1 概述
上篇文章讲解了PCA主成分分析,这篇文章使用该训练模型实现验证码识别,同时作者也会提供全部源代码。希望能够帮助到大家。
2 图像原理
在计算机图形学里,位图就是一个像素的矩阵,矩阵中的每一个点都是各种颜色的点,最后总体上来看就是一副图像。如何显示每一个像素的具体颜色,有很多种颜色空间,最常见的就是RGB,每一个像素含有三个分量——R,G,B,分别代表红、绿和蓝三种颜色,三个分量的值的具体的大小就代表三种颜色的深浅,而最终该像素显示出来的颜色就是这三种颜色混合而成的。BMP图片种每个像素的颜色就是以位图的形式储存的,bmp文件主要是由三部分组成,最开始是文件头,54个字节固定大小,包含了图片的最基本信息,包括图片的分辨率、数据位长度等信息;第二部分是调色板,如果位图长度位24位那么就不需要调色板。24位分别代表红绿蓝三种颜色,每个颜色的取值范围是0~255;如果位图长度是32位,那么分别代表的是红、绿、蓝、透明度。16位一般表示红绿蓝占比5:6:5;8位的是存的在调色板中的索引值。
3 验证码识别
在做编写爬虫脚本过程中,难免会遇到网站的验证码问题;那么这篇文章针对最简单的6位验证码来做实验,如何做到识别率到100%。权当入门教学文章。验证码如下图所示。训练图片最主要是提取各个字符的特征值,特征值在数学齐次方程代表的是特征向量,当特征向量更接近对角矩阵时,该特征值是最准确的。

4 特征值提取
4.1 灰度处理
灰度化应用很广,而且也比较简单。灰度图就是将白与黑中间的颜色等分为若干等级,绝大多数位256阶。在RGB模型种,黑色(R=G=B=0)与白色(R=G=B=255),那么256阶的灰度划分就是R=G=B=i,其中i取0到255。
灰度化的方法一般有以下几种:
- 分量法
在rgb三个分量种按照需求选取一个分量作为灰度值 - 最大值
选取rgb的最大值作为该pixel的灰度值 - 平均值
g[i,j] = (r[i,j] + g[i,j] + b[i,j]) / 3,取rgb的平均值作为灰度值 - 加权变换
由于人眼对绿色的敏感最高,对蓝色敏感最低,因此,按下式对RGB三分量进行加权平均能得到较合理的灰度图像。
cvtColor(m_Mat,iGray,COLOR_BGR2GRAY); /* 加权平均值灰度化 /
结果如下:
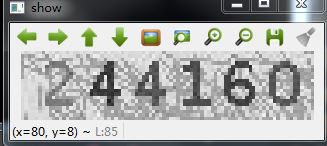
4.2 二值化
二值化是整个图像所有像素只有两个值可以选择,一个是黑(灰度为0),一个是白(灰度为255)。二值化的好处就是将图片上的有用信息和无用信息区分开来,比如二值化之后的验证码图片,验证码像素为黑色,背景和干扰点为白色,这样后面对验证码像素处理的时候就会很方便。常见的二值化方法为固定阀值和自适应阀值,固定阀值就是制定一个固定的数值作为分界点,大于这个阀值的像素就设为255,小于该阀值就设为0,这种方法简单粗暴,但是效果不一定好.另外就是自适应阀值,每次根据图片的灰度情况找合适的阀值。自适应阀值的方法有很多。本次采用加权平均方法找阈值,即是找期望值。代码如下图所示。
结果如下:
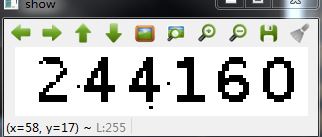
4.3 字符连续性
这一步的目的是有些字符颜色特别浅,导致二值化后的图像在纵横方向上有间断点,即使对角线上存在领域,在去噪声或字符分割过程中会达不到预期的效果。这里可以采用卷积方式,如下如所示。

还有另外一种方式,原理与实现更加简单,当检测到只有对角线领域连续时,补全纵横像素。该方式只适合特定的场合,本次实验采取这种方式。代码如下:

结果如下:
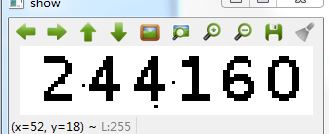
4.4 噪声处理
常见的降噪算法一般都是一些滤波算法——均值滤波、中值滤波、自适应维纳滤波器和小波滤波等。降噪是一个技术难点。降噪篇幅比较大。网上也有很多介绍,我给出的源代码中也提供了两种方式降噪。
结果如下:
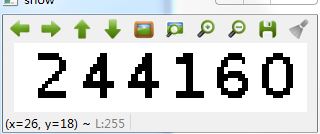
4.5 字符分割
字符分割网上最常用的方法是泛水填充法,对于相互之间没有粘连的字符验证码,直接对图片进行扫描,遇到一个黑的pixel就对其进行泛水填充,所有与其连通的字符都被标记出来,因此一个独立的字符就能够找到了。这个方法优点是效率高,时间复杂度是O(N),N为像素的个数;而且不用考虑图片的大小、相邻字符间隔以及字符在图片中得位置等其他任何因素,任何验证码图片只要字符相互是独立的,不需要对其他任何阀值做预处理,直接就操作;用这种方法分割正确率非常高,几乎不会出现分割错误的情况。具体实现方法看源代码。
结果如下:

4.6 旋转缩放
旋转倾斜的目的就是要提高识别的正确率,如果字符‘A’的模板是标准的,让一个横着的‘A’去训练肯定得不到正确的结果。不过怎么旋转呢?想要将每个字符都旋转到印刷体的角度那是很难的,也是不必要的,在这里采用的思想就是每次都旋转成为“最瘦的”。每次分割出来一个字符不管是横着的还是竖着的,都可以回到“最瘦”的角度。代码如下所示。

由于验证码大小不一,图片上又大量背景像素,因此在进行最后一步识别的时候,还应该将验证码的大小缩放到固定的大小。将所有的字符都统一缩放到1616的大小,这样最终得到的经过预处理的标准字符就可以开始训练识别了。缩放代码如下所示。

4.7 提取特征值
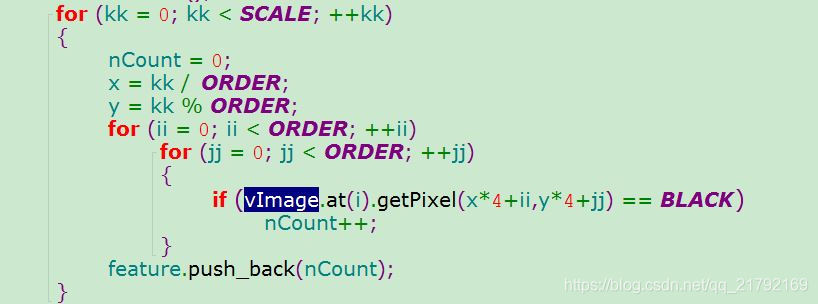
仅仅针对字符验证码可以采用像素统计方式提取特征。将16*16的字符等分为16份,统计每一份中像素为255的个数,那么一个字符的特征值就可以采用16个数字表示。代码实现如下:
4.8 训练
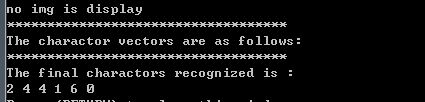
训练采用opencv库中的svm,3.x版本svm支持向量机。具体代码可以参考源工程代码,待训练的图片应该以图片中的实际值为文件名,用来做训练,只需要手动修改20个左右的原图片即可,后面的修改全部由软件完成。训练识别结果如下。
验证码文件如下:

本次实验有5000个验证码,识别率为100%。
CSDN下载链接:https://download.csdn.net/download/qq_21792169/10918821
Github下载地址:https://github.com/HeroKern/image_ident.git