- From Face Recognition to Models of Identity: A Bayesian Approach to Learning about Unknown Identities from Unsupervised Data,ECCV 2018
论文链接
概要:
当前人脸识别存在两个问题:
- 当前系统无法从大量未标注数据中受益;
- 泛化到新身份的能力差。
贡献:
- 提出无监督的人脸识别模型,可以明确推断出未见过的人脸(具体来讲??)
- 提出新颖且鲁棒的标签模型,使其通过学习有身份标注和无身份标注的图像来预测人脸
于是我们提出了集成的贝叶斯模型,该模型连贯性地证明了观察到的图像、身份、名字的部分知识和情境背景。该模型不但对已知身份识别能力很好,也能发现新身份(新身份包括熟悉的人脸但标签未知和完全不熟悉的人脸),通过观察哪些身份往往被一起观察,学习将身份与不同的上下文(context???)关联。
1.介绍
我们通常将面部识别问题划分为两个子问题: recognition and tagging

观察图1a,标准人脸识别是完全监督的,依赖于大量高质量标注的数据集,但是这种方法和人类的社会经验相比还是有限的。
观察图b,人脸识别不会发生在孤立的环境中,而是发生在情境环境中。实际情况中,有标注的图像很少,例如人类在日常生活中,熟人介绍新身份的人脸只介绍一次,人类可以将身份信息推广到所有的照片。所以我们引入了集成的贝叶斯模型,反映了关于身份分布、情境意识、标签等所有考虑因素。
2.相关工作
1)其它人脸识别,常将自己局限于点估计(即对样本数据进行参数估计,得到的是一个具体的数值),是点到点的过程。我们的方法是端到端的过程,是基于网络的。
2)我们的模型是human-like的
3)上下文模型、身份模型、人脸模型


生成模型概述,未填充节点表示潜在变量,阴影节点表示观测到的,半阴影节点表示仅针对索引的子集观测到的,未圈定节点表示超参数。
π0和πc分别是全局和上下文的身份概率;w表示上下文概率;cm表示上下文标签,由框架号fn索引,fn ∈ {1, . . . , M};zn是潜在的身份指示器;xn是观测到的人脸;yn是xn对应的身份标注;θi是face model的参数;yi*包含了所有的身份标签。
3.模型
假设数据以相机框架(照片或视频)的形式收集,用人脸检测系统裁剪完,根据框架书fn分组,fn ∈ {1, . . . , M}。
1)context model。在身份识别场景中,想象一下人在上下文之间移动,(e.g. home–work–gym…),于是对于每个观测提出一个上下文标签cn ∈ {1, . . . , C},可以对同一环境中出现的多个人脸进行更正确的预测,提升混合模型的聚类效果。
cm*根据概率w独立分布,概率w符合Dirichlet分布。
k阶Dirichlet分布: 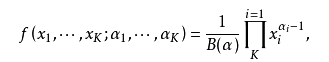
2)Identity model。在日常生活场景中,随着观测人脸数目的增加,独特的面孔也会增加,但是比前者慢很多,并且可以认为是无限的。
2.Monocular Reconstruction 单眼重建的自监督人脸模型
名称:Self-Supervised Multi-Level Face Model Learning for Monocular Reconstruction at Over 250 Hz,斯坦福大学,CVPR 2018