分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
凌晨一点半的深圳雨夜: 
豪雨当夜惊起有人赏,笑叹落花无声空飘零。
喜欢这种豪雨,让人兴奋。惊起作文以呜呼之感叹!
引用上一篇文章:
优化多核CPU的TCP新建连接性能–重排spinlock:https://blog.csdn.net/dog250/article/details/80575731
在这篇文章中,我将一个spinlock拆解成了per cpu的,然而并没有提及spinlock本身的性能和可伸缩性(scalable),那么本文就来说一下。
一点说明
正文开始之前,先给出本文讨论的各个场景基于的CPU布局图,本文中我们将描述很多的场景实验,因为是分析原理,我将其定义为思想实验,假设我们思想实验的系统拥有16核CPU,其中每一个CPU封装有2个物理核,每一个物理核有两个有独立cache的核心,其布局如下:
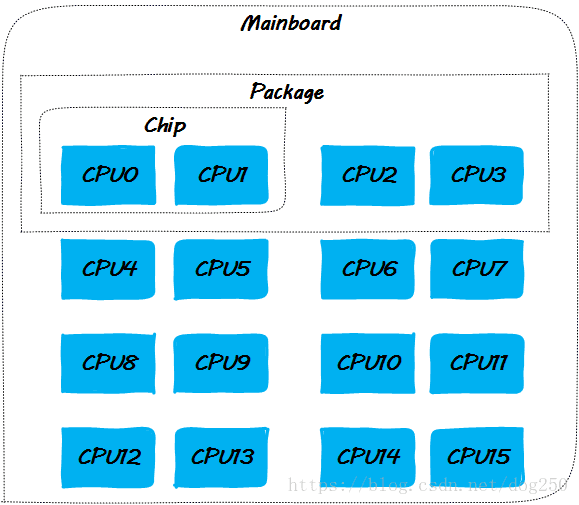
由于实现的可扩展性的原因,当前的大多数平台在实现CPU cache一致性协议时有两个选择,一个是snoopy,一个是点对点unicast。
- snoopy方式
这意味着cache一致性消息通过总线广播,于是就要侦听总线以在某个时机获得控制权。这种方式及其不易扩展,在CPU数目达到一定量时,总线的争抢会很严重。
参考以太网的CSMA/CD协议,会得出一样的结论,正如CSMA/CD的基于总线的以太网由于其不可扩展性进化到了交换式以太网一样,CPU间的cache一致性协议的点对点unicast实现方式最终替代了snoopy(小规模本地cache一致性依然会采用snoopy的方式)。总而言之,是总线带宽限制了snoopy想大规模SMP发展。 - 点对点unicast方式
既然snoopy需要严格的总线仲裁,采用点对点的方式进行cache一致性的消息路由就成了一个可选的应对措施,但是对于多个目的地的消息的发送方而言,one by one的按序in turn方式发送就成了唯一的选择,正是这种处理方式成了点对点unicast方式的另一个不可扩展性根源。
但这种不可扩展性是针对更上层而言,在cache一致性协议的实现上,它克服了总线仲裁带来的本层的不可扩展性。业界很多的场景都遵循了类似的总线–>点对点的发展轨迹,除了以太网之外,还有PCI到PCIe的进化。无论哪种实现方式,其过程都体现了采用被动的NAK仲裁向主动的消息路由方向的进化之路似乎是一条放之四海而皆准的康庄大道。
理解这些,特别是理解点对点unicast方式的one by one处理时延会随着CPU核数的增加而线性增加为后面的内容埋下了伏笔。
在Linux内核中,先后有过新旧两种版本的自旋锁被大规模使用,一个是willd spinlock,另一个则是当前内核默认使用的ticket spinlock,下面的章节会简而述之。
好了,正文开始!
wild spinlock
这种自旋锁非常简单,简而言之就是一个整数:
typedef struct { volatile unsigned int lock;} spinlock_t;
- 1
- 2
- 3
然后其加锁和解锁过程为:
void spin_lock(spinlock_t *lock){ while (lock->lock == 1) ; // 自旋等待}void spin_unlock(spinlock_t *lock){ lock->lock = 0;}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
然而在这种简单的背后却掩盖着一个血雨腥风的战场,我们看一下why。
根据上面的CPU布局图,我们可以了解到CPU之间的亲密关系是不同的,特定CPU的cache line更新同步到不同CPU的cache line的时间也不同,这就意味着等待自旋锁的CPU中哪个CPU先感知到lock->lock的变化,哪个就能优先获得锁。
这将大大有损等锁者之间的公平性。这就好比一群人不排队上火车,体格好的总是优先登车一样。
为了解决这个公平性问题,ticket spinlock登场了。
ticket spinlock登场
ticket spinlock在设计上增加了一个等锁期间单调递增的ticket字段(当然,在实现上如何体现这个ticket就是trick了),确保了先到者先获得锁,从而保证了公平性。
Linux ticket spinlock的实现和执行过程
我先给出Linux ticket spinlock的伪代码实现,为了讨论简单,以下的代码中所有的自加(i++)操作均为原子操作,避免锁中锁。
- 定义spinlock
struct spinlock_t { // 上锁者自己的排队号 int my_ticket; // 当前叫号 int curr_ticket;}
- 1
- 2
- 3
- 4
- 5
- 6
非常简单,一个标准的排队装置,类似银行叫号系统,每个办理业务的取一个号,然后按照号码的大小依次串行被服务。
- spin_lock上锁
void spin_lock(spinlock_t *lock){ int my_ticket; // 顺位拿到自己的ticket号码; my_ticket = lock->my_ticket++; while (my_ticket != lock->curr_ticket) ; // 自旋等待!}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- spin_unlock解锁
void spin_unlock(spinlock_t *lock){ // 呼叫下一位! lock->curr_ticket++;}
- 1
- 2
- 3
- 4
- 5
以上基本就是Linux ticket spinlock实现的全部了,没什么复杂的,没什么大不了的。如果说仅仅是为了读懂代码,确实没有什么大不了的,然而深究起来却可以发现它的不妙。
以下我就从cache的角度来分析一下这个自旋锁的执行过程,以下面的代码片段为例:
void demo(){ spin_lock(&g_lock); g_var1 ++; g_var2 --; g_var3 = g_var1 + g_var2; spin_unlock(&g_lock)}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
依然是按步骤来。好了,开始我们的步骤。
- step 1:CPU0申请锁,获取本地ticket到申请者的CPU cache
- step 2:执行锁定区域指令的同时,其它CPU企图获取锁而自旋
- step 3:CPU0释放锁

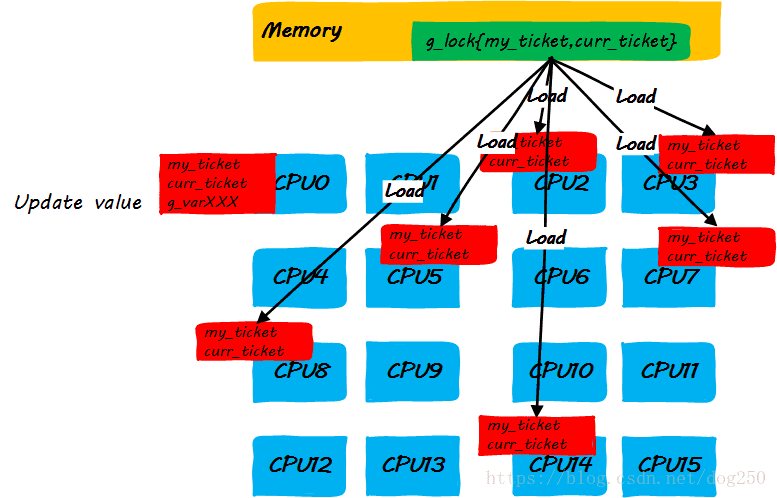
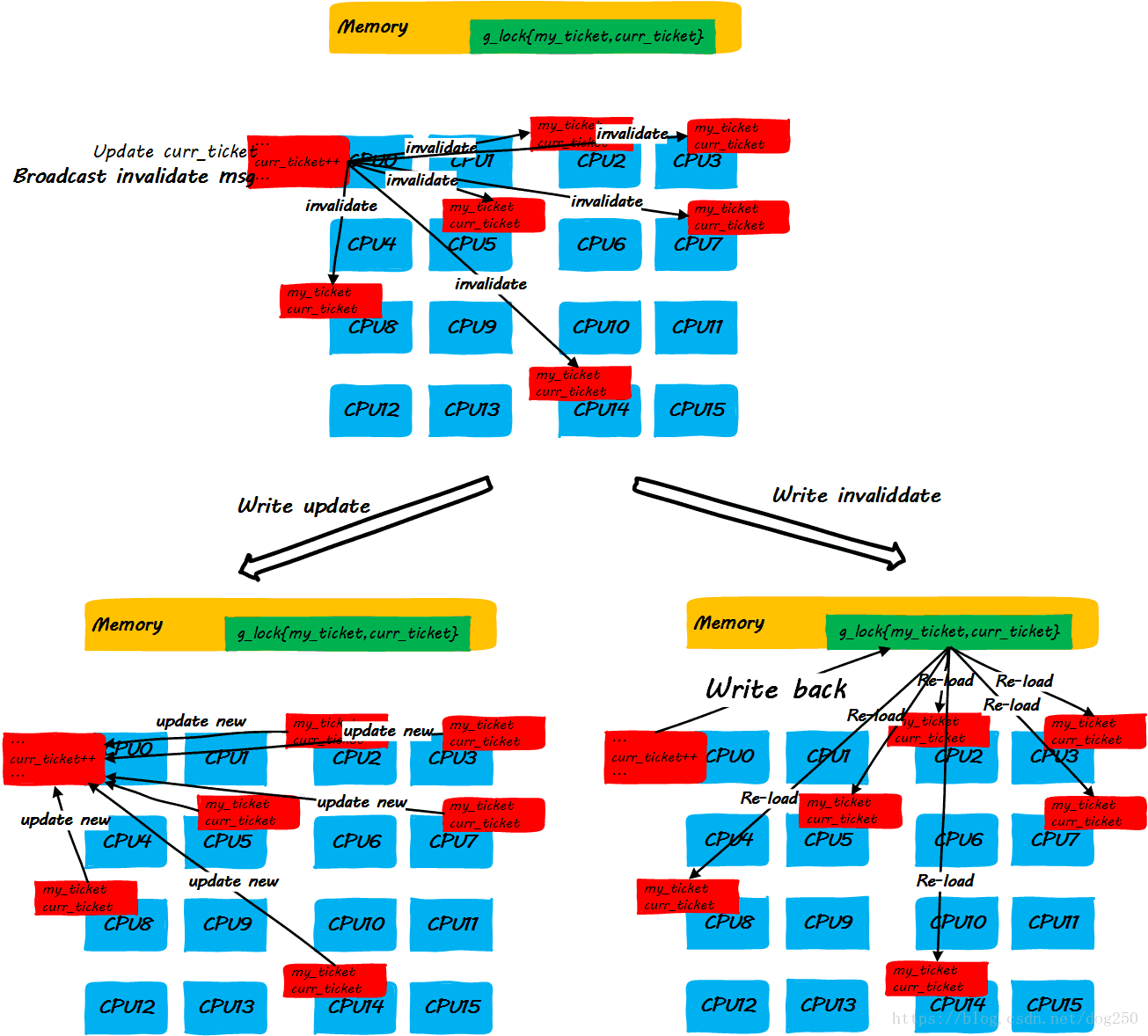
我们发现,上述的step3中的步骤有点太复杂了。当前的大多数平台倾向于用点对点unicast的方式来更新cache line(因为broadcast方式对总线带宽有要求,随着CPU核数的增加,实现复杂度会增加,这是另一种不可伸缩!),因此step3中更新每一个CPU cache line是一个one by one的过程,如果是write invalidate方式,就更会多出超级多的访存指令,这些对于理解Linux ticket spinlock的不可伸缩性至关重要!
很显然,随着CPU核数的增加,随着spinlock申请者的增加,step3中动作的执行时间会线性增加,最终,当spinlock的申请者达到一定数量时,多核CPU非但没有提高性能,反而由于cache line更新的时间过久,反过来损害性能。
注意,wild spinlock同样存在这个问题,wild spinlock背后的cache一致性过程和ticket spinlock完全一致,只是ticket spinlock严格限定了谁将下一个获得锁而wild spinlock并不能。
我们已经定性地描述了Linux ticket spinlock的当前实现会有什么问题,为了定量地衡量这种实现会带来哪些具体的后果,我需要简单说一下Linux ticket spinlock(此后简称Linux spinlock)经典的Markov chain模型,请看下节。
Linux spinlock的马尔科夫链模型
为了阐释Linux spinlock的具体性能表现和带来的结果,必然需要建立一个模型,本节我就说一下Linux spinlock的Markov chain模型,该模型结合排队论可以精确描述和预测Linux spinlock的行为。
先看一下图示: 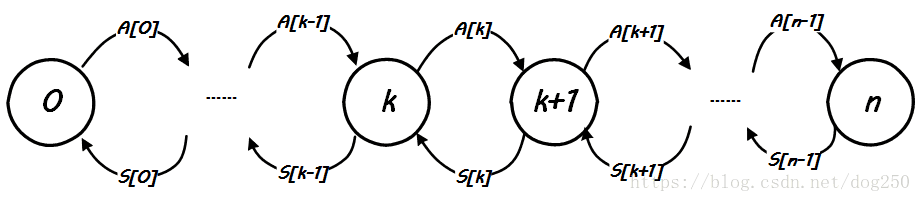
解释一下:
这是一个Markov chain,其中一共有0了,而它也要作为一个和CPU核数相关的量参与到模型的构建中了。
不多说。
后记
凌晨3点半。豪雨继续中…
黑云压顶白珠跳,浙江温州皮鞋湿。
给我老师的人工智能教程打call!http://blog.csdn.net/jiangjunshow
