我们在Jenkins Pipeline的高效使用 中介绍了JenkinsPipeline的原理和简单的实现方式,本篇我将结合我工作中的案例详细讲解JenkinsPipeline如何对现有的Jenkins脚本做抽象和优化。
先看效果图:
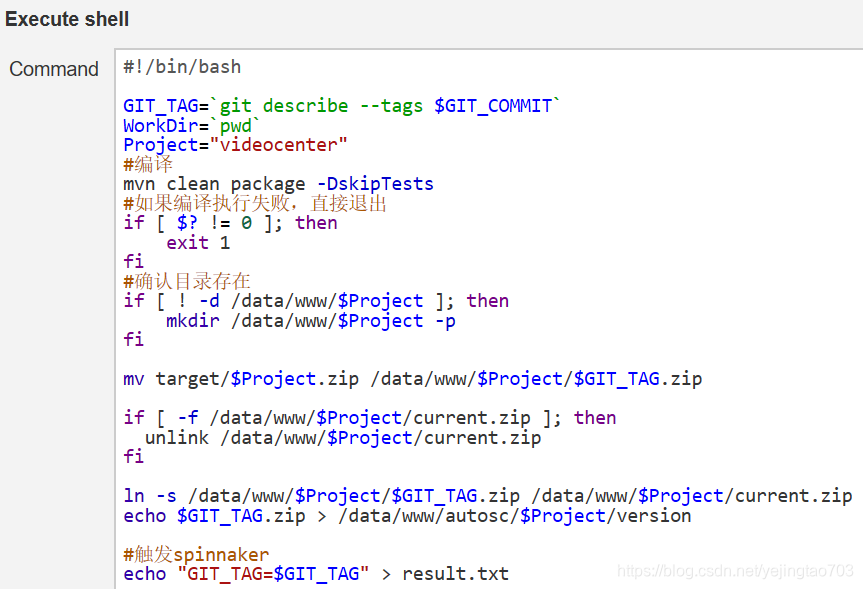
改造前:
改造后:

很直观的可以看到Jenkins任务由复杂的脚本变成了简单的传参,后续再有新的项目接入Jenkins将会简单很多。
我原来Jenkins任务想做的事情:
1 获取到git的tag信息
2 执行mvn命令
3 /data/www/$Project这里是我的交互仓库,保证仓库目录存在
4 将编译好的交付物上传到交付仓库,因为我的交互仓库与Jenkins服务在一起,所以省去了网络传递的过程,直接mv
5 将最新的交付物创建一个current.zip的链接,可以认为是快捷方式
6 /data/www/autosc/$Project/version中维护最新的版本信息
7 最后触发下一个spinnaker的CD环节
改造中的困难:
整个Jenkins任务相对还算简单,但是抽象成Jenkins Pipeline的时候为了兼容现有的任务人为的制造了很多的麻烦。
1 project项目名:
按道理说应该与gitlab中的保持一致,但是现有的情况是有的场景非要在Jenkins中重命名了project项目名。

解决方案:我默认采用gitlab中项目名,并提供参数允许覆盖。
2 maven命令:
形形色色的都有,给了研发团队高度的自由度
mvn clean package -DskipTests
mvn install -Dmaven.test.skip=true -Pbjyg
mvn clean install
mvn clean assembly:assembly -Dmaven.test.skip=true解决方案:最灵活也是最容易实现的方式就是直接将mvn命令作为一个入参,并提供默认值。
3 交付文件不统一
大部分交付的是target/$Project.zip,有人交付target/api/$Project.zip,或者有的压根写死的文件名target/divfile.jar
同project项目名的设计,默认与gitlab中保持一致,也提供参数允许覆盖。
4 一个Gitlab项目编译多个应用
这是最头大的情况,mvn根据参数编译不同的交付物出来。
mvn install -Dmaven.test.skip=true -场景1
mv target/$Project1.zip /data/www/$Project1/$GIT_TAG.zip
mvn install -Dmaven.test.skip=true -场景2
mv target/$Project2.zip /data/www/$Project2/$GIT_TAG.zip解决方案:
对于串行的场景(一次编译出多个交付物),Trigger/call builds on other projects这个组建本身就支持串行,可以串行的触发多次公共pipeline。

对于排他的场景(一次编译出一个交付物),通过解析git中的tag内容来得知本次任务来发布哪部分内容并将相关参数传递给公共pipeline。对tag的解析我们不用自己开发,Jenkins的SVM组建也已经支持:

公共Pipeline的脚本:
入参说明:
git_url: 必填项,${GIT_URL}不要修改
git_commit: 必填项,${GIT_COMMIT}不要修改
job_name:必填项,${JOB_NAME} 不要修改
project_name:可选项,交付仓库目录中标识project那一级目录的名称,默认与gitlab中项目名一致
maven_command:可选项,maven执行命令,默认是mvn clean package
package_name:可选项,build后target目录下需要发布的包名,默认是${project_name}.zip
dir_under_autosc:可选项,/data/www/autosc下的次级目录名,默认为${project_name}
脚本:
node {
def gittag
def archiveDir
def project
def target_package
def autoscDir
stage('preparation') {
//获取project的名称
if("${params.project_name}"==""){
def url = "${params.git_url}"
project = url.substring(url.lastIndexOf('/') + 1, url.lastIndexOf('.git'))
}else{
project = "${project_name}"
}
//获取发布包名
if("${params.package_name}"!=""){
target_package = "${package_name}"
}else{
target_package = "${project}.zip"
}
//获取交付仓库目录
archiveDir = "/data/www/${project}"
//交付仓库必须存在
if(! fileExists(archiveDir)) {
sh "mkdir ${archiveDir} -p"
}
//获取gittag
dir("../${params.job_name}"){
gittag = sh(returnStdout: true, script: 'git describe --tags ${git_commit}').trim()
}
//获取autosc次级目录
if("${params.dir_under_autosc}"!=""){
autoscDir = "/data/www/autosc/${dir_under_autosc}"
}else{
autoscDir = "/data/www/autosc/${project}"
}
//autosc必须存在
if(! fileExists(autoscDir)) {
sh "mkdir ${autoscDir} -p"
}
}
dir("../${job_name}"){
stage('build') {
sh "${maven_command}"
}
stage('deploy') {
sh "mv target/${target_package} ${archiveDir}/${gittag}.zip"
}
stage('current_set') {
def linkFile = "${archiveDir}/current.zip"
if(fileExists(linkFile)) {
sh "unlink ${linkFile}"
}
sh "ln -s ${archiveDir}/${gittag}.zip ${linkFile}"
sh "echo ${gittag}.zip > ${autoscDir}/version"
}
stage('spinnaker_set') {
sh "echo GIT_TAG=${gittag} > spinnakerParameter.txt"
}
}
}这样对于新接入的业务,只要没有特殊要求的,只需要传入
git_url=${GIT_URL}
git_commit=${GIT_COMMIT}
job_name=${JOB_NAME}
这三个固定参数就满足了标准的发布流程了。
这样设计的优点:
1 发布环节统一管理,要是某一天对环节进行优化或扩展,只需要修改公共pipeline这一个Jenkins任务即可。
2 新业务接入方便快捷,比起写脚本不容易出错。
3 节省人力成本,每个项目差异性极低,1个人就可以维护好所有业务的Jenkins了。
4 图形化的大盘,视觉体验更好,可以针对性的对效率做优化。
