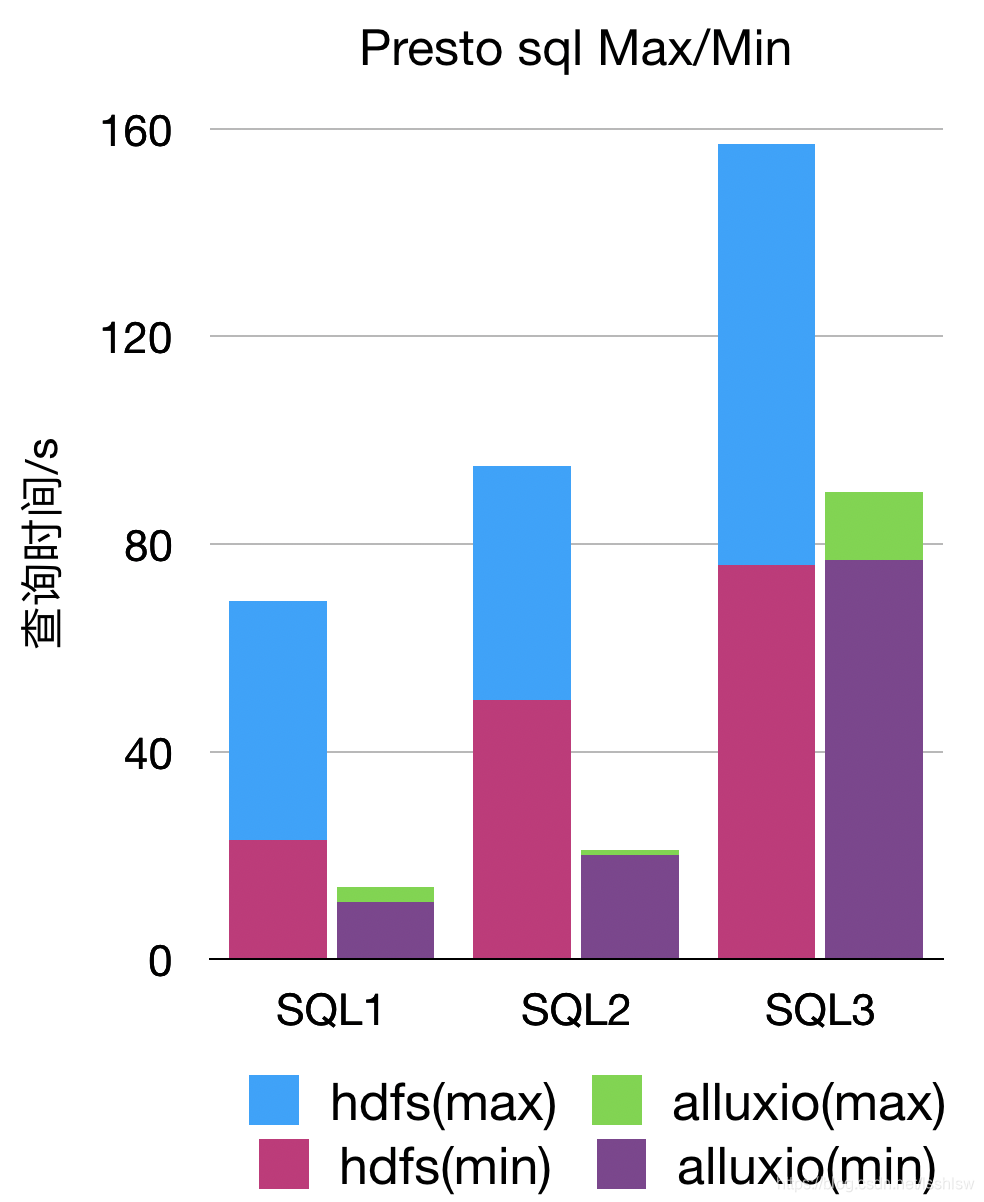
Presto
presto 本地没有部署 Alluxio (所有数据通过网络传输)
- 6 presto worker
- -xmx 20G
- query.max.memory=100GB
- query.max-memory-per-node=5GB
结果
相同sql,连续执行5次
1)千万级表
tableA 1.2G (2千万)
| presto sql | HDFS(s) | Alluxio(s) |
|---|---|---|
| count | 5 | 2 |
| distinct + where | 3~10 | 1 |
| group by | 2 | 1 |
2)亿级表
tableB 900G (45亿)
| presto sql | HDFS(s) | Alluxio(s) |
|---|---|---|
| count | 23~69 | 11~14 |
| distinct + where | 50~95 | 20~21 |
| group by | 76~157 | 77~90 |
TPC-DS
为模拟真实环境,在任务高峰期同时运行两任务,运行时可能会受其他任务影响,主要是磁盘IO和网络IO。
使用 spark-sql-perf 使用工具进行测试
- executor.nums 40
- executor.cores 3
- executor.memory 8g
- executor.memoryOverhead 2g
结果
前11个查询耗时对比
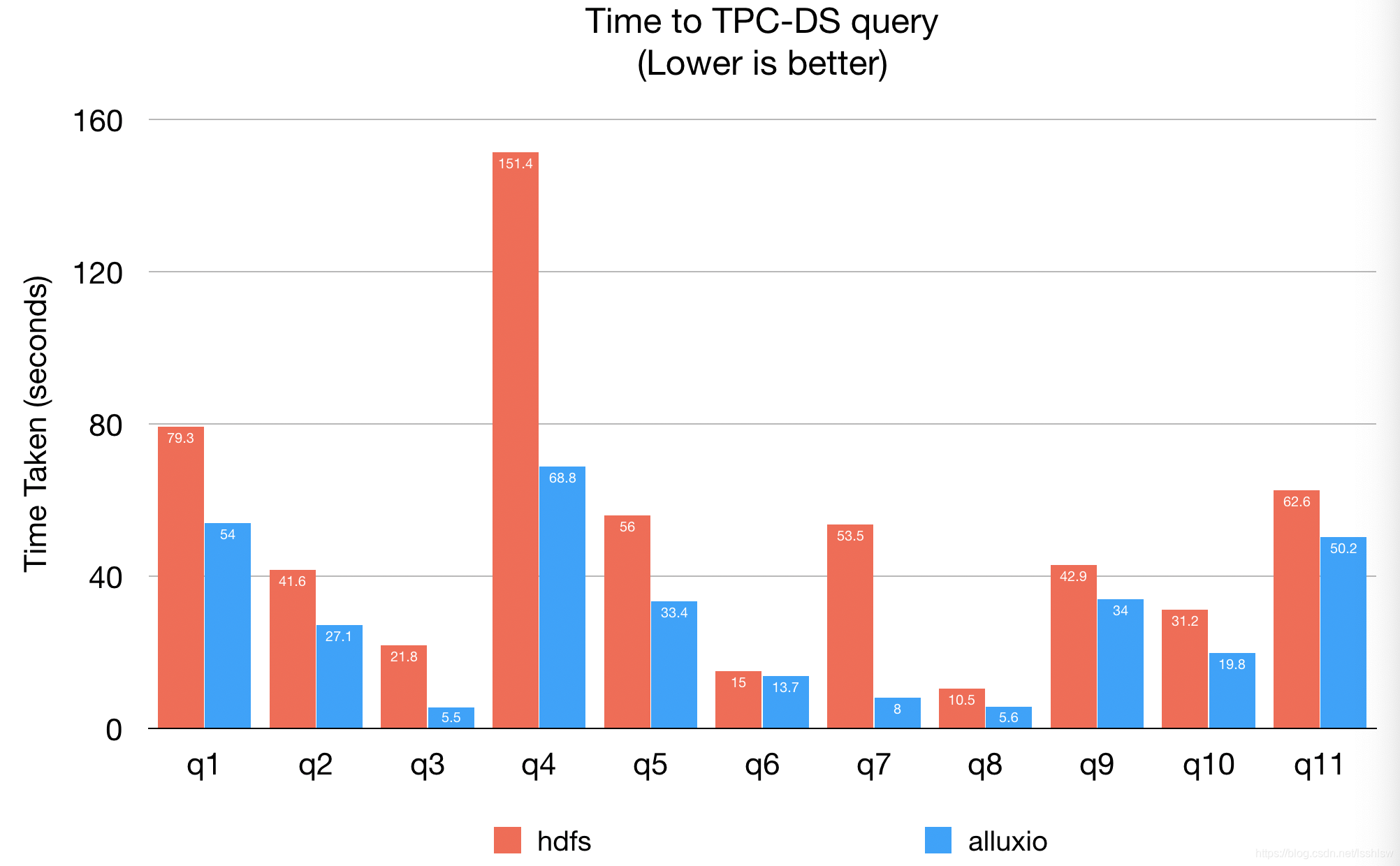
在所有的99个查询中
- hdfs 平均运行时间:40.6s
- alluxio 平均运行时间: 28.3s
总结
- Scan ,alluxio 提升 2.5x
- Presto ,alluxio 提升 2x
- TPC-DS ,alluxio 平均提升 1.4x
- alluxio 多次测试结果比较稳定,hdfs 的波动则比较大,参考 presto 测试结果
在整个测试中,alluxio 使用单副本缓存,本地命中率并不高(5%),读取速度主要取决于网络IO。
HDFS 虽然有三备份,不过数据从磁盘读取时可能会受到其他任务的干扰,因此速度不太稳定。
落地相关
Alluxio 的落地非常依赖场景,否则优化效果并不明显(无法发挥内存读取的优势)。
- 存储计算分离
- 有明显热表/热数据
- 多数据中心访问加速
- 相同数据被单应用多次访问
- 数据并发访问
展望Alluxio 2.0,下个版本的 Alluxio 有很多重大的更新,可以持续关注。