编程语言的基元类型
编译器直接支持的数据类型称为基元类型(primitive type)。基元类型直接映射到framework类型(fcl)中存在的类型。
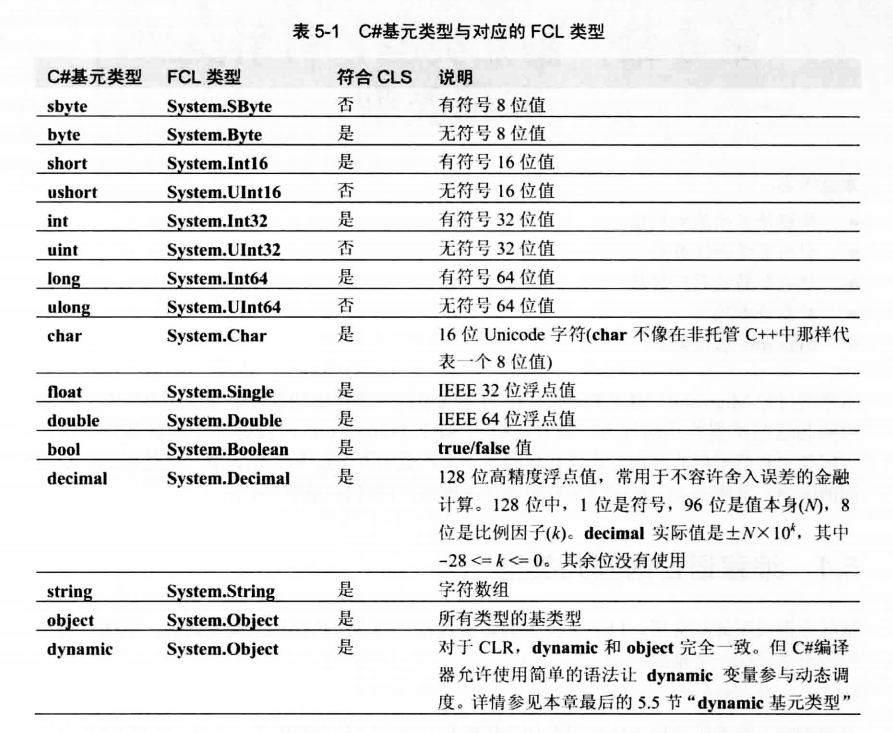
下表列出fcl类型
从另一个角度,可以认为C#编译器自动假定所有源代码文件都添加了一下using指令:

c#编译器非常熟悉基元类型,会在编译代码时应用自己的特殊规则,具体地说,c#编译器支持与类型转换、字面值以及操作符有关的模式。
Int32 i = 5; Int64 l = i; //从int32隐式转换为int64 Single s = i; //从int32隐式转换为single byte b = (byte) i; //从int32显式转换为byte Int16 v = (Int16)s; //从Single显式转换为Int16
只有在转换“安全”的时候,c#才允许隐式转换。所谓的“安全”,是指不会发生数据丢失的情况,比如从int32转换为int64。但如果可能不安全,c#就要求显式转型。对于数值类型,“不安全”意味着转换可能丢失精度或数量级。
checked和unchecked基元类型操作
对基元类型执行的许多算术运算都可能造成溢出。溢出大多数时候是我们不希望的,如果没有检测到溢出,会导致应用程序行为失常。但极少数时候(比如计算哈希值或者校验和),这种溢出不仅可以接受,还是我们希望的。
不同语言处理溢出方式不同。C和C++不将溢出视为错误,允许值回滚。想反,visual basic总是将溢出视为错误。clr提供了一些特殊的il指令,允许编译器选择它认为最恰当的行为。
c#编译器有一个checked+开关,指示生成代码时,是否检测溢出。
程序员还可在代码的特定区域控制溢出检查。c#通过checked和unchecked操作符来提供这种灵活性,如下。
UInt32 invalid= unchecked ((UInt32)(-1));//ok 下例则使用了checked操作符 Byte b=100; b=checked((byte)(b+200));//抛出异常
引用类型和值类型
CLR支持两种类型:引用类型和值类型。引用类型总是从托管堆分配,c#的new 操作符返回对象内存地址—即指向对象数据的内存地址。使用引用类型必须留意性能问题。首先要认清以下4个事实。
1、 内存必须从托管堆分配。
2、 堆上分配的每个对象都有一些额外成员,这些成员必须初始化。
3、 对象中的其他字节(为字段而设)总是设为零。
4、 从托管堆分配对象时,可能强制执行一次垃圾回收。
如果所有类型都是引用类型,应用程序的性能将显著下降。设想每次使用int32值时都进行一次内存分配,性能会受到多么大的影响!为了提升简单和常用的类型的性能,clr提供了名为“值类型”的轻量级类型。值类型的实例一般在线程栈上分配(虽然也可以作为字段签入引用类型的对象中)。在代表值类型实例的变量中不包含指向实例的指针。相反,变量中包含了实例本身的字段。由于变量已包含了实例的字段,所以操作实例中的字段不需要提领指针。值类型的实例不受垃圾回收期的空值。因此,值类型的使用缓解了托管堆的压力,并减少了应用程序生命周期内的垃圾回收次数。
进一步研究文档,会发现所有结构都是抽象类型system.ValueType的直接派生类。system.ValueType本身又直接从system.Object派生。根据定义,所有值类型都从system.ValueType派生。所有枚举都从system.enum抽象类型派生,后者又从system.ValueType派生。
虽然不能再定义值类型时为它选择基类型,但是如果愿意,值类型可实现一个或多个接口。除此之外,所有值类型都隐式密封,目的是防止将值类型用作其他引用类型或者值类型的基类型。
设计自己的类型时,要仔细考虑类型是否应该定义成值类型而不是引用类型。值类型有时能提供更好的性能。具体地说,除非满足以下全部条件,否则不应将类型声明为值类型。
1 类型具有基元类型的行为。也就是说,是十分简单的类型,没有成员会修改类型的任何实例字段。如果类型没有提供会更高其字段的成员,就说该类型是不可变(immutable)类型。事实上,对于许多值类型,我们都建议将全部字段标记为readonly。
2 类型不需要从其他任何类型继承。
3类型也不派生出其他任何类型。
类型实例的大小也应该考虑,因为实参默认以传值方式传递,造成对值类型实例中的字段进行复制,对性能造成损害。同样地,被定义为返回一个值类型的方法在返回时,实例中的字段会复制到调用者分配的内存中,对性能造成损害。
4 类型的实例较小(16字节或更小)
5 类型的实例较大(大于16字节),但不作为方法实参传递,也不从方法返回。
值类型的装箱和拆箱
//声明值类型 struct Point{ public Int32 x,y; } public sealed class Program{ public static void Main(){ ArrayList a=new ArrayList(); Point p; for (int i = 0; i < 10; i++) { p.x = p.y = i; a.Add(p);//对值类型装箱,将引用添加到ArrayList中 } } }
每次循环迭代都初始化一个Point的值类型字段,并将该Point存储到ArrayList中。但思考一下,ArrayList
中究竟存储了什么?首先我们看ArrayList的Add方法
public virtual Int32 Add(object value);
可以看出Add获取的是一个Object参数。也就是说,Add获取托管堆上的一个对象的引用来作为参数。但point是值类型,为了使代码正确工作,point值类型必须转换成真正的、在堆中托管的对象,而且必须获取对该对象的引用。
将值类型转换成引用类型要使用装箱机制。下面总结了对值类型的实例进行装箱所发生的事情。
1 在托管堆中分配内存。分配的内存量是值类型各字段所需的内存量,还要加上托管堆所有对象都有的两个额外成员(类型对象指针和同步索引块)所需的内存量。
2 值类型的字段复制到新分配的堆内存
3 返回对象地址。现在该地址是对象引用:值类型成了引用类型。
c#编译器自动生成对值类型实例进行装箱所需的IL代码,但仍需要理解内部发生的事情,才能体会到代码的大小和性能。
知道装箱如何进行后,接着谈谈拆箱。假定要用以下代码获取获取ArrayList的第一个元素:
Point p=( Point)a[0];
他获取ArrayList的元素0包含的引用(或指针),试图将其放到Point值类型的实例p中。为此,已装箱Point对象中的所有字段都必须复制到值类型变量p中,后者在线程栈上。CLR分两步完成复制。第一步获取已装箱Point对账中的各个point字段的地址。这个过程称为拆箱(unboxing)。第二部将字段包含的值从堆复制到基于栈的值类型实例中。
拆箱不是直接将装箱过程倒过来,拆箱的代价比装箱低得多。拆箱其实就是获取指针的过程,该指针指向包含在一个对象中的原始值类型。
未装箱值类型比引用类型更“轻”。这要归结于以下两个原因
1 不再托管堆上分配
2 没有堆上的每个对象都有的额外成员“类型对象指针”和“同步块索引”。
由于未装箱值类型没有同步块索引,所以不能使用System.Threading.Monitor类型的方法让多个线程同步对实例的访问。
虽然未装箱值类型没有类型对象指针,当仍可调用由类型继承或重写的虚方法(比如equals,gethashcode或者tostring)。如果值类型重写了其中任何虚方法,那么clr可以非虚地调用该方法,因为值类型隐式密封,不可能有类型从它们派生,而且调用虚方法的值类型实例没有装修。然而,,如果重写的虚方法要调用方法在基类中的实现,那么在调用基类的实现时,值类型实例会装修,以便能够通过this指针将一个堆对象的引用传给基方法。
但在调用非虚的、继承的方法时(比如getType或MemberwiseClone),无论如何都要对值类型进行装箱。因为这些方法由system.object定义,要求this实参是指向堆对象的指针。
此外,将值类型的未装箱实例转型为类型的某个接口时要对实例进行装箱。这是因为接口变量必须包含对堆对象的引用,一下代码对此进行了演示
using system; internal struct Point :IComparable{ private Int32 m_x,m_y; //构造器负责初始化字段 public Point(Int32 x,Int32 y) { m_x=x; m_y=y; } //重写tostring方法 }
调用Tostring
由于Point重写了tostring方法,所以Jit编译器会生成代码直接调用(非虚地)tostring方法,而不必进行任何装箱操作,编译器知道这里不存在多态性问题,因为point是值类型,没有类型能从它派生以提供虚方法的另一个实现。但假如point的tostring方法在内部调用base.tostring(),值类型的实例会被装箱。
调用GetType
调用非虚方法GetType时必须装箱。Point的GetType方法是从system.object基继承的。
对象相等性和同一性
system.object类型提供了名为equals的虚方法,作用是在两个对象包含相同值的前提下返回true。Object的Equals方法是像下面这样实现的
public class Object{ public virtual Boolean Equals(){ //如果两个引用指向同一个对象,他们肯定包含相同的值 if(this==obj) return true; return false; } }
乍一看,这似乎就是equals的合理实现,但是对object的equals方法的默认实现,实际上只验证了同一性(identity),而非相等性(equality)。
由于类型能重写object的equals方法,所以不能再用它测试同一性。为了解决这个问题,object提供了静态方法referenceEquals。
顺便说一下,system.valueType(所有值类型的基类)就重写了Object的Equals方法,并进行了正确的实现来执行值的相同性检验。valueType的equals内部是这样实现的
1 如果obj实参为null,就返回false。
2 如果this和obj实参引用不同类型的对象,就返回false。
3 针对类型定义的每个实例字段,都将this对象中的值与obj对象中的值进行比较(通过调用字段的equals方法)。任何字段不相等,就返回false。
5 返回true。valueType的equals方法不调用object的equals方法。
其中,利用了反射实现步骤3
对象哈希码
fcl的设计者认为,如果将任何对象的任何实例放到哈希集合集合很重,能带来很多好处。为此,system.object提供了虚方法getHashCode,它能获取任意对象的int32哈希码。
如果你定义的类型重写了Equals方法,还应重写GetHashCode方法。事实上,如果类型重写Equals的同时没有重写GetHashCode,编译器会生成一条警告。类型定义Equals之所以还要定义GetHashCode,是由于system.collections.Hashtable类型、system.collections.Generic.Dictionary类型以及其他一些集合的实现中,要求两个对象必须具有相同哈希码才被视为相对。所以,重写Equals就必须重写GetHashCode,确保相等性算法和对象哈希码算法一致。
简单地说,向集合添加键值对,首先要获取键对象的哈希码。该哈希码指出键值对要存储到哪个哈希桶(bucket)中。集合需要查找键时,会获取指定键对象的哈希码。该哈希码标识了现在要以顺序方式搜索的哈希桶,将在其中查找与指定键对象相等的键对象。采用这个算法来存储和查找键,意味着一旦修改了集合中的一个键对象,集合就再也找不到该对象。所以,需要修改哈希表中的键对象时,正确做法是移除原来的键值对,修改键对象,再将新的键值对添加回哈希表。
自定义GetHashCode方法或许不是一件难事。但取决于数据类型和数据分布情况,可能并不容易设计出能返回良好分布值的哈希算法。下面是一个简单的哈希算法,它用于Point对象时还不错
internal sealed class Point{ private readonly Int32 m_x,m_y; public override Int32 GetHashCode(){ return m_x^m_y; //返回m_x和m_y的xor结果 } }
选择算法来计算类型实例的哈希码时,请遵守以下规则
1 这个算法要提供良好的随机分布,使哈希表获得最佳性能。
2 可在算法中调用基类的GetHashCode方法,并包含它的返回值。但一般不要调用Object或ValueType的GetHashCode方法,因为两者的实现都与高性能哈希算法不沾边。
3 算法至少使用一个实例字段
4 理想情况下,算法使用的字段应该不可变;也就是说,字段应在对象构造时初始化,在对象的生存期不改变。
5 算法执行速度尽量快
6 包含相同值的不同对象应返回相同哈希码。例如,包含相同文本的两个string对象应返回相同哈希码。
system.object实现的GetHashCode方法对派生类型和其中的字段一无所知,所以返回一个在对象生存期保证不变的编号。
dynamic基元类型
c#是类型安全的编程语言。意味着所有表达式都解析成类型的实例,编译器生成的代码只执行对该类型有效的操作。和非类型安全的语言相比,类型安全的语言优势在于:程序员会犯的许多错误都能在编译时检测到,确保代码在尝试执行前是正确的。此外,能编译出更小、更快的代码,因为能在编译时进行更多预设,并在生成il和元数据中落实预设。
但程序许多时候仍处理一些运行时才会知晓的信息。虽然可用类型安全的语言(c#)和这些信息交互,但语法就会比较笨拙,尤其是在设计大量字符串处理的时候。
为了方便开发人员使用反射与其他组件通信,c# 编译器允许将表达式的类型标记为dynamic。还可将表达式的结果放到变量中,并将变量类型标记为dynamic。代码使用dynamic表达式/变量调用成员时,编译器生成特殊il代码来描述所需操作。这种特殊的代码称为payload(有效载荷)。在运行时,payload代码根据dynamic表达式、变量引用的对象的实际类型来决定具体执行的操作。
C#内建的动态求值功能所产生的额外开销不容忽视。虽然能用动态功能简化语法,但也要看是否值得。