行为识别阅读笔记:ActionRecognition using Visual Attention
http://shikharsharma.com/projects/action-recognition-attention/
这篇文章是发表在ICLR2016上的一篇文章,从文章给出的多个数据集上的测试结果来看,效果一般,远不如双流法。但该篇文章创新之处在于将attention mechanism的思想引入actionrecognition中,思路算是比较简单,但是具有一定的启发意义。人在看东西的时候,目光沿感兴趣的地方移动,甚至仔细盯着部分细节看,然后再得到结论。Attention就是在网络中加入关注区域的移动、缩放机制,连续部分信息的序列化输入。采用attention使用时间很深的lstm模型,学习视屏的关键运动部位.
文章算法框架如下:


其中,第一项是带有时间维的交叉熵损失函数,第二项是对attention的惩罚项,第三项是对所有模型参数的权重衰减。实验证明, 时效果最好,attention能更好的关注一些特定的运动区域,而不是全图。
实验效果
http://shikharsharma.com/projects/action-recognition-attention/
attention mechanism:
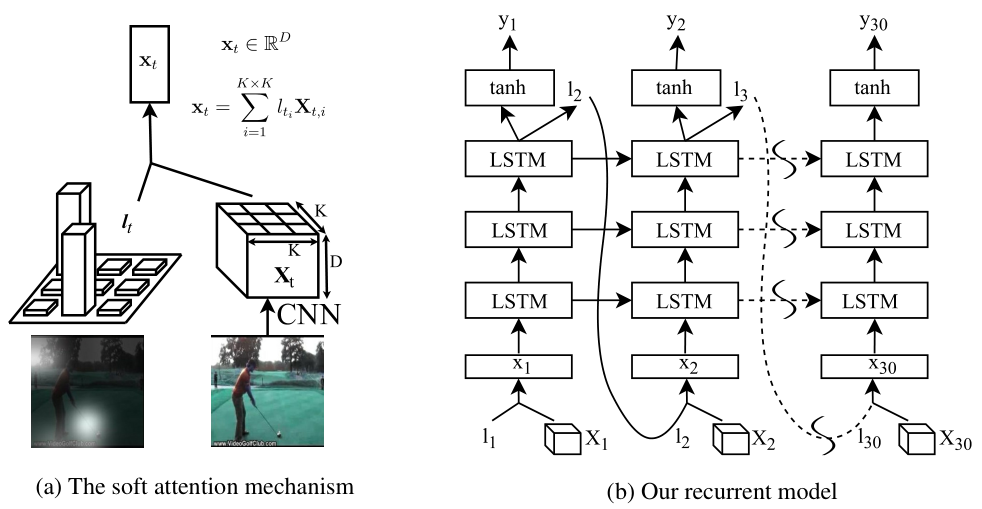
Attention的思想是将目标作进一步refined,让模型可以捕获更精细的特征,是通过将特征分成更小的patch,Attention将筛选出更有利于描述特征的那部分patch。Attention可以分为soft-attention和hard-attention两种。
Soft attention模型是deterministic, 可以使用BP训练,而hard attention模型是stochastic,可以使用强化学习训练。
Softattention:假如我们的输入是8*8*1024的特征向量,我们可以将8*8的特征分成4个4*4的或是16个2*2的或是64个1*1等等的patch。不同尺度patch的大小可以根据具体要求来。之后将patch送入softmax进行打分。此处的softmax函数是包含可学习参数的:
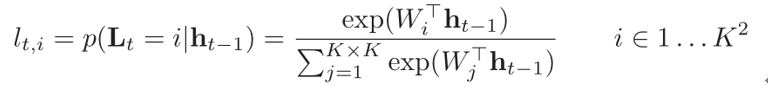
其实这个可以理解为softmax 回归。