文章目录
1 Pascal VOC 数据集简介
1.1 概要
图像分类和目标检测顶会论文的实验部分总是可以看到基于Pascal VOC数据集的算法结果分析,它为图像分类、目标检测和图像分割都提供了优秀的数据支撑,2005年到2012年每年还举办相应的竞赛。Pascal VOC2005只有4个类别bicycles, cars, motorbikes, people,个人见的比较多的VOC2007和VOC2012发展到了20个类别。详细介绍请移步Pascal VOC官网。
1.2 数据集格式
本文以Pascal VOC2007为例,可以点击VOC2007 下载对应的数据集,各数据集的下载链接如下表,其余版本请移步Pascal VOC官网。
| 数据集版本 | 官网链接 | 百度云链接 |
|---|---|---|
| voc2007 | VOC2007 | |
| voc2012 | VOC2012 |
1.2.1 整体框架
下载解压之后,可以看到VOC2007的文件树如下图所示:
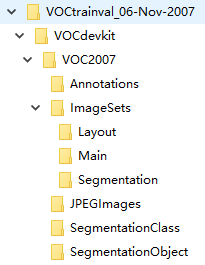
在VOC2007文件夹下面有5个文件夹Annotations,ImageSets,JPEGImages,SegmentationClass,SegmentationObject
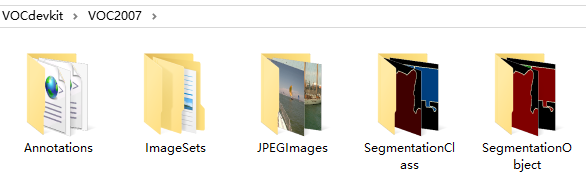
其中后面的两个SegmentationClass,SegmentationObject是针对图像分割任务的,这里不做讨论。
1.2.2 Annotations
Annotations文件夹里是*.xml文件,xml文件里存放的是图像的文件信息。

1.2.2.1 xml文件内容
<annotation>
<folder>VOC2007</folder> # 图片所在文件夹
<filename>000005.jpg</filename># 图片名字
<source>
<database>The VOC2007 Database</database># 所属数据集
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>325991873</flickrid>
</source>
<owner>
<flickrid>archintent louisville</flickrid>
<name>?</name>
</owner>
# 自此处开始是特别重要的核心信息
<size># 图片尺寸信息
<width>500</width># 宽度
<height>375</height> #高度
<depth>3</depth>#通道数
</size>
<segmented>0</segmented>
# 下面是图片中被框出来的物体信息,每个<object></object>代表了一个物体。
<object>
<name>chair</name># 物体类别名称
<pose>Rear</pose>
<truncated>0</truncated># 物体被框出来时是否被截断,意思是框出来的是不是只是物体的一部分,如果没有被截断,该处值是0
<difficult>0</difficult># 该物体检测出的难度是不是困难级别
<bndbox># 最重要 物体在图像中所处的坐标信息
<xmin>263</xmin># 左上角
<ymin>211</ymin>#左上角
<xmax>324</xmax># 右下角
<ymax>339</ymax># 右下角
</bndbox>
</object># 自此,一个物体的信息描述完毕,接下来是另一个物体信息,如果还有下一个的话。
<object>
<name>chair</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>165</xmin>
<ymin>264</ymin>
<xmax>253</xmax>
<ymax>372</ymax>
</bndbox>
</object>
........
</annotation>
1.2.3 JPEGImages
JPEGImages文件夹中存放原始图片,一般格式为.jpg。

1.2.4 ImageSets
ImageSets文件夹下本次讨论的只有Main文件夹,此文件夹中存放的主要又有四个文本文件-test.txt,train.txt,trainval.txt,val.txt,其中分别存放的是测试集图片的文件名、训练集图片的文件名、训练验证集图片的文件名、验证集图片的文件名。

2 动手制作
制作VOC数据集的过程就是生成上述三个文件夹的过程。仿照标准VOC数据集,先构建框架如下图所示的数据集框架。
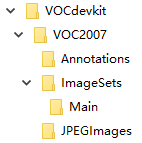
笔者课程作业是枪支检测,接下来就以枪支数据集的制作来介绍。
2.1 JPEGImages
首先找图片,数据集中占比最大最优先的是图像。可以手动从网上另存为,也可以用爬虫去爬,或者其他手段。待准备好一堆图片之后,使用脚本给他们按照0x6d.jpg的格式重命名。
# -*- coding: utf-8 -*-
# @Time : 2018/11/10 11:59
# @Author : jcliu
# @File : rename_images.py
import cv2 as cv
import os
# ==================可能需要修改的地方=====================================#
g_root_path = "E:/Pycharm/try_my_dataset_proj/datas"
os.chdir(g_root_path) # 更改工作路径到图片根目录
org_path = "org/" # 原图片目录
dst_path = "rename/" # 目标图片目录
img_cnt = 5000 # 图片的起始名字,这里是‘005000.jpg’
# ==================================================================#
file_list = os.listdir(org_path)
if os.path.exists(dst_path) is False:
os.makedirs(dst_path)
for idx, file in enumerate(file_list):
img = cv.imread(org_path + file)
# img=cv.resize(img,(512,512))
img_name = os.path.join(dst_path, "%06d.jpg" % img_cnt)
cv.imwrite(img_name, img)
img_cnt += 1

2.1 Annotations
标注信息的生成需要借助 labelImg工具,官网下载不了,戳这里密码 t2r8。
2.1.1安装启动labelImg
下载好之后解压,首先打开data/predefined_classes.txt,全部删除之后加上我们要得类别名称,如gun。
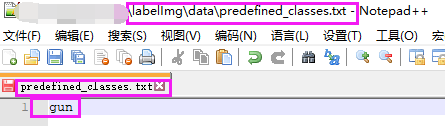
点labelImg.exe,启动软件。如果出现闪退,戳labelImg闪退解决方案

2.1.2 打开要标注的图片目录
点击左侧第二个 Open Dir按钮,选择刚才生成好的图片目录。


2.1.3 标注
在英文输入法模式下,按下W,就可以选择标注区域了,用鼠标拖动,把要检测的类别标注出来,然后选择类别。


所有物体都标注结束,Ctrl+S保存,然后D或者左边的Next Image框下张图片。

一通操作之后便得到了图片的标注信息*.xml,现在把这些xml文件放到Annotations文件夹下。

2.3 ImageSets
简单运行下面的脚本即可。
# -*- coding: utf-8 -*-
# @Time : 2018/11/12 13:03
# @Author : jcliu
# @File : xml2voc.py
import os
import random
# ==================可能需要修改的地方=====================================#
g_root_path = "D:/VOCdevkit/VOC2007/"
xmlfilepath = "Annotations" # 标注文件存放路径
saveBasePath = "ImageSets/Main/" # ImageSets信息生成路径
trainval_percent = 0.98
train_percent = 0.98
# ==================可能需要修改的地方=====================================#
os.chdir(g_root_path)
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
xml_list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(xml_list, tv)
train = random.sample(trainval, tr)
print("train and val size", tv)
print("train size", tr)
ftrainval = open(saveBasePath + "trainval.txt", "w")
ftest = open(saveBasePath + "test.txt", "w")
ftrain = open(saveBasePath + "train.txt", "w")
fval = open(saveBasePath + "val.txt", "w")
for i in xml_list:
name = total_xml[i][:-4] + "\n"
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
现在,自己的VOC数据集制作完毕,可以在任何可以使用官方VOC数据集的场合下(图像分割除外)使用当前数据集了。